一种基于Conv2Former和对比学习的视频质量评价方法及装置
本发明涉及一种基于conv2former和对比学习的视频质量评价方法及装置,属于视频质量评价。
背景技术:
1、随着用户生成内容(ugc)视频在社交媒体平台上的快速增长,评估这些视频的质量变得至关重要。为了解决ugc视频质量评估的问题,需要探索和发展适用于nr-vqa(无参考视频质量评价)的新型深度学习模型和评估方法,以确保对非专业生成的视频进行准确和可靠的质量评估,从而提供更好的用户体验和满足不断增长的ugc视频需求。
2、基于自注意力机制的transformer在计算机视觉领域蓬勃发展,现有技术中将transformer应用于视频质量评价领域,并证明了注意力在vqa领域具有出色的潜力。并提出了一个端到端的无参考vqa模型,使用3d卷积网络进行特征提取,然后使用transformer进行质量回归,最后,通过全连接层回归预测视频的整体质量评分,也得到不错得结果。但是transformer不是一个轻量级框架,它通常具有大量的参数和复杂的计算结构,因此无形中增加了计算成本。
3、同时,进行nrvqa时,除了需要设计一个适用的深度学习模型外,也需要大量有标记的训练数据来支持模型的训练,但是由于标注数据需要大量的人力和时间成本的投入,因此,有研究人员开始使用自监督的方式来处理vqa任务。[3]综合利用了失真程度、失真类型和帧率的自监督信息,并将其作为先验知识,为vqa任务构建了一个新颖的自监督框架,使预训练的vqa模型具有表征更丰富和更失真敏感特征的能力。但是,设计有效的辅助任务需要领域专业知识和经验,并且需要花费大量的时间和计算资源来训练和优化多个任务模型。
技术实现思路
1、本发明的目的在于克服现有技术中的不足,提供一种基于conv2former和对比学习的视频质量评价方法及装置,利用conv2former和lstm来提取视频的时空特征,引入对比学习来对所提模型进行预训练,提升模型的质量评估性能和泛化能力。
2、为达到上述目的,本发明是采用下述技术方案实现的:
3、第一方面,本发明提供了一种基于conv2former和对比学习的视频质量评价方法,包括以下步骤:
4、获取待评价的视频;
5、对所述待评价的视频进行数据增强和分帧,得到数据增强后的视频,所述视频包括连续的帧的组合;
6、将数据增强后的视频输入训练好的视频质量评价模型中,得到预测的待评价的视频质量分数。
7、进一步的,所述视频质量评价模型包括特征提取部分和质量分数预测模块;所述特征提取部分包括空间特征提取模块和时序信息处理模块;
8、所述空间特征提取模块用于采用特征金字塔技术,提取空间特征;
9、所述时序信息处理模块用于基于提取的空间特征处理时序信息,通过自注意力机制,对不同时刻的视频帧进行加权处理,从而捕捉视频帧之间的时间关系,得到时空特征;
10、所述质量分数预测模块包括多层感知器(mlp)层,用于对时序信息处理模块输出的特征进行加权和组合,来所述时空特征表示映射为质量分数,该评分将反映视频的感知质量和视觉体验。
11、进一步的,所述空间特征提取模块为conv2former主干网络;
12、conv2former主干网络用于对每个视频帧进行卷积操作,并在每个卷积层输出一组空间特征,该空间特征表示了不同层次和抽象程度的图像信息;
13、采用特征金字塔技术,从主干网络得到的不同层级的空间特征被用于生成多尺度特征。
14、进一步的,所述时序信息处理模块为attention-lstm模型;
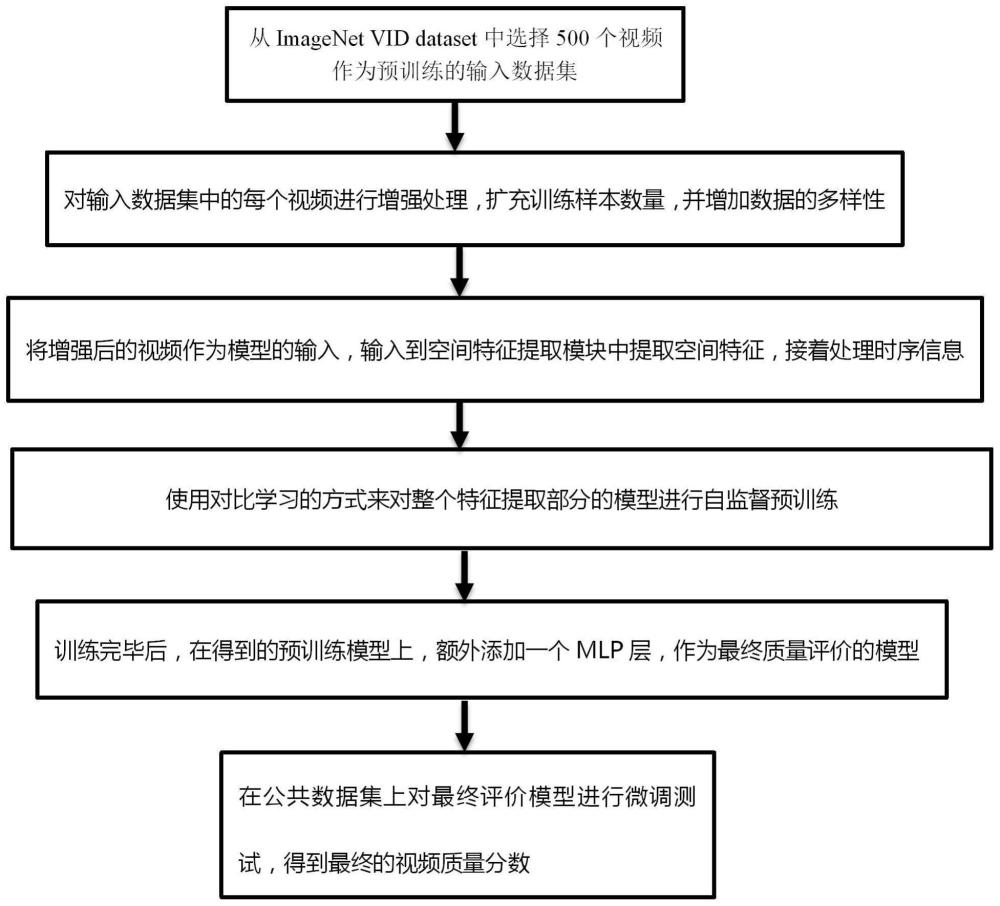
15、所述attention-lstm模型由输入层、lstm层、attention层、全连接层组成。lstm层用于捕获视频序列中的长期依赖关系,全连接层将lstm层和attention层学习到的高层次特征进行非线性映射和整合,得到最终的时空特征。
16、进一步的,所述训练好的视频质量评价模型的获取方法包括:
17、获取用于模型预训练的视频集;
18、将用于模型预训练的视频集输入到视频质量评价模型中,使用对比学习的方式来对视频质量评价模型的特征提取部分进行自监督预训进行自监督预训练;
19、训练完毕后,在得到的预训练模型上,额外添加一个mlp层,作为最终的视频质量评价模型。
20、进一步的,获取用于模型预训练的视频集的方法包括:
21、从imagenet vid dataset或其他适用数据集中,选择500个视频作为预输入数据集。
22、对所述预输入数据集进行预处理,包括解析视频格式、统一帧率和分辨率,以及剪裁或填充视频帧,使其达到统一的大小和格式,得到预处理后的视频数据;
23、对所述预处理后的视频数据进行数据增强,包括随机裁剪、水平翻转、颜色变换,得到用于模型预训练的视频集。
24、进一步的,将用于模型预训练的视频集输入到视频质量评价模型中,使用对比学习的方式来对视频质量评价模型的特征提取部分进行自监督预训进行自监督预训练,包括:
25、通过对未标记的视频数据进行自监督学习,所采用的对比损失函数为:
26、
27、式中,τ是温度超参数,q是一个编码好的特征,k0,k1,k2,…是一系列编码好的字典里的样本,字典里只有一个key即k+是跟q是匹配的,那么k+和q就互为正样本对,其余的key ki为q的负样本。
28、进一步的,所述方法还包括:
29、对这整个质量评估模型进行微调,微调的损失选择简单的均方误差,公式如下:
30、
31、其中n表示batch中的视频数,q′i和qi分别是主观质量标签和预测质量分数。
32、对微调后的模型进行测试,将特征提取部分得到的时空特征表示,通过多层感知器(mlp)层进行加权和组合,得到最终的视频质量分数。
33、第二方面,本发明提供一种基于conv2former和对比学习的视频质量评价装置,所述装置包括:
34、输入模块:用于获取待评价的视频;
35、增强模块:用于对所述待评价的视频进行数据增强和分帧,得到数据增强后的视频,所述视频包括连续的帧的组合;
36、预测模块:用于将数据增强后的视频输入训练好的视频质量评价模型中,得到预测的待评价的视频质量分数。
37、第三方面,本发明提供了一种基于conv2former和对比学习的视频质量评价装置,包括处理器及存储介质;
38、所述存储介质用于存储指令;
39、所述处理器用于根据所述指令进行操作以执行第一方面所述方法的步骤。
40、与现有技术相比,本发明所达到的有益效果:
41、本发明提出了一种基于conv2former和对比学习的视频质量评价方法及装置。该方法利用conv2former作为空间特征提取模块,并结合特征金字塔技术,对视频帧进行空间特征提取。与此同时,通过对比学习方法,可以有效地学习到有用的特征表示,从而提高对ugc视频质量的准确评估能力。这种方法相比传统方法具有以下优点:首先,它不依赖于大量的标记数据,减少了训练成本;其次,通过引入conv2former和对比学习,可以更好地捕捉视频的空间特征和时序关系,提高了对ugc视频质量的评估精度;最后,该方法在处理大规模ugc视频时具有较高的效率和可扩展性。
42、本发明提出的基于conv2former和对比学习的视频质量评价方法能够克服现有技术中的缺陷,实现对ugc视频的准确评估,为用户提供更好的观看体验,并满足不断增长的ugc视频需求。
43、本发明采用对比学习进行预训练,利用未标记的视频数据学习更具判别性的特征表示,可以有效解决数据不足的问题,提升模型的泛化能力和性能。为用户生成内容(ugc)视频,即那些由非专业方式产生的视频,提供了一种解决ugc视频质量评价的有效方案。
- 还没有人留言评论。精彩留言会获得点赞!