一种航行通告风险识别模型构建方法、装置、设备及存储介质与流程
本发明涉及民航安全风险识别,具体地说,涉及一种航行通告风险识别模型构建方法、装置、设备及存储介质。
背景技术:
1、航行通告是航空部门为处理航行突发事件向飞行员或飞航运作相关单位发送的公告。除了向相关人员传达信息外,航班在执行飞行任务前均需要依据航行通告来安排航线与飞行时间。据统计,目前每年全球发送的航行通告总数在百万级以上,数量仍在增长过程中。在航行通告日益增多的大趋势下,对航空公司的通告处理员的要求也随之提高。现如今航空公司大多采用数字化航行通告系统,通告的分发、接受、处理、通报等流程都会在数字化系统中完成。在航行通告的处理时,绝大部分时间值班员都要面临多条通告待处理的情况。在这种情况下,风险通告未能及时处理或者由于值班员的遗漏,严重时将导致巨大的航班运行潜在风险。
2、目前现有技术中风险识别是基于关键词匹配的规则方法,基于关键词过滤的逻辑,通过对人工基于对航行通告的运行风险匹配关键词,识别内容中是否存在涉及航班运行、调度等内容的安全风险。
3、但是现有的基于关键词规则集的匹配方法,关键词规则由业务人员添加和维护,规则集的日常迭代更新完全依赖人力,维护成本高,且相互之间难以有效形成合力。由于一词多义、主题漂移、敏感词滥用等问题的存在,关键词规则匹配策略的准确率普遍较低。
技术实现思路
1、为了解决上述问题,本发明提出一种航行通告风险识别模型构建方法、装置、设备及存储介质,构建的风险识别模型能够提高航行通告风险识别的效率和精度。
2、本发明实施例提供一种航行通告风险识别模型构建方法,所述方法包括:
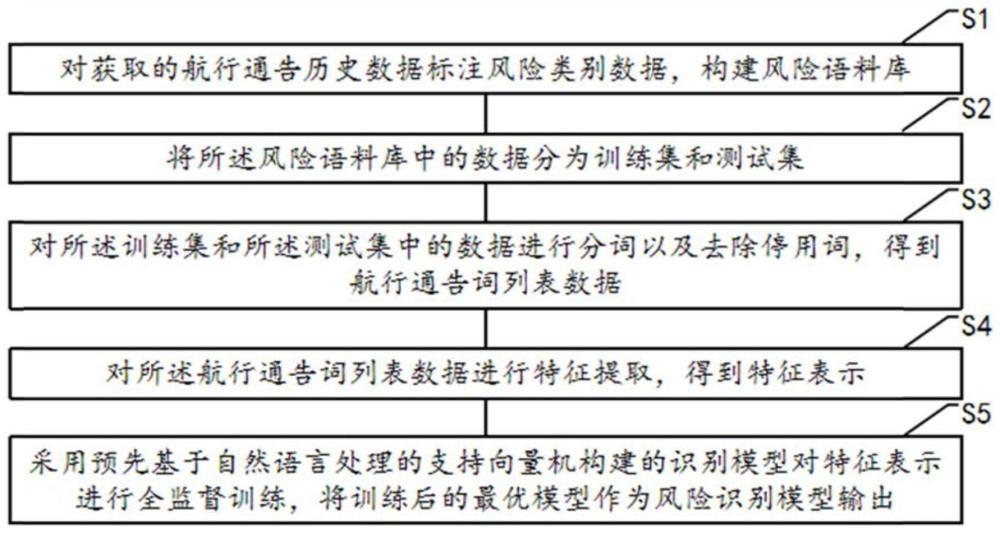
3、对获取的航行通告历史数据标注风险类别数据,构建风险语料库;
4、将所述风险语料库中的数据分为训练集和测试集;
5、对所述训练集和所述测试集中的数据进行分词以及去除停用词,得到航行通告词列表数据;
6、对所述航行通告词列表数据进行特征提取,得到特征表示;
7、采用预先基于自然语言处理的支持向量机构建的识别模型对特征表示进行全监督训练,将训练后的最优模型作为风险识别模型输出。
8、优选地,所述风险类别数据包括航行通告的风险与否以及风险类别。
9、作为一种优选方案,所述将所述风险语料库中的数据分为训练集和测试集,包括:
10、对所述风险语料库中的数据进行数据清洗,去除航行通告中的a项内容以及取消报,保留航行通告中的e项内容;
11、将数据清洗后的数据按照预设的比例随机划分为所述训练集以及所述测试集。
12、优选地,所述对所述训练集和所述测试集中的数据进行分词以及去除停用词,得到航行通告词列表数据,包括:
13、采用nltk分词工具对所述训练集以及所述测试集的航行通告的e项内容进行分词,并重新组合成词序列;
14、根据预设的停用词表取出所述词序列中的无意义词汇,得到所述航行通告词列表数据。
15、优选地,所述对所述航行通告词列表数据进行特征提取,得到特征表示,包括:
16、根据所述航行通告词列表数据创建历史通告e项内容的向量矩阵;
17、计算航行通告不同词语出现的词频;
18、计算不同航行通告的逆向文件频率;
19、计算航行通告不同词语的权重与逆向文件频率的乘积,将计算的乘积对所述向量矩阵进行赋值,将赋值后的向量矩阵作为所述特征表示;
20、其中,词频逆向文件频率ni,j为词语ti在航行通告dj中出现的次数,k指代航行通告中的任意词,∑knk,j为航行通告dj去停用词后的总词数,|d|为历史航行通告数据集的通告数量,|{j:ti∈dj}|表示包含词语ti的航行通告dj的数目。
21、作为一种优选方案,所述采用预先基于自然语言处理的支持向量机构建的识别模型对特征表示进行全监督训练,将训练后的最优模型作为风险识别模型输出,包括:
22、在所述训练集上求解优化问题,获取超平面参数;
23、采用所述特征表示中的航行通告的标注对所述识别模型进行全监督训练,在预测过程中,采用所述超平面参数计算映射后特征向量类别;
24、保存训练后的最优的模型作为所述风险识别模型。
25、优选地,所述方法还包括:
26、采用所述风险识别模型对输入的待处理通告进行计算,输出所述待处理通告的风险与否以及风险类别。
27、本发明实施例还提供一种航行通告风险识别模型构建装置,所述装置包括:
28、数据采集模块,用于对获取的航行通告历史数据标注风险类别数据,构建风险语料库;
29、数据处理模块,用于将所述风险语料库中的数据分为训练集和测试集;
30、分词模块,用于对所述训练集和所述测试集中的数据进行分词以及去除停用词,得到航行通告词列表数据;
31、特征提取模块,用于对所述航行通告词列表数据进行特征提取,得到特征表示;
32、模型训练模块,用于采用预先基于自然语言处理的支持向量机构建的识别模型对特征表示进行全监督训练,将训练后的最优模型作为风险识别模型输出。
33、作为一种优选方案,所述风险类别数据包括航行通告的风险与否以及风险类别。
34、作为一种优选方案,所述数据处理模块具体用于:
35、对所述风险语料库中的数据进行数据清洗,去除航行通告中的a项内容以及取消报,保留航行通告中的e项内容;
36、将数据清洗后的数据按照预设的比例随机划分为所述训练集以及所述测试集。
37、优选地,所述分词模块具体用于:
38、采用nltk分词工具对所述训练集以及所述测试集的航行通告的e项内容进行分词,并重新组合成词序列;
39、根据预设的停用词表取出所述词序列中的无意义词汇,得到所述航行通告词列表数据。
40、优选地,所述特征提取模块具体用于:
41、根据所述航行通告词列表数据创建历史通告e项内容的向量矩阵;
42、计算航行通告不同词语出现的词频;
43、计算不同航行通告的逆向文件频率;
44、计算航行通告不同词语的权重与逆向文件频率的乘积,将计算的乘积对所述向量矩阵进行赋值,将赋值后的向量矩阵作为所述特征表示;
45、其中,词频逆向文件频率ni,j为词语ti在航行通告dj中出现的次数,k指代航行通告中的任意词,∑knk,j为航行通告dj去停用词后的总词数,|d|为历史航行通告数据集的通告数量,|{j:ti∈dj}|表示包含词语ti的航行通告dj的数目。
46、优选地,所述模型训练模块具体用于:
47、在所述训练集上求解优化问题,获取超平面参数;
48、采用所述特征表示中的航行通告的标注对所述识别模型进行全监督训练,在预测过程中,采用所述超平面参数计算映射后特征向量类别;
49、保存训练后的最优的模型作为所述风险识别模型。
50、优选地,所述装置还包括风险识别模块,用于:
51、采用所述风险识别模型对输入的待处理通告进行计算,输出所述待处理通告的风险与否以及风险类别。
52、本发明实施例还提供一种终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一项实施例所述的一种航行通告风险识别模型构建方法。
53、本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如上述任一项实施例所述的一种航行通告风险识别模型构建方法。
54、本发明提供一种航行通告风险识别模型构建方法、装置、设备及存储介质,通过对获取的航行通告历史数据标注风险类别数据,构建风险语料库;将所述风险语料库中的数据分为训练集和测试集;对所述训练集和所述测试集中的数据进行分词以及去除停用词,得到航行通告词列表数据;对所述航行通告词列表数据进行特征提取,得到特征表示;采用预先基于自然语言处理的支持向量机构建的识别模型对特征表示进行全监督训练,将训练后的最优模型作为风险识别模型输出。本技术构建的风险识别模型能够提高航行通告风险识别的效率和精度。
- 还没有人留言评论。精彩留言会获得点赞!