一种面向MEC的依赖任务卸载方法
本发明属于移动边缘计算,涉及一种面向mec的依赖任务卸载方法。
背景技术:
1、b5g/6g技术和移动用户智能终端(mu)的出现,推动了自动驾驶、人脸识别、增强现实等移动应用的快速发展。为了应对减少响应延迟和增强用户体验的挑战,引入了一种称为移动边缘计算(mobile edge computing,mec)的灵活范例。它能够利用边缘网络的计算能力,降低任务传输延迟和成本,同时提高服务质量(quality of service,qos)。
2、数字孪生(digital twin,dt)技术将物理实体或系统的数字模型与其实际运行状态实时连接并同步。随着人工智能的发展,强化学习(reinforcement learning,rl),多智能体的强化学习rl和深度强化学习drl(deep reinforcement learning,drl)被越来越多地用于提高mec的卸载效率。然而,微型计算机有限的存储和计算能力阻碍了它们存储大量数据和训练神经网络的能力。mec和dt的整合为解决这一问题提供了一种实用的解决方案。更准确地说,dt可以收集大量物理实体层数据用于神经网络训练,这将有助于mu做出最优决策。
3、以往关于mec的研究主要集中在计算卸载上,大多都假设计算任务之间是相互独立的,但随着任务类型的日益丰富,这样的假设可能不再适用,许多计算密集型任务由多个相互依赖的子任务组成,其中当前子任务的处理依赖于前一个子任务的完成。因此,任务卸载的性能和可行性受到任务依赖性的很大影响,如何在依赖关系的约束下设计合理的任务分配策略是一个复杂的难题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种通过解决依赖感知任务的边缘协作卸载问题来最小化系统的能耗的面向mec的依赖任务卸载方法。首先,构建基于dt的mec系统架构,dt通过采集系统信息来训练神经网络,提高训练精度;其次,将依赖任务卸载问题转化为混合整数非线性规划(mixed-integer nonlinear programming,minlp)问题,并使用基于a3c算法来求解。
2、为达到上述目的,本发明提供如下技术方案:
3、一种面向mec的依赖任务卸载方法,所述方法包括如下步骤:
4、s1、基于数字孪生技术构建构建mec网络架构,其中,所述mec网络架构包括通信模型和计算模型;
5、s2、根据所述mec网络架构将在依赖关系约束下的任务分配策略问题转化为混合整数非线性规划问题,并进一步将依赖任务卸载问题优化为马尔可夫决策过程;
6、s3、通过a3c算法对所述混合整数非线性规划问题和马尔可夫决策过程进行求解,以获取依赖任务卸载的最优资源分配策略。
7、进一步地,在步骤s1中,所述mec网络架构中包括物理实体层和dt层,所述物理实体层中包括n个ess和m个mu,在dt层内分别用集合n={1,2,…,n}和m={1,2,…,m}表示;每个mui生成由多个相互依赖的子任务组成的任务,子任务集用j={1,2,...,j}表示,其中子任务j′的输出被用作子任务j的输入,子任务信息由表征,其中ci,j表示完成子任务所需的cpu周期总数,di,j表示子任务的数据大小,表示子任务j能够接受的最大延迟。
8、进一步地,在步骤s1中,所述mec网络架构中的通信模型中,mu与es之间的上行传输速率为:
9、
10、其中ω为信道带宽,hi,n表示es与mu之间的信道增益,σ2噪声功率,in为其他es对esj的接收干扰,令为当前服务器esn和其他服务器esn′之间的平均传输速率;
11、mu-to-es通信的传输延迟和能耗计算为:
12、
13、
14、es-to-es通信的传输延迟和能耗计算为:
15、
16、
17、其中,表示不同ess之间传输数据的每比特能耗,表示mu与es之间传输数据的每比特能耗。
18、4、根据权利要求3所述的一种面向mec的依赖任务卸载方法,其特征在于:在步骤s1中,所述mec网络架构的计算模型中包括本地计算和服务器执行计算;
19、在时隙t生成的子任务若由用户智能终端mu单独处理,则子任务的本地计算延迟时间为:
20、
21、本地计算产生的能耗由下式表示:
22、
23、其中,fi,local,j来表示mu为子任务j提供的计算资源;
24、在服务器执行计算中,为每个子任务定义二元决策变量ai,n,j={0,1},ai,n,j=0表示在本地执行子任务j,ai,n,j=1表示卸载到esn上执行子任务j,其中变量ai,n′,j′=1表示在esn′执行前一个子任务j';
25、根据子任务执行的位置和输入数据源,mui的子任务j分为以下情况:
26、(a)子任务在es中执行,且其输入数据也来自同一es,即ai,n′,j′=1,ai,n,j=1,n=n′;
27、(b)子任务在mu中执行,且其输入数据也来自同一mu,即ai,n,j′=0,ai,n,j=0;
28、(c)子任务在es中执行,其输入来自于mu,即ai,n,j′=0,ai,n,j=1;
29、(d)子任务在一个es中执行,其输入由另一个es引起,即ai,n′,j′=1,ai,n,j=1,n≠n′;
30、基于上述内容,表示由mui形成的子任务j的完成延迟表示为:
31、
32、其中表示mui的子任务j'的完成延迟时间,则mui的最大完成延迟为
33、子任务j的能耗为:
34、
35、则mui的总任务系统能耗表示为
36、进一步地,在步骤s2中,根据所述mec网络架构中的通信模型和计算模型,所述混合整数非线性规划问题表示为:
37、
38、
39、
40、
41、
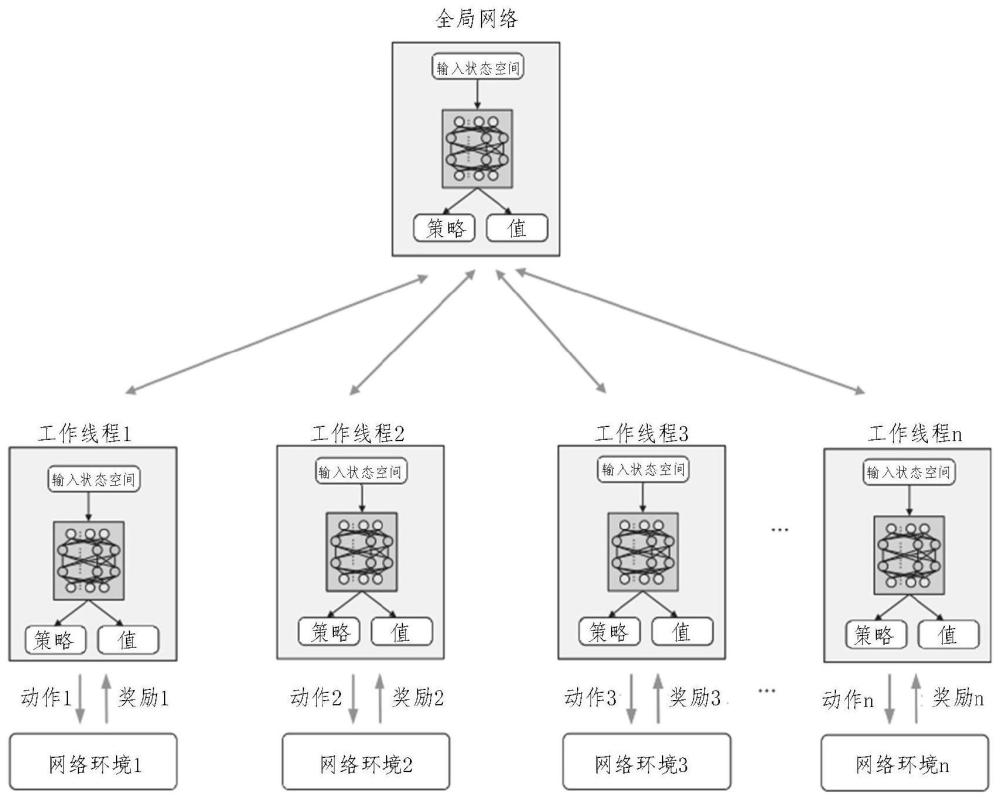
42、式中(10a)为二值决策变量,表示任务mu上执行还是在es上执行;式(10b)表示esn给出的计算资源保证不超过分配给mui的计算资源;每个子任务和总子任务的延迟分别受到(10c)和(10d)的限制。
43、进一步地,在步骤s2中,将依赖任务卸载问题优化为马尔可夫决策过程需要确定其状态空间、动作空间以及奖励函数,其中,
44、状态空间:网络环境表示系统状态,时隙t的状态表示为s(t)={l(t),a(t)},其中l(t)表示时隙t时es的计算能力,表示当前子任务的输入数据源;
45、动作空间用来表示每个时隙的决策,动作空间为at={a(t),f(t)},卸载决策向量为计算资源分配表示为
46、奖励函数:人工智能代理agent根据每个时间步的当前状态对所采取的每一个动作都立即获得奖励,奖励函数为:
47、
48、进一步地,在步骤s3中,所述a3c算法通过多个线程与环境并发交互,使多个线程能够异步训练神经网络,所述a3c算法的全局神经网络模型负责网络参数的存储和更新,每个线程执行一个基于当前状态建立的动作并观察到一个奖励,所述奖励将被传回神经网络进行参数调整,帮助智能代理agent学习和优化策略。
49、所述a3c算法包括|actor-ctitic网络框架,其中actor网络的目标是学习和优化策略,actor网络接收状态作为输入,生成动作概率分布,以提高策略的性能;critic网络用于管理衡量actor网络在特定状态下的表现。
50、进一步地,在步骤s3中,所述a3c算法根据当前状态st在策略函数π(at|st;θ)的指导下,系统执行相应的动作at并获得奖励rt,然后转换到下一个状态st+1,则由θv参数化的状态值函
51、数v(st;θv)在表示为:
52、其中gt表示状态st的折扣收益,折扣因子γ表示未来收益将如何影响当前系统状态,γ∈[0,1]。
53、进一步地,在步骤s3中,所述a3c算法采用m步更新法进行参数更新,m步的累积奖励为:
54、
55、其中rt+i表示即时奖励,m的上界是tmax;当m达到了最终状态或执行了tmax次操作,则值和策略函数都将更新;
56、所述a3c算法还引入优势函数,优势函数为:
57、
58、其中,策略的值函数和参数分别用θv和θ表示;所述actor-critic网络通过将当前状态下所采取的动作与期望收益和平均收益进行比较以估计动作的质量,从而帮助a3c算法调整策略,其中,actor网络的损失函数为:
59、fπ(θ)=logπ(at|st;θ)(rt-v(st;θ))+δh(π(st;θ))\*mergeformat(1.15)
60、其中,策略π的熵项为h(π(st;θ)),δ用于维持平衡;
61、critic网络的损失函数为:
62、fv(θv)=(rt-v(st;θv))2\*mergeformat(1.16)
63、接下来,更新actor网络和critic网络的策略参数:
64、
65、
66、基于此,全局参数θ和θv以异步方式更新,并由智能代理基于所述a3c算法做出最优决策。
67、本发明的有益效果在于:
68、本发明通过解决依赖感知任务的边缘协作卸载问题来最小化系统的能耗。首先,构建基于dt的mec系统架构,提高训练精度;其次,将依赖任务卸载问题转化为混合整数非线性规划(minlp)问题,并使用基于a3c算法来求解,通过获取最优策略来降低能耗。
69、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!