基于多角度相似性聚合与多重距离优化的行人重识别方法
本发明涉及计算机视觉,特别是涉及基于多角度相似性聚合与多重距离优化的行人重识别方法。
背景技术:
1、行人重识别技术是一种应用于视频监控、智能安全等领域的技术,旨在不同的摄像头和时间下检索相同的行人。但是随着城市化的发展,推动了大规模监控系统的普及,也产生海量数据,处理这些数据面临标注成本费时耗力问题。为了解决这个问题,也为了更好的满足现实世界中的实际应用场景,部分学者开始对无监督行人重识别方法产生了大量兴趣。无监督行人重识别的技术主要存在如下几个挑战:伪标签存在大量噪声、跨摄像头难匹配以及因安全隐私问题等导致的训练集样本较少。
2、随着深度学习的发展,针对无监督行人重识别领域的研究层出不穷。在无监督行人重识别领域中,受制于光照、遮挡、跨摄像头捕获样本等外界条件,无监督行人重识别中基于聚类算法生成的伪标签存在大量噪声,从而误导模型优化。结果使得同一聚类下的样本会相互远离,而来自不同集群的样本则会相互靠近。深度学习算法是目前主流的解决方案,致力于降低各种因素导致的伪标签噪声。部分学者计划从样本的细粒度上下文特征出发,综合考量全局和局部输出特征。在生成伪标签之前,有人直接分别计算全局和多个局部学习之间的相似度关系,然后加权多个来自不同视图的矩阵。或者设计一个双分支模型,利用预训练的摄像机分类网络计算两个样本的摄像机相似性,并用摄像机相似性减去特征相似性。但这可能会引入额外的噪声并大量增加网络成本,并且十分依赖于预训练的摄像机模型,反而起到负面作用。
技术实现思路
1、为了解决上述现有技术中的不足,本发明的目的是提供一种基于多角度相似性聚合与多重距离优化的行人重识别方法,从源头尽可能降低产生伪标签噪声的风险,也不需要额外的计算资源,非常适用于多复杂场景数据集。
2、本发明解决其技术问题所采用的技术方案为:
3、提供了一种基于多角度相似性聚合与多重距离优化的行人重识别方法,包括以下步骤:
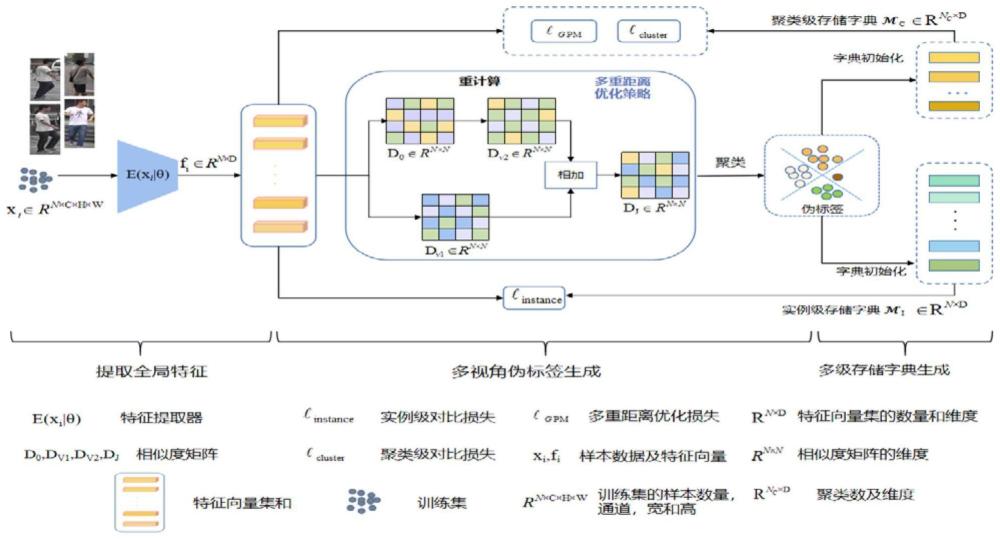
4、s1:多角度相似性聚合模块利用多个角度的样本特征间的相似度关系,避免受单一偏好的影响;
5、s2:多重距离优化策略会进一步从困难样本挖掘的视角出发,同时考虑实例样本之间和聚类样本间的一致性,分别利用它们的极致困难样本和平均样本,缩小同一聚类下的样本距离,同时拉大不同类别间的样本距离;
6、步骤s1的方法为:
7、s11:利用特征提取器e(.|θ)得到当前模型提取到的全局信息,直接计算训练集样本的全局特征之间杰卡德距离dv1;
8、s12:计算样本之间的欧式距离do,利用重排序技术来计算出新的杰卡德距离dv2,通过固定权重直接把从两个角度的计算出的杰卡德距离矩阵加权得到最终的dj;
9、s13:把dj用以dbscan聚类算法生成伪标签。
10、进一步的,步骤s12中,dj的计算公式为:
11、dv2=recompute(||fi-fj||)
12、dj=(1-γ)dv1+γdv2
13、其中γ是超参数,用于加权考虑两个视角生成距离矩阵的影响;recompute(x)表示直接在x矩阵的基础上重新计算矩阵相似度,(||fi-fj||)表示直接计算两个特征向量之间的欧式距离do。
14、进一步的,步骤s13中,将dj用以dbscan聚类算法生成所有训练集样本对应的伪标签yi,yi表示样本xi聚类后的伪标签,最终形成样本对集合u′={(x1,y1),(x2,y2),(x3,y3)…,(xn,yn)},其中,n表示整个训练集样本数量,且yi∈{1,2,3…c},其中c表示聚类级存储字典的质心类别数,并对不同层级的样本信息分别存储,生成实例级存储字典mi和聚类级存储字典mc。
15、进一步的,在mi中会直接按序存储训练集样本的全局特征;mc={m1,m2…mc},同时不考虑异常样本聚类,mi表示第i个聚类的质心向量,通过下面公式对mi和mc分别进行初始化:
16、ck={fi|yi=yk and yi≠-1}
17、
18、其中,ck表示样本i对应的聚类k下的所有样本特征向量,且该聚类下的所有样本当前的伪标签不为一1,然后直接计算该聚类下所有样本的均值特征作为质心,同时,通过下面公式对实例级存储字典也进行初始化:
19、
20、进一步的,步骤s2中,通过直接计算输入样本与聚类存储字典质心之间的转置乘积,衡量输入样本和聚类级存储字典的关系,具体公式如下:
21、
22、其中,fj表示当前输入样本的模型输出,mi是第i个聚类级字典的质心,m+则是输入样本i对应的质心向量,τ是温度系数。
23、进一步的,步骤s2中,还需要衡量输入样本和实例级字典的关系,具体如下:
24、
25、其中,p是当前输入样本对应的正样本集,这里不会丢弃掉任何异常样本,也会参与损失函数的计算,最终,基线的损失函数lbase直接综合考虑lcluster和linstance:
26、lbase=linstance+1.2lcluster。
27、进一步的,在每个批量样本中为每个输入实例衡量其正负样本集之间的差异:
28、ps=softmax(cat([fmin-e(fp),fmax-e(fn)]))
29、lss=e(-λ1ps[0]-(1-λ1)ps[1])
30、其中,e(x)表示计算向量集x的均值,cat(x,y)会把括号内的向量x和y在第1维拼接;fmax和fmin则分别表示当前输入样本的距离最近的负样本和相似度最小的正样本;fp和fn表示在当前批量样本中的正负样本集合;
31、将输入样本对应的聚类级质心和其他质心视为正负聚类,分别按照上述两个公式进行计算,最终得到输入样本之间的lss和聚类级质心之间的lsc,通过权重加权ω0得到最后的ls0:
32、ls0=ω0lss+(1-ω0)lsc。
33、进一步的,从单个样本之间以及聚类质心之间出发,得到相应的损失函数ls-adapt和lc-adapt,最后综合两个损失值得到lgpm:
34、
35、ls1=ω1ls-adapt+(1-ω1)lc-adapt
36、lgpm=ls0+ls1
37、其中,c表示聚类数量,e(x)表示求均值,表示以聚类i下的所有样本为锚点,分别计算锚点和其他所有负类别间样本的相似性,正样本对和为所有样本的困难正样本集合以及最不困难正样本集合。
38、进一步的,总损失函数lall由如下所示,共同来优化特征提取器e(.|θ):
39、lall=lbase+lgpm。
40、进一步的,在模型优化的同时,需要实时利用输入样本来更新聚类和实例级存储字典,具体更新方法如下所示:
41、
42、
43、其中,α表示输入样本对聚类级和实例级存储字典的更新速率。
44、与现有技术相比,本发明的有益效果在于:
45、1、本发明示例的行人重识别方法,提出了一种新的多角度相似性聚合,用于无监督行人重识别,目前主要是在聚类算法得到伪标签后进行去噪操作,这些方法虽然在一定程度有助于生成高质量的伪标签,但都是建立在相似度矩阵本身就存在大量噪声的基础上来降噪的,这些方法都会导致计算出的相似度关系受到单一特征的局限,难以有效解决由于姿态、视角和光照等因素的影响导致的同一个行人标识存在的巨大类内差异;本发明直接利用多方面的样本特征间的相似度关系,在聚类生成伪标签前就进行降低噪声操作,可以有效避免受单一偏好的影响,可以从源头尽可能降低产生伪标签噪声的风险,也不需要额外的计算资源,非常适用于多复杂场景数据集;
46、2、本发明示例的行人重识别方法,设计了多重距离优化策略,计算单个样本之间和聚类之间的差异性和均衡性,拉近同一聚类下的各样本距离,同时扩大类间聚类的差异,可以有效降低伪标签噪声,进一步提高模型的性能。
- 还没有人留言评论。精彩留言会获得点赞!