基于编码器和解码器结构的深度学习SAR影像配准方法
本发明涉及深度学习技术、大模型应用、图像分割和合成孔径雷达(syntheticaperture radar,sar)影像配准等领域,旨在提高sar影像配准的稳定性和精度。
背景技术:
1、合成孔径雷达是一种主动传感器技术,通过雷达波束合成高分辨率的图像,相比于光学遥感影像,sar不依赖光照,具有全天候、全天时的特点。我国南方大部地区夏季高温且多雨,光学遥感难以满足多云雨天气的影像数据获取条件。而sar可以全天候、全天时的获取数据,且成像范围较广。因此,高分辨率sar影像具有很大的应用潜力。
2、影像配准是把2幅或者多幅的影像中相同或者相似部分对应起来的过程。在sar影像的应用中,如数据融合、变化检测和重复轨道的干涩等,都需要对影像进行高精度快速配准。在sar影像成像过程中容易受杂波干扰,图像中存在的散斑噪声对sar影像的配准会产生影响。目前遥感影像的配准方法主要有基于区域、基于特征点检测和深度学习的方法。基于区域的方法是将遥感影像分成不同的区域,构建区域之间的相似性度量函数,然后计算形变参数,实现对图像的配准。这种方法实现简单,但是对强度变化和噪声敏感,并且需要大量的计算资源和计算时间。特征点检测的方法通过识别图像中显著、稳定且可以区分的特征点,然后进行描述和匹配。然而,受散斑噪声的影响,特征点检测的方法稳定性差,从而导致使用该方法对sar影像配准有精度低和泛化能力弱的问题。
3、近年来,深度学习的发展比较迅速,并且在很多领域取得了巨大的成功。目前,很多关于图像的深度学习网络被提出和应用,可以自动的进行特征学习、适应复杂变换和进行端对端的训练,在图像配准任务上展现了独特的优势。但是深度学习是数据驱动的,而目前关于sar影像的数据集较少,较难训练出精度较高,较稳定的模型。图像大模型的出现为解决深度学习中数据集较少的问题,提供了新的思路。比如分割一切大模型,使用了迄今为止最大的分割数据集进行训练,可以零样本迁移到新的图像分割任务中,然后得到该图像的掩码。当需要sar遥感影像的掩码数据集时,就可以利用分割一切大模型对sar遥感影像进行分割,得到掩码数据集,然后利用此数据集训练网络,可以解决缺乏数据集的问题。
4、图像分割是计算机视觉中的一项重要任务,其目标是将图像划分为具有语义上相似的区域或对象。图像分割技术在许多领域中都有广泛的应用,如医学图像分析、自动驾驶、目标识别等。在图像分割技术中,图像语义分割技术旨在为图像中的每个像素分配一个语义标签,以区分不同的对象或区域,一般使用深度学习模型进行图像分割,如deeplab模型,基于卷积神经网络(cnn)的编码器和解码器结构,对图像进行逐像素分类实现语义分割。在语义分割和实例分割任务中,对复杂场景的图像分割具有出色的性能。
技术实现思路
1、为了提高sar影像配准的准确度、效率和稳定性,本发明提出了一种利用掩码对sar影像配准的深度学习方法,该方法基于编码器和解码器的神经网络结构。现有配准方法中,通常采用特征点检测的方法检测特征点,然后进行特征点的描述和匹配,因为单个特征点容易受sar影像的相干斑噪声的影响,因此特征点检测存在误检和漏检的问题,导致配准精度低、效率低。本发明采用掩码进行配准,通过深度学习网络寻找图像之间掩码的匹配关系,以此来寻找参考图像和主图像之间的匹配关系,实现图像之间的配准。掩码相比于特征点含有更丰富的图像特征信息,具有较强的抗噪声能力,相比于特征点检测、描述和匹配的方法,本发明更具有稳定性且效率更高。
2、为了实现本发明目的,采用的技术方案概述如下:
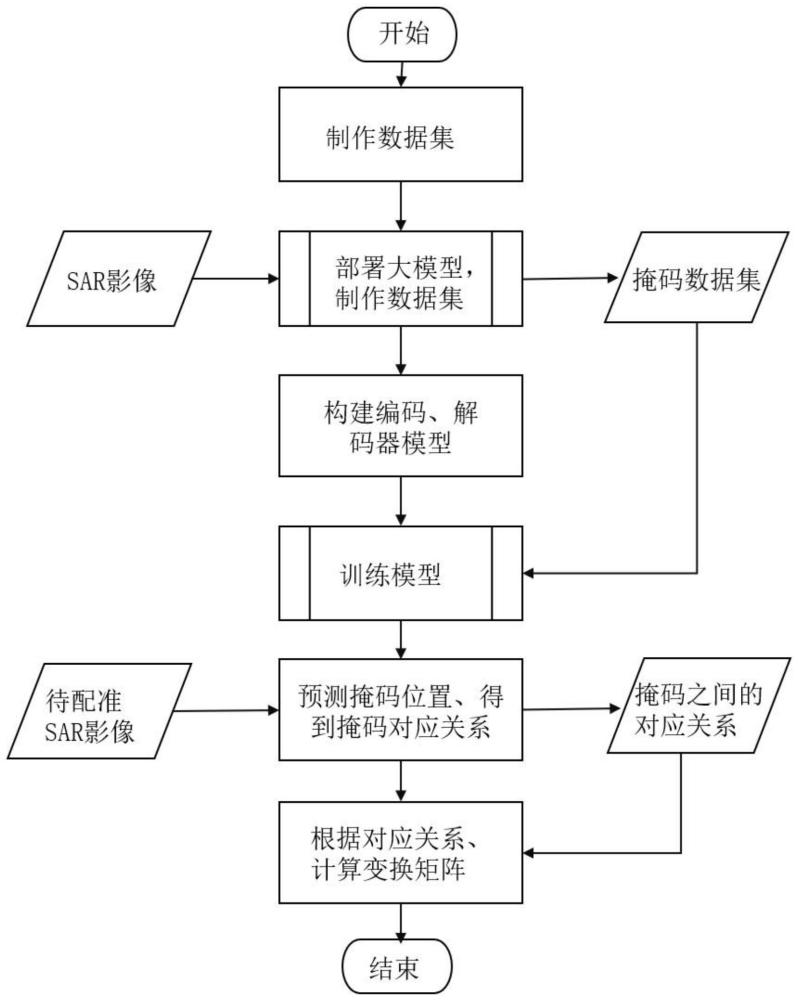
3、本发明是一种利用掩码、基于编码器和解码器结构的深度学习sar影像配准方法,利用模型寻找参考图像的掩码在主图像中的位置,利用此位置关系寻找参考图像和主图像之间的对应关系,达到主图像和参考图像配准的目的,包括以下步骤:
4、(1)构建掩码数据集,用以训练模型。
5、掩码数据集用来对构建的编码器和解码器结构的深度学习模型进行训练。掩码数据集的质量很大程度上影响模型的准确性,但是目前用于寻找掩码位置的训练数据集几乎没有,采用人工标注制作数据集的方式成本极高,采用图像大模型技术来生成掩码数据集。掩码数据集制作过程中,每个掩码数据集标本含有三个要素:主图像、参考图像掩码和该掩码所在主图像中的位置标签。首先准备已经严格配准的sar影像数据(主图像和参考图像已经严格配准),部署分割一切图像大模型(segmentanything model,sam),使用sam对参考图像分割,得到参考图像的掩码,使用此掩码的位置制作数据集样本标签。参考图像只保留该掩码部分,并移动到参考图像的中间,得到参考图像的掩码。由此,得到主图像、参考图像的掩码和标签组成的数据集样本。使用多线程技术按照上诉方法并行制作数据集样本,得到数据集,加快数据集制作效率。
6、(2)构建基于编码器和解码器结构的深度学习模型
7、因为本发明利用掩码对sar影像进行配准,是否能准确寻找到参考图像的掩码在主图像中的位置,对于配准精度来说尤其关键。基于编码器和解码器结构的神经网络结构中,编码器用来提取掩码内部区域的高级语义特征,关注语义信息,解码器提取掩码的边界特征,关注低级特征。编码器分为两个模块,一个是经过修改的基于深度可分离卷积层的卷积神经网络体系结构(xception)模型,另一个是空间金字塔池化模块(aspp)。xception网络采用了深度逐通道卷积的操作,能有效理解图像中的语义信息,并提高计算效率和性能。aspp模块包含多个并行的空洞卷积分支,每个分支具有不同的孔径,通过在卷积核中引入孔,可以扩大感受野,目的是为了捕获多尺度的上下文信息,以便更好的理解图像中的语义信息。解码器包含5个卷积和1个池化操作,用来提取掩码边界的低级特征。最后把编码器和解码器提取的特征合并,经过上采样之后,生成预测的掩码位置。
8、(3)使用模型对sar影像配准
9、模型训练完成之后,就可以利用模型对sar影像进行配准。对于待配准的sar影像数据,首先使用轨道数据进行粗配准,然后对sar影像数据裁剪,得到裁剪尺寸为256×256,包含主图像和参考图像的数据对,并记录裁剪的位置。然后采用图像大模型对参考图像进行分割得到掩码,参考图像只保留掩码部分,并把该部分移动到图像中间,得到参考图像掩码。然后把主图像和参考图像掩码合并,输入基于编码器和解码器的深度学习模型,并利用该模型预测参考图像的掩码在主图像之中的位置。预测得到的位置是掩码在主图像中的位置,和记录的参考图像掩码的位置之间是对应关系,通过这种方式就得到了一个参考图像和主图像之间的对应关系。利用多线程技术重复此操作,得到参考图像和主图像之间对应关系集合,利用最小二乘法计算主图像和参考图之间的变换矩阵,即实现配准的目的。
10、与现有技术相比,本发明具有以下特点:
11、采用图像大模型制作数据集,解决了在深度学习中数据集缺乏的问题。数据集在深度学习中非常重要,数据集的质量极大的影像模型的训练结果。本发明中数据集需要具备三个要素:主图像、参考图像掩码和掩码的位置标签。如果采用人工或者半自动方法制作数据集,成本极高且耗时。采用大模型自动进行参考图像的掩码分割,几乎不需要人工参与,极大的提高了数据集的制作效率。由于大模型的通用性,采用本发明所使用的方法,可以轻松制作不同影像的数据集。
12、sar影像受到噪声和变形的影响,目前的方法在处理这些问题时存在一定的困难。而基于编码器和解码器结构的深度学习模型具有强大的非线性拟合能力,其中的编码器结构能较好的处理掩码的语义信息,解码器结构处理掩码的边界信息,通过编码器和解码器的整合,本发明能准确的预测参考图像的掩码在主图像的位置,能有效对抗噪声对sar影像的干扰。通过实验表明,通过本发明中设计的神经网络寻找参考图像的掩码在主图像中的位置,比使用其他方法,如归一化互相关和互信息等方法,本发明的方法准确度更高,并且寻找速度更快。
13、能准确找到参考图像的掩码在主图像中的位置的前提下,本发明创新性的采用参考图像的掩码在主图像中的位置,来寻找参考图像和主图像之间的对应关系,来达到参考图像和主图像配准的目的。采用这种方式,能有效抵抗sar影像的噪声,具有通用性和适应性。无论是针对不同频段、不同分辨率还是不同成像模式的sar影像,该方法都能够适应并取得良好的配准效果。
- 还没有人留言评论。精彩留言会获得点赞!