一种数据要素多特征融合智能匹配方法与流程
本发明属于数据产品检索领域,尤其涉及一种数据要素多特征融合智能匹配方法。
背景技术:
1、在数据交易平台上,数据产品的特性不仅仅包括价格,还包括时效性、质量等多个因素。线上商品供需关系匹配是电子商务平台的关键问题之一。有搜索引擎优化(seo),实时库存管理,需求预测,供应链优化等。为传统商品的线上交易服务提供供需匹配。而新型的线上数据交易具有一些特点,这些特点使其与线上数据商品交易有很大不同,交易线上数据交易具有数字性、多样性、实时性和隐私等特点,这些特点使其在现代商业中发挥着越来越重要的作用。然而,与之相关的风险和合规性问题也需要得到认真对待。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种数据要素多特征融合智能匹配方法解决了数据产品检索过程中信息不对称的问题。
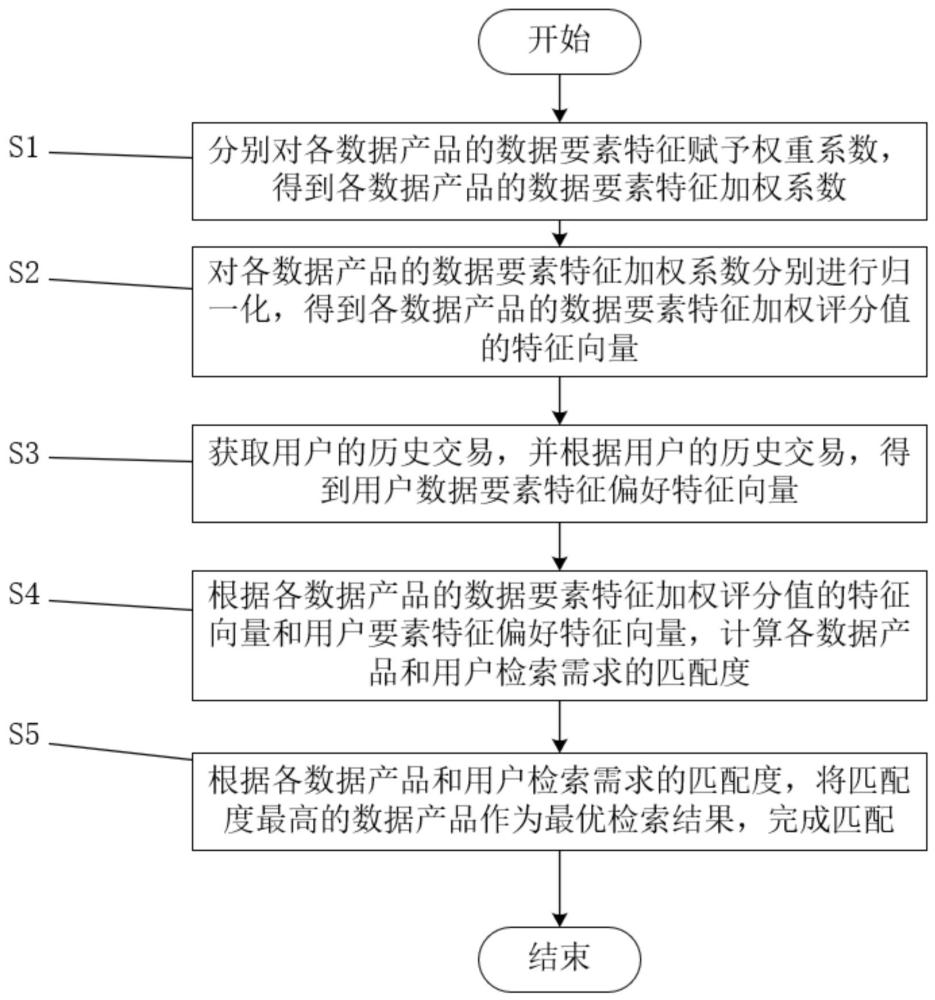
2、为了达到上述发明目的,本发明采用的技术方案为:一种数据要素多特征融合智能匹配方法,包括以下步骤:
3、s1、分别对各数据产品的数据要素特征赋予权重系数,得到各数据产品的数据要素特征加权系数;
4、s2、对各数据产品的数据要素特征加权系数分别进行归一化,得到各数据产品的数据要素特征加权评分值的特征向量;
5、s3、获取用户的历史交易,并根据用户的历史交易,得到用户数据要素特征偏好特征向量;
6、s4、根据各数据产品的数据要素特征加权评分值的特征向量和用户要素特征偏好特征向量,计算各数据产品和用户检索需求的匹配度;
7、s5、根据各数据产品和用户检索需求的匹配度,将匹配度最高的数据产品作为最优检索结果,完成匹配。
8、本发明的有益效果为:通过考虑到数据产品的数据要素特征和用户要素特征偏好加权匹配,可以提高用户检索的效率,提供更有效和满足实时性需求的数据产品,有助于创造一个更高效透明的数据交易生态系统。
9、进一步地,所述步骤s1中各数据产品的数据要素特征均包括数据成本价值、数据时效性和数据稀缺性;各所述数据产品的数据要素特征加权系数均包括数据成本价值加权系数、数据时效性加权系数和数据稀缺性加权系数。
10、上述进一步方案的有益效果为:根据成本、时效性和稀缺性三方面对数据进行特征提取,可将数据产品特征进行有效量化,降低匹配难度。
11、进一步地,所述数据成本价值加权系数的表达式为:
12、
13、
14、其中,为数据成本价值加权系数;为第个数据产品的成本价值;为数据产品编号;为数据产品总数;为生成第个数据产品需要的人员数量;为生成第个数据产品需要的时间。
15、上述进一步方案的有益效果为:将数据产品的成本价值进行有效量化,降低匹配难度。
16、进一步地,所述数据时效性加权系数的表达式为:
17、
18、
19、其中,为数据时效性加权系数;为第个数据产品的时效性价值;为数据产品编号;为数据产品总数;为第个数据产品涉及到的数据时间;为当前时间。
20、上述进一步方案的有益效果为:将数据产品的时效性进行有效量化,降低匹配难度。
21、进一步地,所述数据稀缺性加权系数的表达式为:
22、
23、
24、其中,为数据稀缺性加权系数;为第个数据产品的稀缺性价值;为数据产品编号;为数据产品总数;为第个数据产品的数据量;为第个数据产品所属类别的数据总量。
25、上述进一步方案的有益效果为:将数据产品的稀缺性进行有效量化,降低匹配难度。
26、进一步地,所述步骤s2中各数据产品的数据要素特征加权评分值的特征向量为:
27、
28、
29、
30、
31、其中,为第个数据产品的数据要素特征加权评分值的特征向量;为数据产品编号;为第个数据产品的数据成本价值归一化后的值;为第个数据产品的数据时效性归一化后的值;为第个数据产品的数据稀缺性归一化后的值;为第个数据产品的数据成本价值加权系数;为第个数据产品的数据时效性加权系数;为第个数据产品的数据稀缺性加权系数;为第个数据产品的数据成本价值;为所有数据产品中数据成本价值的最小值;为所有数据产品中数据成本价值的最大值;为第个数据产品的数据时效性;为所有数据产品中数据时效性的最小值;为所有数据产品中数据时效性的最大值;为第个数据产品的数据稀缺性;为所有数据产品中数据稀缺性的最小值;为所有数据产品中数据稀缺性的最大值;为乘法符号。
32、上述进一步方案的有益效果为:根据数据产品的成本价值、时效性和稀缺性进行综合考量,把数据产品进行整体量化,降低匹配难度。
33、进一步地,所述步骤s3中用户数据要素特征偏好特征向量为:
34、
35、
36、
37、
38、其中,为用户数据要素特征偏好特征向量;为用户历史购买过的数据产品的数据成本价值的平均值;为用户历史购买过的数据产品的数据时效性的平均值;为用户历史购买过的数据产品的数据稀缺性的平均值;为用户历史购买过的第个数据产品的数据成本价值;为用户历史购买过的数据产品的编号;为用户历史购买过的第个数据产品的数据时效性;为用户历史购买过的第个数据产品的数据稀缺性。
39、上述进一步方案的有益效果为:根据用户历史行为,量化用户数据要素特征偏好,降低匹配难度。
40、进一步地,所述各数据产品和用户检索需求的匹配度为:
41、
42、其中,为第个数据产品和用户检索需求的匹配度;为数据产品编号;为第个数据产品的数据要素特征加权评分值的特征向量;为用户数据要素特征偏好特征向量;为l2范数;为乘法符号。
43、上述进一步方案的有益效果为:根据数据产品的数据要素特征加权评分值的特征向量和用户数据要素特征偏好特征向量计算数据产品和用户检索需求的匹配度,将海量数据和用户爱好转为更轻量更具体的向量进行计算,降低了匹配难度,同时为数据产品推荐提供指导。
技术特征:
1.一种数据要素多特征融合智能匹配方法,其特征在于,包括以下步骤:
2.根据权利要求1所述数据要素多特征融合智能匹配方法,其特征在于,所述步骤s1中各数据产品的数据要素特征均包括数据成本价值、数据时效性和数据稀缺性;各所述数据产品的数据要素特征加权系数均包括数据成本价值加权系数、数据时效性加权系数和数据稀缺性加权系数。
3.根据权利要求2所述数据要素多特征融合智能匹配方法,其特征在于,所述数据成本价值加权系数的表达式为:
4.根据权利要求2所述数据要素多特征融合智能匹配方法,其特征在于,所述数据时效性加权系数的表达式为:
5.根据权利要求2所述数据要素多特征融合智能匹配方法,其特征在于,所述数据稀缺性加权系数的表达式为:
6.根据权利要求1所述数据要素多特征融合智能匹配方法,其特征在于,所述步骤s2中各数据产品的数据要素特征加权评分值的特征向量为:
7.根据权利要求1所述数据要素多特征融合智能匹配方法,其特征在于,所述步骤s3中用户数据要素特征偏好特征向量为:
8.根据权利要求1所述数据要素多特征融合智能匹配方法,其特征在于,所述各数据产品和用户检索需求的匹配度为:
技术总结
本发明公开了一种数据要素多特征融合智能匹配方法,属于数据产品检索领域,该方法包括分别对各数据产品的数据要素特征赋予权重系数,得到各数据产品的数据要素特征加权系数;对各数据产品的数据要素特征加权系数分别进行归一化,得到各数据产品的数据要素特征加权评分值的特征向量;获取用户的历史交易,并根据用户的历史交易,得到用户数据要素特征偏好特征向量;根据各数据产品的数据要素特征加权评分值的特征向量和用户要素特征偏好特征向量,计算各数据产品和用户检索需求的匹配度;根据各数据产品和用户检索需求的匹配度,将匹配度最高的数据产品作为最优检索结果,完成匹配。本发明解决了数据产品检索过程中信息不对称的问题。
技术研发人员:徐锴,彭真,曹晔,蔡小林,周翔,曾爽哲
受保护的技术使用者:四川易利数字城市科技有限公司
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!