用户负荷数据预测方法、装置和电子设备与流程
本发明涉及人工智能,具体地涉及一种用户负荷数据预测方法、一种用户负荷数据预测装置和一种电子设备。
背景技术:
1、随着社会经济的不断发展,人们对能源的需求不断扩大,使得电力系统的结构和运行模式呈现出多元化的发展形势。由于电能不能大规模储存,电力负荷的变化不确定,电力系统负荷预测问题逐渐开始关注,相关理论和技术也在不断发展和更新。用户侧负荷预测是智能配电台区协同控制、电能调度的重要依据,也是解决电网稳定运行的关键研究课题。
2、目前,用户负荷短期预测方法主要分为经典预测和智能预测。经典预测主要依据传统统计学预测模型,包括卡尔曼滤波模型、arima模型、holt winters模型等。经典预所需模型训练的数据量小,易于实现等优点。智能预测主要依赖于机器学习预测模型,包括支持向量机,极限学习机,长短时记忆神经网络等,智能预测模型可以学习到负荷数据的特征,非线性拟合能量强,相较于经典预测模型具有预测精度高的优点。
3、但是无论对于经典预测还是对于智能预测而言,模型的预测精度均较低。
技术实现思路
1、本发明实施例的目的是提供一种用户负荷数据预测方法、一种用户负荷数据预测装置和一种电子设备,用以解决现有的用户负荷短期预测方法中模型的预测精度较低的缺陷。
2、为了实现上述目的,本发明实施例提供用户负荷数据预测方法,包括:
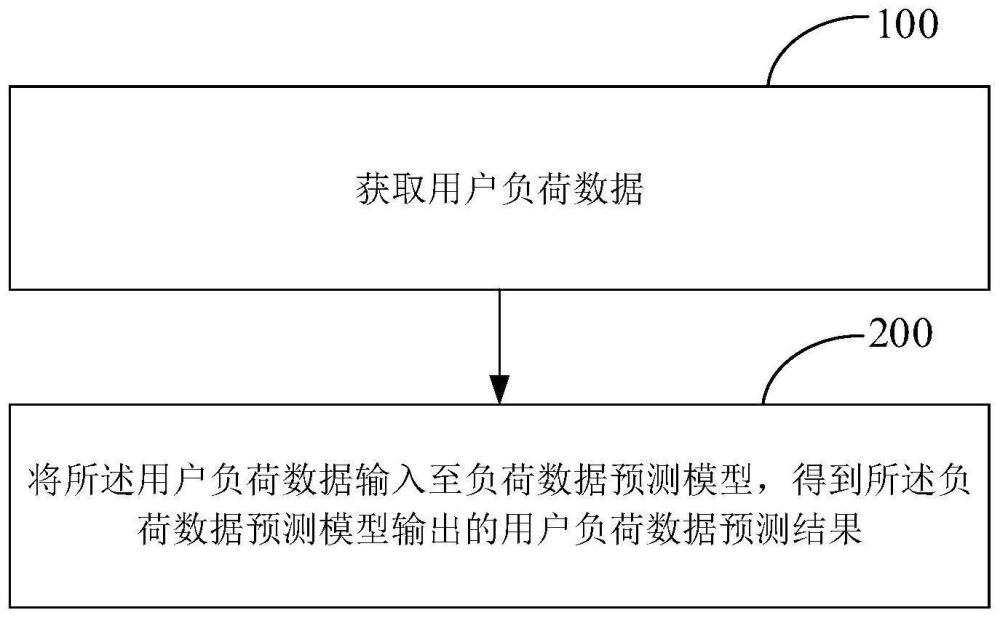
3、获取用户负荷数据;
4、将所述用户负荷数据输入至负荷数据预测模型,得到所述负荷数据预测模型输出的用户负荷数据预测结果;
5、其中,所述负荷数据预测模型的模型参数是基于改进蜣螂优化方法训练得到的;所述改进蜣螂优化方法是在繁殖行为阶段和/或觅食行为阶段,基于用于增强全局寻优能力的动态权重策略因子、莱维飞行策略因子以及改进自适应收敛因子中的至少一种因子改进得到的;所述负荷数据预测模型是基于用户训练负荷数据和用户验证负荷数据训练得到的。
6、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于动态权重策略因子改进的公式如下:
7、
8、
9、其中,ω表示动态权重策略因子,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),ω_max=ub*,ω_min=lb*,t表示迭代次数,tmax为最大迭代次数,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置。
10、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于莱维飞行策略因子改进的公式如下:
11、
12、
13、c1=2grg(1-t/max);
14、
15、
16、γ(x)=(x-1)!;
17、其中,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,le表示莱维飞行策略因子,c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,t表示迭代次数,tmax为最大迭代次数,g是大小为1×d维的服从正态分布的随机向量。
18、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于改进自适应收敛因子改进的公式如下:
19、
20、lb*=max(x*×(1-r),lb);
21、ub*=min(x*×(1+r),ub);
22、
23、其中,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),t表示迭代次数,tmax为最大迭代次数,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界。
24、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于动态权重策略因子和莱维飞行策略因子改进的公式如下:
25、
26、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
27、
28、c1=2grg(1-t/tmax);
29、
30、
31、γ(x)=(x-1)!;
32、其中,ω表示动态权重策略因子,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),ω_max=ub*,ω_min=lb*,t表示迭代次数,tmax为最大迭代次数,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,le表示莱维飞行策略因子,c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,g是大小为1×d维的服从正态分布的随机向量。
33、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于动态权重策略因子和改进自适应收敛因子改进的公式如下:
34、
35、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
36、lb*=max(x*×(1-r),lb);
37、ub*=min(x*×(1+r),ub);
38、
39、其中,ω表示动态权重策略因子,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),ω_max=ub*,ω_min=lb*,t表示迭代次数,tmax为最大迭代次数,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,r表示改进自适应收敛因子;lb和ub分别表示优化问题的下界和上界。
40、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于莱维飞行策略因子和改进自适应收敛因子改进的公式如下:
41、
42、lb*=max(x*×(1-r),lb);
43、ub*=min(x*×(1+r),ub);
44、
45、
46、c1=2grg(1-t/tmax);
47、
48、
49、γ(x)=(x-1)!;
50、其中,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),xit+1表示迭代次数为t+1次第i只蜣螂的位置;xti表示迭代次数为t次第i只蜣螂的位置,le表示莱维飞行策略因子,c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,t表示迭代次数,tmax为最大迭代次数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,g是大小为1×d维的服从正态分布的随机向量。
51、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于动态权重策略因子、莱维飞行策略因子以及改进自适应收敛因子改进的公式如下:
52、
53、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
54、
55、c1=2grg(1-t/tmax);
56、
57、
58、γ(x)=(x-1)!;
59、lb*=max(x*×(1-r),lb);
60、ub*=min(x*×(1+r),ub);
61、
62、其中,ω表示动态权重策略因子,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),ω_max=ub*,ω_min=lb*,t表示迭代次数,tmax为最大迭代次数,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,le表示莱维飞行策略因子,c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,t表示迭代次数,tmax为最大迭代次数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,g是大小为1×d维的服从正态分布的随机向量。
63、可选的,所述改进蜣螂优化方法在觅食行为阶段基于动态权重策略因子改进的公式如下:
64、
65、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
66、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),ω表示动态权重策略因子,ω_max=ubb,ω_min=lbb,t表示迭代次数,tmax为最大迭代次数。
67、可选的,所述改进蜣螂优化方法在觅食行为阶段基于莱维飞行策略因子改进的公式如下:
68、
69、
70、c1=2grg(1-t/tmax);
71、
72、
73、γ(x)=(x-1)!;
74、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),t表示迭代次数,tmax为最大迭代次数,le表示莱维飞行策略因子,le定义公式中的c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,g是大小为1×d维的服从正态分布的随机向量。
75、可选的,所述改进蜣螂优化方法在觅食行为阶段基于改进自适应收敛因子改进的公式如下:
76、
77、lbb=max(xb×(1-r),lb);
78、ubb=min(xb×(1-r),ub);
79、
80、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),t表示迭代次数,tmax为最大迭代次数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,xb表示全局最优位置。
81、可选的,所述改进蜣螂优化方法在觅食行为阶段基于动态权重策略因子和莱维飞行策略因子改进的公式如下:
82、
83、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
84、
85、c1=2grg(1-t/tmax);
86、
87、
88、γ(x)=(x-1)!;
89、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),ω表示动态权重策略因子,ω_max=ubb;ω_min=lbb,t表示迭代次数,tmax为最大迭代次数,le表示莱维飞行策略因子,le定义公式中的c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,g是大小为1×d维的服从正态分布的随机向量。
90、可选的,所述改进蜣螂优化方法在觅食行为阶段基于动态权重策略因子和改进自适应收敛因子改进的公式如下:
91、
92、lbb=max(xb×(1-r),lb);
93、ubb=min(xb×(1-r),ub);
94、
95、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置;lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),ω表示动态权重策略因子,ω_max=ubb,ω_min=lbb,t表示迭代次数,tmax为最大迭代次数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,xb表示全局最优位置。
96、可选的,所述改进蜣螂优化方法在觅食行为阶段基于莱维飞行策略因子和改进自适应收敛因子改进的公式如下:
97、
98、
99、c1=2grg(1-t/tmax);
100、
101、
102、γ(x)=(x-1)!;
103、lbb=max(xb×(1-r),lb);
104、ubb=min(xb×(1-r),ub);
105、
106、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),t表示迭代次数,tmax为最大迭代次数,le表示莱维飞行策略因子,le定义公式中的c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,xb表示全局最优位置,g是大小为1×d维的服从正态分布的随机向量。
107、可选的,所述改进蜣螂优化方法在觅食行为阶段基于动态权重策略因子、莱维飞行策略因子以及改进自适应收敛因子改进的公式如下:
108、
109、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
110、
111、c1=2grg(1-t/tmax);
112、
113、
114、γ(x)=(x-1)!;
115、lbb=max(xb×(1-r),lb);
116、ubb=min(xb×(1-r),ub);
117、
118、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),ω表示动态权重策略因子,ω_max=ubb,ω_min=lbb,t表示迭代次数,tmax为最大迭代次数,le表示莱维飞行策略因子,le定义公式中的c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,xb表示全局最优位置,g是大小为1×d维的服从正态分布的随机向量。
119、可选的,所述负荷数据预测模型是通过以下步骤训练得到的:
120、获取用户样本负荷数据集;
121、将所述用户样本负荷数据集划分成训练集和验证集;其中,所述训练集中包括多个用户训练负荷数据,所述验证集中包括多个用户验证负荷数据;
122、重复执行以下循环步骤,直至达到预设迭代次数,确定所述负荷数据预测模型最终的模型参数;
123、所述循环步骤包括:
124、获取经过数据初始化的所述改进蜣螂优化方法计算的蜣螂种群信息;
125、基于所述蜣螂种群信息设置所述负荷数据预测模型的模型参数;
126、将所述用户训练负荷数据输入至所述负荷数据预测模型,得到所述负荷数据预测模型输出的训练负荷数据预测结果;
127、基于所述训练负荷数据预测结果和所述用户验证负荷数据,计算损失函数。
128、另一方面,本发明实施例还提供一种用户负荷数据预测装置,包括:
129、数据获取模块,用于获取用户负荷数据;
130、数据预测模块,用于将所述用户负荷数据输入至负荷数据预测模型,得到所述负荷数据预测模型输出的用户负荷数据预测结果;
131、其中,所述负荷数据预测模型的模型参数是基于改进蜣螂优化方法训练得到的;所述改进蜣螂优化方法是在繁殖行为阶段和/或觅食行为阶段,基于用于增强全局寻优能力的动态权重策略因子、莱维飞行策略因子以及改进自适应收敛因子中的至少一种因子改进得到的;所述负荷数据预测模型是基于用户训练负荷数据和用户验证负荷数据训练得到的。
132、可选的,所述改进蜣螂优化方法在繁殖行为阶段基于动态权重策略因子、莱维飞行策略因子以及改进自适应收敛因子改进的公式如下:
133、
134、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
135、
136、c1=2grg(1-t/tmax);
137、
138、
139、γ(x)=(x-1)!;
140、lb*=max(x*×(1-r),lb);
141、ub*=min(x*×(1+r),ub);
142、
143、其中,ω表示动态权重策略因子,x*表示当前局部最优位置,lb*和ub*分别表示产卵的下界和上界,b1和b2是两个独立的大小为1×d维的随机向量,范围是(0,1),ω_max=ub*,ω_min=lb*,t表示迭代次数,tmax为最大迭代次数,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,le表示莱维飞行策略因子,c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,t表示迭代次数,tmax为最大迭代次数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,g是大小为1×d维的服从正态分布的随机向量。
144、可选的,所述改进蜣螂优化方法在觅食行为阶段基于动态权重策略因子、莱维飞行策略因子以及改进自适应收敛因子改进的公式如下:
145、
146、ω=0.5*tanh(-2π*t/tmax+π)+0.5*(ω_max+ω_min);
147、
148、c1=2grg(1-t/tmax);
149、
150、
151、γ(x)=(x-1)!;
152、lbb=max(xb×(1-r),lb);
153、ubb=min(xb×(1-r),ub);
154、
155、其中,xit+1表示迭代次数为t+1次第i只蜣螂的位置,xti表示迭代次数为t次第i只蜣螂的位置,lbb和ubb分别表示最佳觅食区域的下界和上界,c1表示服从正态分布的随机数,c2表示1*d的随机向量,范围是(0,1),ω表示动态权重策略因子,ω_max=ubb,ω_min=lbb,t表示迭代次数,tmax为最大迭代次数,le表示莱维飞行策略因子,le定义公式中的c1表示随机跳跃度,用来衡量莱维飞行的强度,xrt是第t次迭代中某一个随机的蜣螂位置,r是一个(0,1)之间的随机数,μ,v是服从正态分布的随机数,β是一个常数,r表示改进自适应收敛因子,lb和ub分别表示优化问题的下界和上界,xb表示全局最优位置,g是大小为1×d维的服从正态分布的随机向量。
156、可选的,用户负荷数据预测装置,还包括:
157、样本获取模块,用于获取用户样本负荷数据集;
158、划分模块,用于将所述用户样本负荷数据集划分成训练集和验证集;其中,所述训练集中包括多个用户训练负荷数据,所述验证集中包括多个用户验证负荷数据;
159、控制模块,用于重复执行以下循环步骤,直至达到预设迭代次数,确定所述负荷数据预测模型最终的模型参数;
160、所述循环步骤包括:
161、获取经过数据初始化的所述改进蜣螂优化方法计算的蜣螂种群信息;
162、基于所述蜣螂种群信息设置所述负荷数据预测模型的模型参数;
163、将所述用户训练负荷数据输入至所述负荷数据预测模型,得到所述负荷数据预测模型输出的训练负荷数据预测结果;
164、基于所述训练负荷数据预测结果和所述用户验证负荷数据,计算损失函数。
165、另一方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述用户负荷数据预测方法。
166、另一方面,本发明还提供一种机器可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述用户负荷数据预测方法。
167、另一方面,本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述用户负荷数据预测方法。
168、通过上述技术方案,针对现有蜣螂优化算法的繁殖行为与觅食行为易导致算法陷入局部最优的缺陷,本发明的改进蜣螂优化方法在繁殖行为阶段和/或觅食行为阶段,基于用于增强全局寻优能力的动态权重策略因子、莱维飞行策略因子以及改进自适应收敛因子中的至少一种因子进行改进,以此来提升蜣螂优化算法的全局寻优能力。本发明通过采用改进蜣螂优化方法对负荷数据预测模型的模型参数进行优化,负荷数据预测模型的抗过拟合性能强,从而提高模型的预测精度。
169、本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!