视频处理方法、装置、设备、介质及产品与流程
本申请涉及计算机,尤其涉及人工智能,具体涉及一种视频处理方法、一种视频处理装置、一种计算机设备、一种计算机可读存储介质以及一种计算机程序产品。
背景技术:
1、文本、图像、视频是互联网中主要的几种信息源,相较于文本和图像,视频能承载更多信息,更容易吸引和引导用户。大部分视频都会通过字幕来辅助表达,而视频的字幕内容也可以服务于视频检索、视频审核、视频字幕翻译等视频处理任务,因此,视频字幕识别技术有着广泛的应用场景。
2、实践发现,对于电视剧和电影等视频场景,由于视频字幕的出现位置(如通常展示在界面的中心偏下的位置)、大小(如不超过一行,字体为五号楷体)、数量(如各个视频帧均包含一个视频字幕)都比较固定,因而判断字幕区域(用于展示字幕的图像区域)容易实现,以至于视频字幕识别的准确率较高。但像广告视频、短视频、教学视频、应用展示视频、幻灯片展示视频等视频场景,其视频字幕识别具有以下难点:①视频字幕具有不规律性(例如,视频字幕的数量、大小、出现位置都会发生变化)和不连续性(例如,视频字幕可能会发生一段时间的消失);②视频的播放时长较短(例如广告视频一般小于30秒)、画面背景复杂、文字众多;③同一视频帧中多行字幕并存;④难以定义视频中的字幕区域。目前,还没有成熟的视频字幕识别技术来解决这些难点,因此如何准确地识别视频的字幕内容仍是亟待解决的问题。
技术实现思路
1、本申请实施例提供了一种视频处理方法、装置、设备、介质及产品,能准确地识别视频的字幕内容。
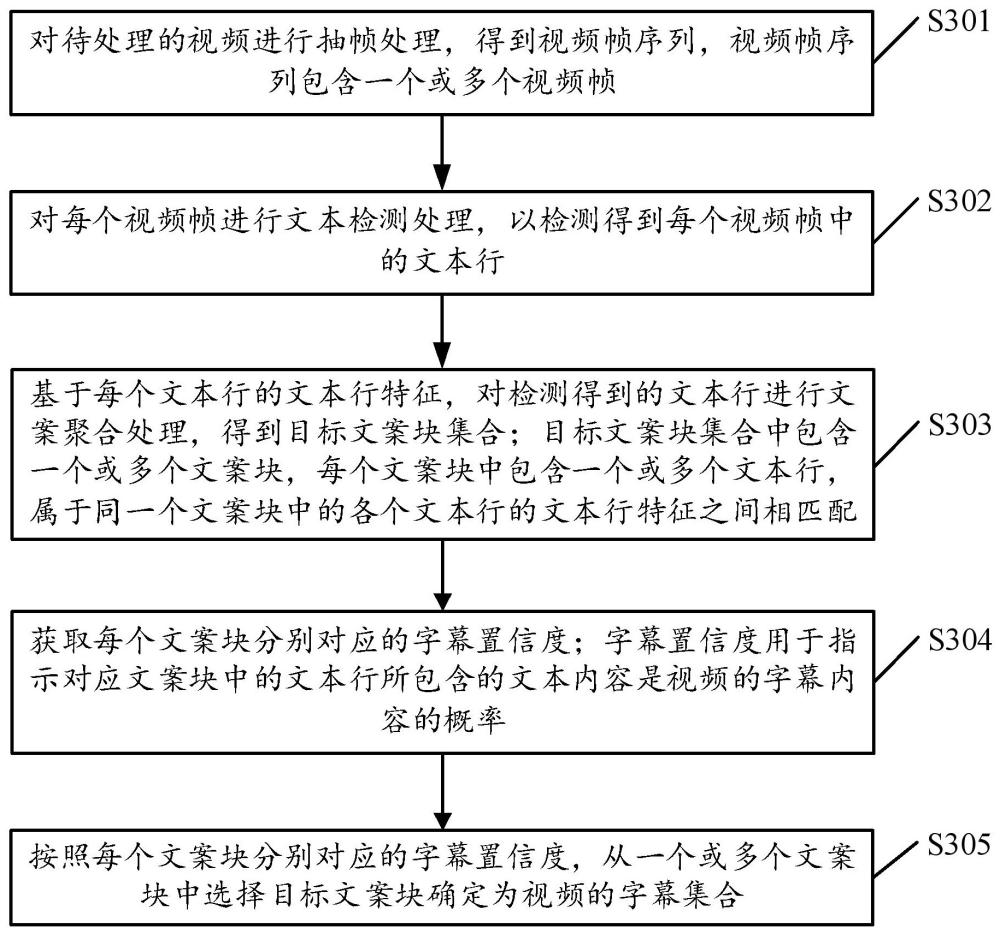
2、一方面,本申请实施例提供了一种视频处理方法,该视频处理方法包括:
3、对待处理的视频进行抽帧处理,得到视频帧序列,视频帧序列包含一个或多个视频帧;
4、对每个视频帧进行文本检测处理,以检测得到每个视频帧中的文本行;
5、基于每个文本行的文本行特征,对检测得到的文本行进行文案聚合处理,得到目标文案块集合;目标文案块集合中包含一个或多个文案块,每个文案块中包含一个或多个文本行,属于同一个文案块中的各个文本行的文本行特征之间相匹配;
6、获取每个文案块分别对应的字幕置信度;字幕置信度用于指示对应文案块中的文本行所包含的文本内容是视频的字幕内容的概率;
7、按照每个文案块分别对应的字幕置信度,从一个或多个文案块中选择目标文案块确定为视频的字幕集合。
8、相应地,本申请实施例提供了一种视频处理装置,该视频处理装置包括:
9、处理单元,用于对待处理的视频进行抽帧处理,得到视频帧序列,视频帧序列包含一个或多个视频帧;
10、处理单元,还用于对每个视频帧进行文本检测处理,以检测得到每个视频帧中的文本行;
11、处理单元,还用于基于每个文本行的文本行特征,对检测得到的文本行进行文案聚合处理,得到目标文案块集合;目标文案块集合中包含一个或多个文案块,每个文案块中包含一个或多个文本行,属于同一个文案块中的各个文本行的文本行特征之间相匹配;
12、获取单元,用于获取每个文案块分别对应的字幕置信度;字幕置信度用于指示对应文案块中的文本行所包含的文本内容是视频的字幕内容的概率;
13、处理单元,还用于对按照每个文案块分别对应的字幕置信度,从一个或多个文案块中选择目标文案块确定为视频的字幕集合。
14、相应地,本申请实施例提供一种计算机设备,该计算机设备包括:
15、处理器,适于实现计算机程序;
16、计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序适于由处理器加载并执行上述的视频处理方法。
17、相应地,本申请实施例提供一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被计算机设备的处理器读取并执行时,使得计算机设备执行上述的视频处理方法。
18、相应地,本申请实施例提供了一种计算机程序产品,该计算机程序产品包括计算机程序,该计算机程序存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机程序,处理器执行该计算机程序,使得该计算机设备执行上述的视频处理方法。
19、本申请实施例中,通过对待处理的视频进行抽帧处理可得到视频帧序列,对视频帧序列中的每个视频帧进行文本检测处理,可检测得到每个视频帧中的文本行;可见,本申请借助成熟的单视频帧的文本检测技术,能够快速提取视频帧中的文本行,从而提升视频处理的效率。基于每个文本行的文本行特征,对每个文本行进行文案聚合处理,得到目标文案块集合;目标文案块集合中包含一个或多个文案块,每个文案块中包含一个或多个文本行,属于同一文案块中的各个文本行的文本行特征之间相匹配。由于文本行特征用于表征相应文本行,通过基于文本行特征进行文案聚合处理可实现将视频帧序列中相匹配的文本行聚合至同一个文案块中,这样就可以定位出视频帧中稳定出现文本的区域(即文案块对应的文本区域)。获取每个文案块分别对应的字幕置信度,该字幕置信度指示对应文案块中的文本行所包含的文本内容是视频的字幕内容的概率;也就是说,字幕置信度可用于指示对应文案块所对应的文本区域是视频的字幕区域的概率;那么,按照每个文案块分别对应的字幕置信度,从一个或多个文案块中选择目标文案块确定为视频的字幕集合,即目标文案块对应的文本区域可以理解为是视频的字幕区域,相应地,该目标文案块中包含的文本行中的文本内容则为视频的字幕内容,通过上述这样的方式,就能通过字幕集合中的各个文本行所包含的文本内容得到视频的字幕内容,实现视频字幕的准确识别。
技术特征:
1.一种视频处理方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,所述视频帧序列包含r个视频帧,每个所述视频帧具备各自的抽帧时刻,所述r个视频帧按照抽帧时刻的先后顺序排列;所述视频帧序列中任一个视频帧表示为第i视频帧,所述第i视频帧具备抽帧时刻t,且从所述第i视频帧检测得到j个文本行;i、r、t和j均为正整数,且i小于或等于r;
3.如权利要求2所述的方法,其特征在于,所述基于所述j个文本行中每个文本行的文本行特征,对所述j个文本行进行帧内文案匹配处理,得到所述抽帧时刻t对应的第一文案块集合,包括:
4.如权利要求2所述的方法,其特征在于,所述基于所述j个文本行中每个文本行的文本行特征和所述第二文案块集合中的各个文案块的文案块特征,将所述j个文本行与所述第二文案块集合中的各个文案块进行帧间文案匹配处理,得到所述抽帧时刻t对应的第一文案块集合,包括:
5.如权利要求4所述的方法,其特征在于,所述基于所述j个文本行中每个文本行的文本行特征和所述第二文案块集合中的各个文案块的文案块特征,对所述j个文本行和所述第二文案块集合中的各个文案块进行匹配处理,包括:
6.如权利要求2-5中任一项所述的方法,其特征在于,所述j个文本行中任一个文本行表示为文本行j;j为小于或等于j的正整数;
7.如权利要求2-5中任一项所述的方法,其特征在于,所述第二文案块集合中的任一个文案块表示为文案块p;p为正整数;
8.如权利要求1所述的方法,其特征在于,所述视频帧序列中任一个视频帧表示为第i视频帧;i为小于或等于r的正整数;
9.如权利要求8所述的方法,其特征在于,所述至少一个备选文本行中任一个备选文本行表示为备选文本行k;k为正整数且小于或等于至少一个备选文本行的总数;
10.如权利要求9所述的方法,其特征在于,所述初始字符序列包括间隔符;所述基于所述初始字符序列和所述初始字符序列中各个字符分别对应的字符置信度,确定所述备选文本行k对应的文本置信度,包括:
11.如权利要求9所述的方法,其特征在于,所述初始字符序列中第m个字符是所述文本概率分布矩阵的第m列中最大取值对应的字符;
12.如权利要求1所述的方法,其特征在于,所述目标文案块集合中任一个文案块表示为文案块p,p为正整数;
13.如权利要求1所述的方法,其特征在于,所述视频帧序列中的目标视频帧包含有所述目标文案块中的文本行;所述方法还包括:
14.如权利要求13所述的方法,其特征在于,所述方法还包括:
15.一种视频处理装置,其特征在于,包括:
16.一种计算机设备,其特征在于,所述计算机设备包括:
17.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序适于由处理器加载并执行如权利要求1-14中任一项所述的视频处理方法。
18.一种计算机程序产品,其特征在于,所述计算机程序产品包括计算机程序,所述计算机程序被处理器执行时实现如权利要求1-14中任一项所述的视频处理方法。
技术总结
本申请实施例提出了一种视频处理方法、装置、设备、介质及产品,该方法包括:对待处理的视频进行抽帧处理,得到视频帧序列,视频帧序列包含一个或多个视频帧;对每个视频帧进行文本检测处理,以检测得到每个视频帧中的文本行;基于每个文本行的文本行特征,对检测得到的文本行进行文案聚合处理,得到目标文案块集合;目标文案块集合中包含一个或多个文案块,每个文案块中包含一个或多个文本行,属于同一个文案块中的各个文本行的文本行特征之间相匹配;获取每个文案块分别对应的字幕置信度;按照每个文案块分别对应的字幕置信度,从一个或多个文案块中选择目标文案块确定为视频的字幕集合。本申请实施例能准确地识别视频的字幕内容。
技术研发人员:李昊曦,郭春超,刘思聪,刘威,蒋杰,顾曼
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!