一种基于多类别指数损失函数的不平衡数据软分类方法
本发明涉及不平衡数据集的软分类,尤其是涉及一种基于多类别指数损失函数的不平衡数据软分类方法。
背景技术:
1、随机配置神经网络(scns)是一种增量式快速建模方式,其网络结构由一个隐含层节点利用“数据依赖”的监督机制随机配置隐含层节点输入权重和偏置,逐渐增加隐含层节点个数,并使用最小二乘方法计算输出权重,完成网络构建,其克服了传统随机模型参数选择的问题,也不同于基于梯度下降的神经网络,在近年来在模式识别、故障检测和系统建模与预测等领域展现了显著的优势。
2、但scns作为分类识别器,特别是多分类问题时,其本质是构建网络拟合0-1标签矩阵,其主要问题如下:
3、1)现有的技术通过网络输出矩阵与0-1标签矩阵的差值来作为网络残差进行更新,当评估网络输出与0-1标签矩阵的均方根误差(rmse)达到预先设定的值时,网络停止更新;获取预测类别时,采用硬分类方式,直接取网络输出值最大的为真实类别。这样scns应用于分类问题时,每个样本只能属于一个类别,对于很多问题而言,过于武断且无法应用于同一个样本具有多个类别属性的场景,限制了scns的应用范围。
4、2)此外scns网络的监督机制加强了隐藏层输入权重和偏置与网络的残差及样本之间的约束关系,网络输出与标签矩阵的残差成为了配置隐藏层输入权重和偏置的重要依据。现有的技术通过将网络的输出与标签矩阵直接作差作为当前网络的残差,但在实际应用中网络的输出代表的实际意义应是属于各类别的概率分布,这样即可获取样本属于该类别或其他类别的概率值,可以更全面的描述样本的特征,例如一张图片中可能包含狗又包含草地,要想获得全面的样本信息,网络应该逼近的是一种概率分布而非0-1矩阵,现有的残差更新方式可以用于衡量两个概率分布的相似度,但也使得网络输出并非概率分布。
5、3)当scns基于不平衡数据集生成分类识别模型时,模型会显著的过拟合样本数量多的类别,而现实场景中无论是故障诊断和灾难预测,或是模式识别的问题,所采样的数据集通常都是不平衡的。而现有的基于不平衡数据集改进的scns模型如文(qu hq,feng tl,wangyp,zhangy.adaboost-scn algorithm for optical fiber vibration signalrecognition.applied optics,2019,58(21):5612–5623.[doi:10.1364/ao.58.005612])基于adaboost的改进scns,或文(dai,w.,ning,c.,nan,j.et al.stochasticconfigurationnetworks for imbalanced data classification.int.j.mach.learn.&cyber.13,2843–2855(2022).https://doi.org/10.1007/s13042-022-01565-z)引入类别平衡器来使得网络建模时关注少数类样本,但其仅能解决二分类问题中的不平衡数据集问题,事实上像模式识别或故障诊断任务中,往往不止两种情况待分类识别。
6、4)在机器学习领域解决不平衡数据集问题已有许多成熟的算法,如gbdt和adaboost,为解决该类问题提供了良好的思路,但其本质是二分类,即每次分出一类,假如有k个类别则需要训练k个分类器,且在使用时弱分类器的数量需要预先设定,如果过小导致模型欠拟合,如果过大则会导致模型过拟合,因此对于不熟悉该领域的使用者来讲,该超参数难以确定。
技术实现思路
1、本发明的目的是提供一种基于多类别指数损失函数的不平衡数据软分类方法,通过引入softmax层和交叉熵损失重新评估网络的建模程度,以解决使用rmse作为评估指标时,异常值对于该指标的影响;通过引入交叉熵度量模型预测与真实概率分布之间的差异,scns新增节点的权重依据交叉熵来进行选择,而非两个模型预测的概率分布与真实概率分布的差值作为更新依据,克服了原有方法直接作差得到没有实际意义的包含负值的或大于1的网络概率残差矩阵;最后通过引入多类别指数损失函数(samme)和停止建模条件,来实现一次性多分类和自动选择弱分类器个数的目的。
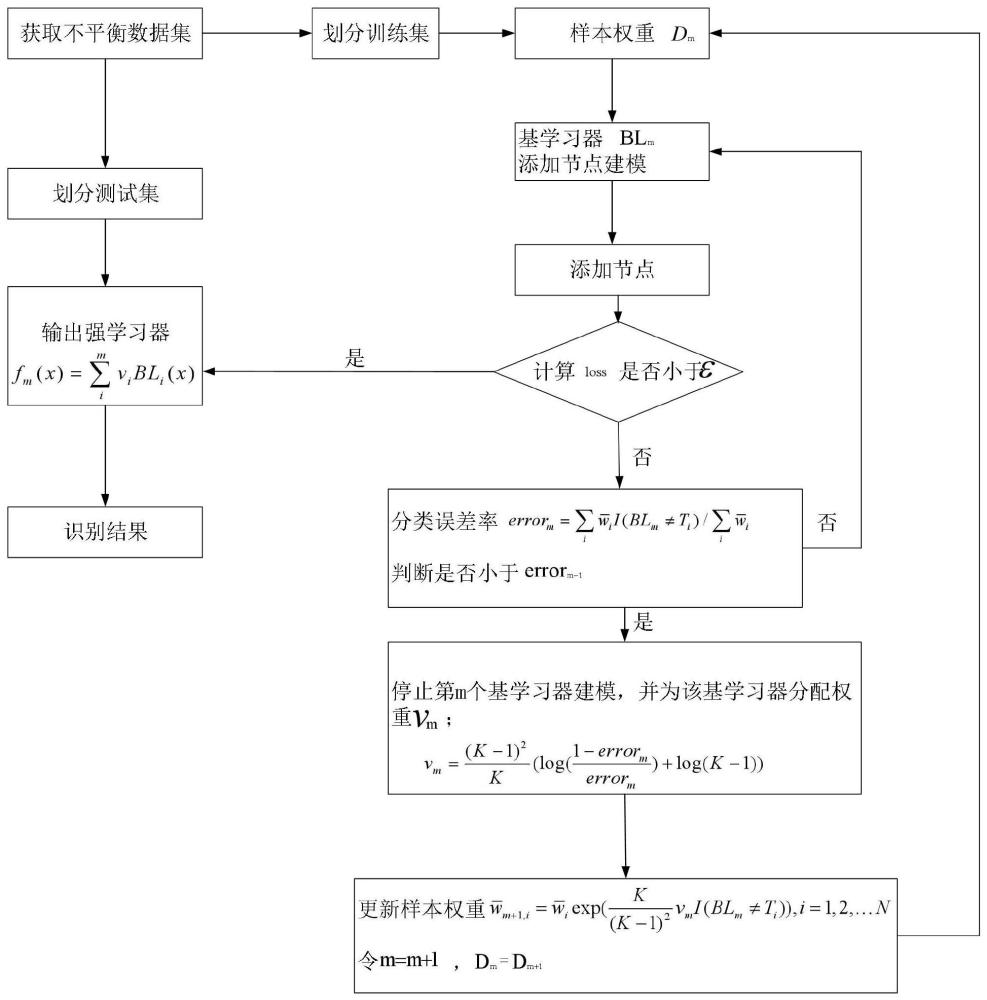
2、为实现上述目的,本发明提供了一种基于多类别指数损失函数的不平衡数据软分类方法,步骤如下:
3、s1、加载不平衡数据类,样本数量为n,类别为m,识别数据集标签列,将其转化为0-1标签矩阵t,并将不平衡数据类划分为训练集和测试集;
4、s2、根据样本权重dm训练第m个弱学习器blm;
5、s3、由约束公式计算监督指标并添加最佳节点;
6、s4、计算输出权重β*得到网络输出;
7、s5、更新网络残差,评估当前建模情况;
8、s6、更新目标函数,计算并判断模型的loss是否小于给定的容差ε,若小于给定的容差ε,则整体建模过程结束并更新样本权重,否则进入步骤s7;
9、s7、计算当前样本权重的计算分类误差率。
10、优选的,步骤s2中,根据样本权重dm训练第m个弱学习器blm具体为:
11、s21、建立第m个弱学习器blm的l-1层隐藏节点的网络,则第m个弱学习器blm的网络输出表示为:
12、
13、式中wj=[wj1,...,wjd]t,bj=[bj1,...,bjd]t分别为隐含层节点的输入权重和偏置,βj=[βj1,...,βjm]t为隐藏层与输出层之间的输出权重,gj代表激活函数,此处为sigmoid激活函数;
14、s22、将步骤s21中的网络输出经过softmax层处理,即设定其输出的每个类别概率分布预测值和严格为1,且不存在超过1的概率和负值概率,则经过softmax层处理后的网络输出表示为:
15、
16、式中各参数含义与式(1)相同。
17、优选的,步骤s3中,由约束公式计算监督指标并添加最佳节点,具体为:
18、从可调区间中随机生成输入权重wl和偏置bl,并计算监督指标:
19、
20、其中,||·||表示frobenius范数,此时,el-1,q代表建模第l-1个节点时,输出所对应的网络残差,r为缩放因子,ul小于等于(1-r);根据从候选节点池中将监督指标ξl取得最大值时的隐藏节点更新到网络中。
21、优选的,步骤s4中,计算输出权重β*得到网络输出,具体为:
22、根据约束不等式挑选出的最佳节点,使用最小二乘法计算输出权重:
23、
24、其中,h为隐藏层输出,t为标签矩阵:
25、hht代表非奇异矩阵,h=[h1,h2,....,hl]t。
26、优选的,步骤s5中,更新网络残差,评估当前建模情况,具体为:
27、s51、根据式(2)的网络输出表达式,采用交叉熵更新网络残差el-1,更新后的网络残差表达式为:
28、
29、s52、根据步骤s51中更新后的网络残差,采用交叉熵损失来评估当前阶段建模情况,交叉熵损失的计算公式为:
30、
31、优选的,步骤s6中,更新目标函数:
32、
33、计算模型的loss,若小于给定的容差ε,则整体建模过程结束,否则进入步骤s7,其中,bl代表基学习器,v代表基学习器在最后输出中所占比重。
34、优选的,步骤s7中,若模型当前loss大于给定的容差ε,则通过监督指标blm添加节点,并计算当前样本权重下blm的分类误差率errorm,分类误差率计算公式如下:
35、
36、若errorm-1>errorm,则停止继续在第m个模型上添加节点,保存第m个模型的参数,根据当前样本权重计算出的errorm,为第m个模型分配权重vm:
37、
38、其中k表示样本的类别个数;
39、更新样本权重dm+1:
40、
41、令m=m+1,dm=dm+1,
42、则第m+1个模型基于继续建模;
43、若errorm-1<errorm,返回步骤s3继续寻找并节点并更新,直到整体满足预设误差,建模过程结束。
44、因此,本发明采用上述一种基于多类别指数损失函数的不平衡数据软分类方法,有益效果如下:
45、(1)本发明基于熵更新建模速度快,学习逼近能力更强,将scns从硬分类扩展到软分类并没有增加计算时间,相同节点下准确率更高,说明学习到的特征更加有效。
46、(2)本发明对少数类样本识别准确率更高,自动根据建模情况建立弱分类器个数的目的,无须人工调整;后续分类准确率越高的分类器被分配的权重也越来越大,使得误分类样本被关注度越来越高,改善了样本不平衡对模型识别准确度的影响。
47、(3)本发明基于熵更新和使用交叉熵作为评估标准,使网络输出值变为了概率分布,很好的将scns从只能硬分类转变成了软分类方法,并且可以应用于多标签分类问题;在实际应用中可根据概率值来判断其真实类别,辅助使用者更加全面的了解了样本的特征,增加了实用性。
48、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!