基于混合注意力机制和Transformer模型的DenseNet路面状态图像识别方法
本发明属于路面状态图像识别技术,具体涉及一种基于混合注意力机制和transformer模型的densenet路面状态图像识别方法。
背景技术:
1、道路材料特性以及路面平整度对道路交通安全具有直接影响,特别是在雨雪等恶劣天气条件下,导致路面出现积雪、冰冻、湿滑等多种恶劣路面状态,这些情况往往是引发交通事故的主要原因之一。因此,迅速而准确地识别和判断路面状态,并在道路状况存在危险时及时向驾驶人员发出预警,对于实现道路的高效且安全通行具有重要的现实意义。
2、基于图像处理技术识别路面状态己成为当前研究热点,这种方法利用车载摄像头或者交通监控摄像头捕捉道路图像,然后通过图像处理、计算机视觉和深度学习等技术来判定当前路面的状况,随后对危险路段发出预警。然而,目前还没有一个公认的识别准确度高、实时性好、鲁棒性强的方法能很好的解决道路路况图像识别的问题。
3、传统图像识别方法通常采用线性分类器或浅层模型,难以捕捉图像中复杂的非线性关系。在处理大规模和复杂的图像数据集时,这种限制容易导致性能下降,即传统图像识别方法在大规模数据集上的训练和推理能力相对较弱。此外,传统的图像特征提取方法需要手动设计用于图像识别的特征,这种特征设计依赖人工经验,方法不够灵活且无法充分利用图像中的潜在信息。此外,由于传统方法中的特征是基于手动设计的,因此其泛化能力受到限制,在处理复杂场景、不同视角或光照条件下的图像时可能表现不佳,难以适应多样性和变化性。
4、因此,以路面状态图像为研究对象,针对道路路况图像识别准确率低的问题,提出一种基于混合注意力机制和transformer模型的densenet路面状态图像识别方法。
技术实现思路
1、本发明的目的在于提供一种基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,通过在通道域和空间域中建立并行的混合注意力机制模型p-cbam,提高网络对主次信息的表征能力。将p-cbam加入fpn特征金字塔顶层中,结合transformer模型中的自注意力机制,理解全局的上下文信息。有效的提升了路面图像识别的准确率,适用于要求高精度路面识别场合的情况下使用。
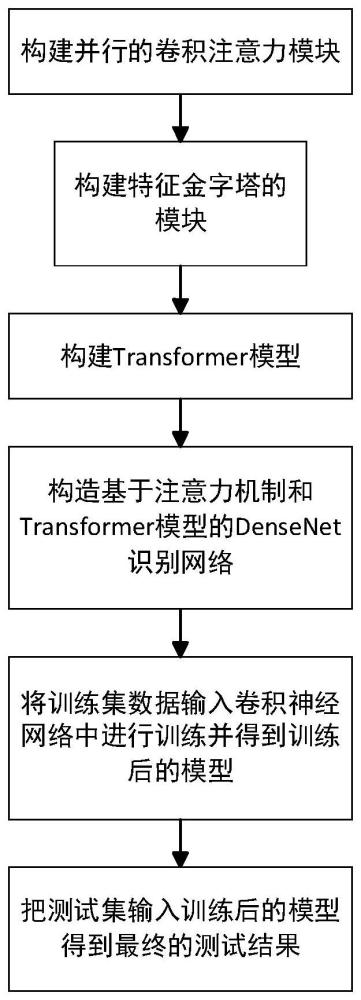
2、实现本发明目的的技术解决方案为:第一方面,本发明提供一种基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,包括以下步骤:
3、步骤s1、构造通道域和空间域并行的卷积注意力模块;
4、步骤s2、将注意力引入fpn特征金字塔中,构造fpn特征金字塔模块;
5、步骤s3、构造transformer模块;
6、步骤s4、将步骤2和步骤3的fpn特征金字塔模块和transformer模型结合,引入densenet网络中构造路面状态识别网络;
7、步骤s5、将生成的训练集数据输入到步骤4构造好的网络进行训练;
8、步骤s6、将预先构建的测试集数据输入到步骤5训练好的网络中测试目标分类的准确率。
9、第二方面,本发明提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述的方法的步骤。
10、第三方面,本发明提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如第一方面所述的方法的步骤。
11、第四方面,本发明提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器技行时实现如第一方面所述的方法的步骤。
12、本发明与现有技术相比,其显著优点为:1)将通道注意力cam和空间注意力sam模块并行连接,使得原始特征能够同时通过通道注意力和空间注意力模块,能够最大程度的保留原始特征图中的信息;2)引入的特征金字塔结构将不同尺度的特征有效整合,融合特征图为模型提供更全面、更丰富的多尺度信息,使模型能够更好地理解图像的上下文,更好地理解图像中的语义结构;此外,多尺度特征融合有助于提高模型的泛化性能,减少过拟合的风险;3)cnn与transformer模型网络相结合,从而增强整体网络模型的特征提取能力,使其能够更全面地捕获局部图像细节和全局语义信息,显著提升了网络模型的分类准确率,并增强了其在面对各种场景时的鲁棒性。
13、下面结合附图对本发明进一步详细描述。
技术特征:
1.一种基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,其特征在于,步骤s1所构造的通道域和空间域并行的卷积注意力模块,输入特征f∈rc×h×w,并行输入通道注意力模块cam一维卷积mc∈rc×1×1和空间注意力模块sam二维卷积ms∈r1×h×w,将两部分输出结果与原图相乘,得到最终的输出其中,r表示实数域,c表示特征通道数,h×w表示特征尺寸。
3.根据权利要求1所述的基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,其特征在于,步骤s2所构建的结合步骤s1注意力机制的fpn特征金字塔,将注意力机制模块引入特征金字塔的顶层,使得特征提取网络所提取的最高层特征c5在经过1×1卷积后再经过一个注意力机制模块,通过fpn自上而下的2倍上采样将其转化为更清晰的特征,与经过注意力机制模块后的特征图进行侧边连接融合,最后使用3×3的卷积以消除图像融合的混叠效应。
4.根据权利要求1所述的基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,其特征在于,步骤s4设计的基于残差模块改进的densenet神经网络结构共包括10个网络层级,依次为:第一卷积层、第一池化层、残差块、第一过渡层、第一密集块、第二过渡层、第二密集块、第三过渡层、第三密集块、分类层;其中第一卷积层卷积核尺寸为7×7,滑动步长设置为2;第一池化层为最大池化,池化窗口尺寸为3×3,滑动步长设置为2;残差块包括4个残差层,残差层为1×1卷积、3×3卷积和1×1卷积;过渡层为平均池化,池化窗口尺寸为2×2,滑动步长设置为2;密集层为1×1卷积和3×3卷积,第一密集块包括12个密集层;第二密集块包括24个密集层;第三密集块包括16个密集层;分类层包括flatten层将多维数据扁平化为一维数据,6类全连接层,dropout层和softmax输出层。
5.根据权利要求4所述的基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,其特征在于,步骤s5具体为:将8000个路面状态图像构成的训练数据集作为网络的输入,对步骤s4所得的网络进行训练,训练网络采样的优化器为自适应矩估计优化器,采用的损失函数为focal loss损失函数。
6.根据权利要求5所述的基于混合注意力机制和transformer模型的densenet路面状态图像识别方法,其特征在于,将2000个路面状态图像构成的测试数据集输入到步骤s4训练好的模型进行图像分类的准确率测试。
7.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-6中任一所述的方法的步骤。
8.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-6中任一所述的方法的步骤。
9.一种计算机程序产品,包括计算机程序,其特征在于,该计算机程序被处理器技行时实现权利要求1-6中任一所述的方法的步骤。
技术总结
本发明公开了一种基于混合注意力机制和Transformer模型的DenseNet路面状态图像识别方法,包括:基于残差结构改进DenseNet网络作为骨干网络;建立并行的卷积注意力机制模块,将注意力模块引入FPN特征金字塔中,并将改进后的特征金字塔加入特征提取网络;构建Transformer模块,将Transformer模型与DenseNet网络结合,进行长距离建模;在Tensorflow学习框架下,利用训练集训练提出的网络模型,再用测试集验证效果,完成路面状态图像的识别。本发明通过注意力模块提高网络对主次信息的表征能力,DenseNet网络引入特征金字塔并结合Transformer模型,能够增强整体网络模型的特征提取能力,使得网络能够同时利用深层和浅层信息,提升网络对语义信息的理解和表达能力,进而显著提升了网络模型的分类准确率。
技术研发人员:王清华,胥靖雯,宋旸,来建成,李振华
受保护的技术使用者:南京理工大学
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!