一种融合论据和结构信息的事件因果关系识别方法
本发明涉及信息抽取及事件因果识别,具体地说是一种基于多任务学习框架的融合论据和结构信息的事件因果关系识别方法。
背景技术:
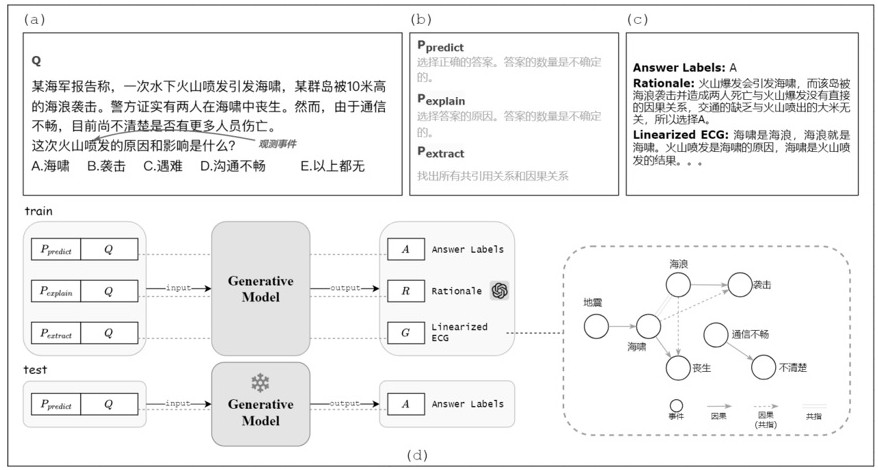
1、文档级事件因果关系识别(deci)旨在识别文档中两个事件之间的因果关系,是信息提取中的一项重要而困难的任务。因果关系提取的研究有助于我们解决许多实际问题。如海量信息的自动处理,进而支持未来事件预测、知识图构建和全球危机监测等丰富的下游应用。如图1所示,事件“喷发”导致“海啸”,因此可以认为这两个事件具有因果关系。事件提及“海浪”和事件提及“海啸”指的是同一事件,因此可以认为是共指关系。
2、大型语言模型(llm)的最新进展引起了人们对将这些模型应用于各种语言任务的极大兴趣,例如模型编辑,模型提取和参数有效微调。然而,在因果事件提取的任务中,最近的研究倾向于使用预先训练的语言模型来生成事件因果关系。然而,由于文档中的多个事件,这些方法容易出现顺序生成错误、性能有限和成本高昂。在大型语言模型快速发展的时代,这些传统方法的潜力受到了严重限制,即使添加了组件,实现显著的突破性性能似乎也是一项艰巨的挑战。
3、论文《event causality identification via generation of importantcontext words》提出了geneci,使用生成模型(t5)通过捕获关键上下文单词来推断事件之间的因果关系。然而,geneci使用真问题或假问题来确定两个事件之间的因果关系,这导致了高时间成本,并且仅适用于句子级别的提取。论文《seag:structure-aware eventcausality generation》提出seag,将事件检测和事件因果关系识别相结合,通过线性化和对比学习方法证明了事件因果图结构线性化的有效性。然而,seag不适用于标记事件的因果提取,并且单独标记事件词或重新提及事件很难有效提高其在已知事件因果提取中的性能。同时,现有的生成方法仅通过监督模板生成结果,语言模型可能无法理解为什么这种提取是正确的。所以,在实践中,如何在限制的时间和计算成本下,有效并且有依据地进行因果关系合理提取仍然是当前需要解决的一个挑战。
4、现有技术的事件因果关系识别基于编码器的预训练模型和图神经网络变体,使用预先训练的语言模型来生成事件因果关系,时间成本高。使用预先训练的语言模型来生成事件因果关系,由于文档中的多个事件,容易出现顺序生成错误。此外,还忽略了事件共指和相关因果链等潜在结构。
技术实现思路
1、本发明的目的是针对现有技术的不足而提供的一种融合论据和结构信息的事件因果关系识别方法,采用多任务学习框架及构建线性化事件因果关系结构图,使用decoder-only的生成大语言模型将因果关系提取转化为一个可以通过自然语言生成解决的任务,通过基本论据和结构信息感知的因果问题回答来增强事件因果关系识别,将事件对之间的因果识别转换为多项选择题,对于每一个事件,都将其称为“观察到的事件”,询问列出的选项中的哪一个是其因果关系,并将智能模型提供的可靠论据与构建的线性化事件因果关系图相结合,旨在提取重要的上下文关键信息,并增强重要事件关系提及信息作为间接监督,从而提高其选择的准确性,该方法通过将deci任务转换为多项选择题回答,利用大型语言模型生成事件因果关系,提高了识别的精确性和效率。另外,该方法还提供了解释事件因果关系的论据,增强了模型的可解释性,引入了事件结构图来建模因果推理的多跳潜在关系,从而更全面地捕捉事件之间的因果联系,为文档级事件因果关系识别领域带来了新的前沿和突破。方法简便,使用效果好,同时适应有限的计算成本和可接受的时间,具有良好的运用前景和商业价值。
2、实现本发明目的的具体技术方案是:一种融合论据和结构信息的事件因果关系识别方法,其特征在于,对待问题文本进行裁切,对待训练集和测试集进行问题的选项构建,利用多任务训练方法,融合智能模型生成的论据和构建的结构信息到多选题qa,进行多任务训练,对模型进行微调,具体包括下述步骤:
3、(一)数据准备
4、1-1:将事件对之间的因果识别转换为多项选择题,对于每一个事件,都将其称为“观察到的事件”,询问列出的选项中的哪一个是其因果关系。
5、1-2:对待问题文本进行裁切修剪,仅保留观察到的事件和候选事件的开头和结尾部分,以减少文本中的噪音,排除不相关事件的影响。
6、1-3:对待训练集和测试集进行题目选项构建,对于训练集,所有具有因果关系的事件被纳入选项。若存在共指事件,则选取与观察事件最接近的,同时添加至少三个无关的事件作为干扰项。对于测试集,将每个事件作为观察到的事件依次迭代,每个事件集都作为选项提及;所述训练集和测试集源于开源数据集,并经训练集与测试集按8:2比例分割得到的。
7、1-4:将上述构建的训练集用于训练多选题qa模型,多选题qa模型是基于开源的baichuan2-7b-chat生成模型,并将根据问题生成答案作为我们的主要任务,测试集用于评估多选题qa模型的性能表现。
8、(二)融合智能模型生成的论据
9、人为地获取更智能模型的论据并注入训练模型作为辅助任务之一,当模型被训练时,作为预测答案的监督工具,融合更智能的模型提供的可靠论据,旨在提取重要的上下文关键信息。
10、(三)融合结构信息
11、根据事件的位置对其进行排序,以更自然的语言方式结合事件共指和因果关系,使用因果图结构线性化方法,得到自然语句描述的事件因果图结构,融合构建的线性化事件因果关系图,即结构信息作为另一辅助任务,旨在增强重要事件关系提及信息作为间接监督。
12、(四)模型的训练和优化
13、对待融合智能模型生成的论据和构建的结构信息到多选题qa模型,进行多任务训练,对模型进行微调,同一生成模型同时学习三个任务,并进行训练以最小化损失。
14、本发明与现有技术相比具有将deci任务转换为多项选择题回答,利用大型语言模型生成事件因果关系,提高了识别的精确性和效率。另外,该方法还提供了解释事件因果关系的论据,增强了模型的可解释性,引入了事件结构图来建模因果推理的多跳潜在关系,从而更全面地捕捉事件之间的因果联系,为文档级事件因果关系识别领域带来了新的前沿和突破,方法简便,使用效果好,同时适应有限的计算成本和可接受的时间,具有良好的运用前景和商业价值。
技术特征:
1.一种融合论据和结构信息的事件因果关系识别方法,其特征在于,采用多任务学习框架,将融合智能模型生成的论据和构建的结构信息到多选题qa,通过基本论据和结构信息感知的因果问题回答来增强事件因果关系识别,具体包括下述步骤:
技术总结
本发明公开了一种融合论据和结构信息的事件因果关系识别方法,其特点是采用多任务学习框架,通过基本论据和结构信息感知的因果问题回答来增强事件因果关系识别;将文档级事件因果关系识别转化为多项选择题生成式问答,并融合论据和结构信息,使用大型语言模型生成被质疑事件的因果关系,该方法具体包括:数据准备、论据生成、结构信息和模型训练等步骤。本发明与现有技术相比具有识别精确性和效率高的优点,为文档级事件因果关系识别领域带来了新的前沿和突破,方法简便,使用效果好,同时适应有限的计算成本和可接受的时间,具有良好的运用前景和商业价值。
技术研发人员:陈琴,张白岩,周杰,金健,贺樑
受保护的技术使用者:华东师范大学
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!