基于人工智能的数字化企业服务数据挖掘方法及系统与流程
本技术涉及人工智能,具体而言,涉及一种基于人工智能的数字化企业服务数据挖掘方法及系统。
背景技术:
1、在现有技术中,服务对话系统常常应用于数字化企业服务中。这些服务对话系统通常通过多轮的服务对话来理解和满足用户的需求。为了提升服务对话系统的效果,需要对服务对话进行分析和理解,挖掘出用户的服务需求意图。
2、目前,多数方法主要依赖监督学习进行对话文本的分析。这种方法通常需要大量标注好的训练数据。然而,在实际应用中,获取足够多的标注数据是困难的,同时人工标注的过程也十分耗时和昂贵。此外,由于服务对话的内容复杂且多变,仅依靠监督学习可能无法充分理解和挖掘对话内容。
3、针对上述问题,一些方法尝试引入非监督学习进行对话文本的分析。然而,如何有效地利用非监督学习对话文本,以及如何结合监督学习对话文本和非监督学习对话文本,仍是一个待解决的问题。
技术实现思路
1、为了至少克服现有技术中的上述不足,本技术的目的在于提供一种基于人工智能的数字化企业服务数据挖掘方法及系统,能够在缺乏足够标注数据的情况下,利用非监督学习方法进行服务意图挖掘。同时,还考虑了多轮对话中的上下文信息,提高了服务意图挖掘的准确性。
2、第一方面,本技术提供一种基于人工智能的数字化企业服务数据挖掘方法,所述方法包括:
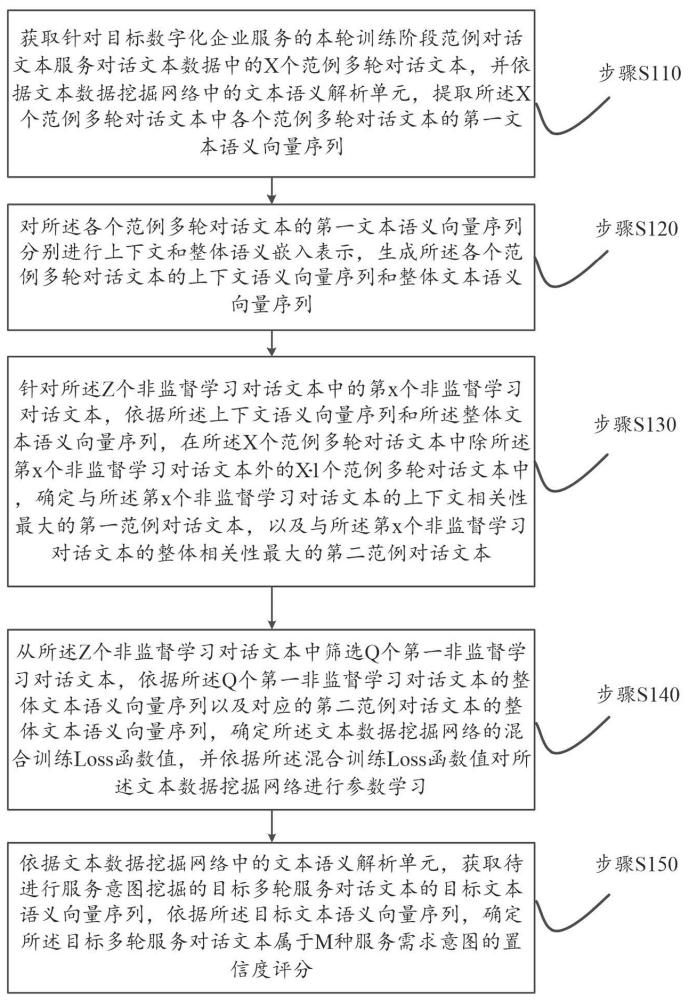
3、获取范例对话文本服务对话文本数据中的x个范例多轮对话文本,并依据文本数据挖掘网络中的文本语义解析单元,提取所述x个范例多轮对话文本中各个范例多轮对话文本的第一文本语义向量序列,所述范例对话文本服务对话文本数据为在本轮训练阶段中针对目标数字化企业服务的对话文本服务对话文本数据,所述x个范例多轮对话文本包括y个监督学习对话文本和z个非监督学习对话文本,y和z为大于0的整数,且x等于y与z的相加值,所述文本数据挖掘网络用于对多轮服务对话文本中关键对话节点的服务需求意图进行挖掘;
4、对所述各个范例多轮对话文本的第一文本语义向量序列分别进行上下文和整体语义嵌入表示,生成所述各个范例多轮对话文本的上下文语义向量序列和整体文本语义向量序列;
5、针对所述z个非监督学习对话文本中的第x个非监督学习对话文本,依据所述上下文语义向量序列和所述整体文本语义向量序列,在所述x个范例多轮对话文本中除所述第x个非监督学习对话文本外的x-1个范例多轮对话文本中,确定与所述第x个非监督学习对话文本的上下文相关性最大的第一范例对话文本,以及与所述第x个非监督学习对话文本的整体相关性最大的第二范例对话文本,所述x为不大于z的正整数;
6、从所述z个非监督学习对话文本中筛选q个第一非监督学习对话文本,依据所述q个第一非监督学习对话文本的整体文本语义向量序列以及对应的第二范例对话文本的整体文本语义向量序列,确定所述文本数据挖掘网络的混合训练loss函数值,并依据所述混合训练loss函数值对所述文本数据挖掘网络进行参数学习,所述第一非监督学习对话文本为对应的第一范例对话文本和对应的第二范例对话文本相同的非监督学习对话文本;
7、依据文本数据挖掘网络中的文本语义解析单元,获取待进行服务意图挖掘的目标多轮服务对话文本的目标文本语义向量序列,依据所述目标文本语义向量序列,确定所述目标多轮服务对话文本属于m种服务需求意图的置信度评分,所述m为不小于2的正整数。
8、在第一方面的一种可能的实施方式中,所述依据所述上下文语义向量序列和所述整体文本语义向量序列,在所述x个范例多轮对话文本中除所述第x个非监督学习对话文本外的x-1个范例多轮对话文本中,确定与所述第x个非监督学习对话文本的上下文相关性最大的第一范例对话文本,以及与所述第x个非监督学习对话文本的整体相关性最大的第二范例对话文本,包括:
9、依据所述x个范例多轮对话文本中每两个范例对话文本的上下文语义向量序列,确定所述每两个范例对话文本之间的上下文相关性,以及依据所述每两个范例对话文本的整体文本语义向量序列,确定所述每两个范例对话文本之间的整体相关性;
10、依据所述第x个非监督学习对话文本与所述x-1个范例多轮对话文本中各个范例多轮对话文本之间的上下文相关性,在所述x-1个范例多轮对话文本中提取与所述第x个非监督学习对话文本的上下文相关性最大的第一范例对话文本;
11、依据所述第x个非监督学习对话文本与所述x-1个范例多轮对话文本中各个范例多轮对话文本之间的整体相关性,在所述x-1个范例多轮对话文本中提取与所述第x个非监督学习对话文本的整体相关性最大的第二范例对话文本。
12、在第一方面的一种可能的实施方式中,所述依据所述x个范例多轮对话文本中每两个范例对话文本的上下文语义向量序列,确定所述每两个范例对话文本之间的上下文相关性,包括:
13、针对所述x个范例多轮对话文本中的第y个范例多轮对话文本和第z个范例多轮对话文本,依据所述第y个范例多轮对话文本的上下文语义向量序列,确定所述第y个范例多轮对话文本的上下文关注系数,以及依据所述第z个范例多轮对话文本的上下文语义向量序列,确定所述第z个范例多轮对话文本的上下文关注系数,所述y和z均为不大于x的正整数,且y不等于x;
14、依据所述第y个范例多轮对话文本的上下文语义向量序列和上下文关注系数,以及所述第z个范例多轮对话文本的上下文语义向量序列和上下文关注系数,确定所述第y个范例多轮对话文本与所述第z个范例多轮对话文本之间的上下文相关性。
15、在第一方面的一种可能的实施方式中,所述依据所述q个第一非监督学习对话文本的整体文本语义向量序列以及对应的第二范例对话文本的整体文本语义向量序列,确定所述文本数据挖掘网络的混合训练loss函数值,包括:
16、针对所述q个第一非监督学习对话文本中的各个第一非监督学习对话文本,依据所述第一非监督学习对话文本的整体文本语义向量序列和所述第一非监督学习对话文本对应的第二范例对话文本的整体文本语义向量序列,确定所述第一非监督学习对话文本的第一训练代价参数;
17、依据所述q个第一非监督学习对话文本中各个第一非监督学习对话文本对应的第一训练代价参数,确定非监督训练代价参数;
18、针对所述y个监督学习对话文本中的各个监督学习对话文本,若在所述y个监督学习对话文本中除所述监督学习对话文本外的y-1个监督学习对话文本中,存在与所述监督学习对话文本的标注服务意图数据相同的第三范例对话文本时,则依据所述监督学习对话文本的整体文本语义向量序列和所述第三范例对话文本的整体文本语义向量序列,确定所述监督学习对话文本的第二训练代价参数,依据至少一个监督学习对话文本的第二训练代价参数,确定监督训练代价参数;
19、依据所述非监督训练代价参数和所述监督训练代价参数,生成第一loss函数值;
20、依据所述文本数据挖掘网络中的全连接层,对所述x个范例多轮对话文本中各个范例多轮对话文本的第一文本语义向量序列进行处理,生成所述x个范例多轮对话文本中的各个范例多轮对话文本属于m种服务需求意图的第一置信度评分,依据所述x个范例多轮对话文本中至少一个范例多轮对话文本的第一置信度评分,确定第二loss函数值,所述m为大于1的正整数;
21、依据所述第一loss函数值和所述第二loss函数值,确定所述混合训练loss函数值。
22、在第一方面的一种可能的实施方式中,所述第二loss函数值包括第一成员loss函数值,所述依据所述x个范例多轮对话文本中至少一个范例多轮对话文本的第一置信度评分,确定第二loss函数值,包括:
23、对所述z个非监督学习对话文本中各个非监督学习对话文本的第一置信度评分进行假设监督标记训练,生成所述z个非监督学习对话文本中各个非监督学习对话文本的第一模糊服务意图标注数据;
24、依据所述z个非监督学习对话文本中各个非监督学习对话文本的第一模糊服务意图标注数据和所述第一置信度评分,生成所述第一成员loss函数值。
25、在第一方面的一种可能的实施方式中,所述依据所述z个非监督学习对话文本中各个非监督学习对话文本的第一模糊服务意图标注数据和所述第一置信度评分,生成所述第一成员loss函数值,包括:
26、确定所述第x个非监督学习对话文本的第一模糊服务意图标注数据中,置信度评分最大的第一服务需求意图;
27、将所述第x个非监督学习对话文本的第一置信度评分中,所述第一服务需求意图对应的置信度评分,输出为所述第x个非监督学习对话文本的训练学习指标;
28、将所述第x个非监督学习对话文本的第一模糊服务意图标注数据和所述第一置信度评分进行点乘,生成目标参数值,将所述目标参数值进行对数运算后与所述第x个非监督学习对话文本的训练学习指标进行乘积运算,生成所述第x个非监督学习对话文本对应的第三训练代价参数;
29、依据所述z个非监督学习对话文本中各个非监督学习对话文本对应的第三训练代价参数,生成所述第一成员loss函数值。
30、在第一方面的一种可能的实施方式中,所述第二loss函数值包括第二成员loss函数值,所述依据所述x个范例多轮对话文本中至少一个范例多轮对话文本的第一置信度评分,确定第二loss函数值,包括:
31、依据所述y个监督学习对话文本中各个监督学习对话文本的第一置信度评分和标注服务意图数据,确定所述第二成员loss函数值。
32、在第一方面的一种可能的实施方式中,所述第二loss函数值包括第三成员loss函数值,所述依据所述x个范例多轮对话文本中至少一个范例多轮对话文本的第一置信度评分,确定第二loss函数值,包括:
33、依据所述x个范例多轮对话文本中各个范例多轮对话文本的第一置信度评分,确定所述第三成员loss函数值;
34、所述依据所述x个范例多轮对话文本中各个范例多轮对话文本对应的置信度评分,确定所述第三成员loss函数值,包括:
35、依据所述x个范例多轮对话文本中各个范例多轮对话文本的第一置信度评分,确定所述x个范例多轮对话文本的平均置信度评分;
36、针对所述x个范例多轮对话文本中的各个范例多轮对话文本,确定所述范例多轮对话文本的第一置信度评分和所述平均置信度评分之间的离散程度值;
37、依据所述x个范例多轮对话文本中各个范例多轮对话文本对应的离散程度值,确定所述第三成员loss函数值。
38、在第一方面的一种可能的实施方式中,所述依据文本数据挖掘网络中的文本语义解析单元,提取所述x个范例多轮对话文本中各个范例多轮对话文本的第一文本语义向量序列之前,所述方法还包括:
39、使用所述y个监督学习对话文本,对所述文本数据挖掘网络进行初始化参数学习;
40、所述依据文本数据挖掘网络中的文本语义解析单元,提取所述x个范例多轮对话文本中各个范例多轮对话文本的第一文本语义向量序列,包括:
41、通过初始化参数学习后的所述文本数据挖掘网络中的文本语义解析单元,提取所述x个范例多轮对话文本中各个范例多轮对话文本的第一文本语义向量序列;
42、在所述依据所述混合训练loss函数值对所述文本数据挖掘网络进行参数学习之后,所述方法还包括:
43、对所述z个非监督学习对话文本进行聚类,生成所述z个非监督学习对话文本中各个非监督学习对话文本的第二模糊服务意图标注数据;
44、依据所述y个监督学习对话文本,以及所述z个非监督学习对话文本和第二模糊服务意图标注数据,对依据所述混合训练loss函数值进行参数学习后的所述文本数据挖掘网络进行进阶参数学习。
45、第二方面,本技术还提供一种基于人工智能的数字化企业服务数据挖掘系统,所述基于人工智能的数字化企业服务数据挖掘系统包括处理器和机器可读存储介质,所述机器可读存储介质中存储有计算机程序,所述计算机程序结合该处理器加载并执行以实现以上第一方面的基于人工智能的数字化企业服务数据挖掘方法。
46、采用以上任意方面的技术方案,能够有效提取和理解多轮对话文本中的语义信息,具体通过获取目标数字化企业服务的范例对话文本数据,并利用文本数据挖掘网络中的文本语义解析单元,从各个范例对话文本中提取出第一文本语义向量序列。同时,它将这些对话文本分类为监督学习对话文本和非监督学习对话文本,进而实现上下文和整体语义嵌入表示的生成。此外,还针对非监督学习对话文本,依据其上下文语义向量序列和整体文本语义向量序列,找出与之相关性最大的范例对话文本,有助于更准确地识别和理解非监督学习对话文本的语义内容。此外,通过筛选非监督学习对话文本,并结合相应的范例对话文本确定混合训练loss函数值,实现了对文本数据挖掘网络进行参数学习,优化了网络性能。最后,根据目标多轮服务对话文本的目标文本语义向量序列,确定该对话文本属于不同服务需求意图的置信度评分,从而有效实现服务需求意图的识别和挖掘。这种方法能够提高文本数据挖掘网络对服务对话文本中服务需求意图的理解和把握,进一步提升服务质量。
- 还没有人留言评论。精彩留言会获得点赞!