一种模型训练方法、数据处理方法和装置与流程
本发明涉及数据处理,特别涉及一种模型训练方法、数据处理方法和装置。
背景技术:
1、现有的点云深度学习域适应领域,尤其是采用自训练模式的方法,大多采用基于源域数据预训练好的模型来推理生成目标域数据的伪标签,然后利用目标域数据及其伪标签来微调预训练好的模型。
2、目标域数据与源域数据的分布通常存在较大的差异,但目标域里的不同数据与源域数据的差异程度是不同的。源域数据通常带有人工标注真值标签,而目标域数据没有。往往源域数据和目标域数据存在着差异,比如包括数据场景不同、(激光)雷达安装位置不同、(激光)雷达线束不同等,因此直接使用基于源域数据训练的模型在目标域进行推理,导致推理得到的结果的精确度低。
技术实现思路
1、针对上述现有技术的缺点,本发明提供了一种模型训练方法、数据处理方法和装置,模型训练方式为对源域数据和所述目标域数据进行差异程度划分,并根据划分后的结果进行逐级训练的模型微调训练方式,即通过模型微调的训练方式得到目标模型,降低域适应过程的难度,让目标模型更好地适应目标任务的数据和任务需求,提高目标模型的精度,从而提高通过目标模型对数据进行推理得到的结果的精确度。
2、为了实现上述目的,其公开的技术方案如下:
3、本技术第一方面公开了一种模型训练方法,包括:
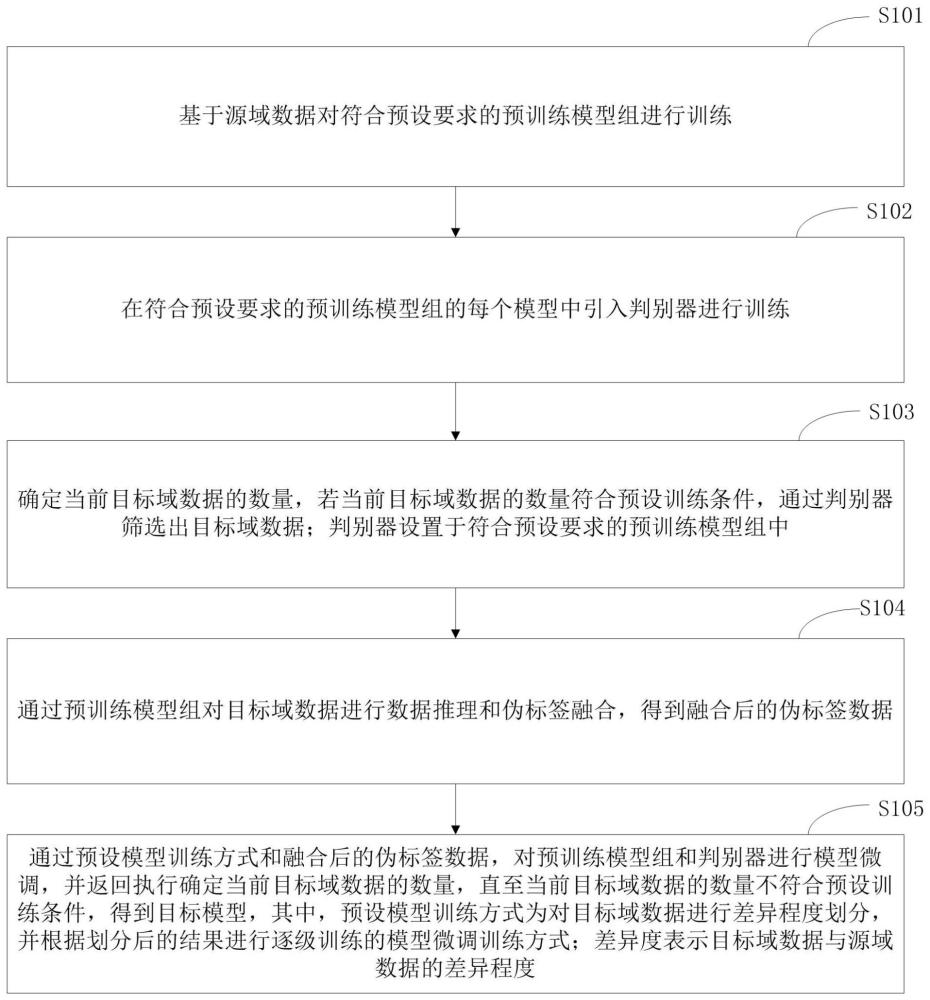
4、确定当前目标域数据的数量,若当前目标域数据的数量符合预设训练条件,通过判别器筛选出目标域数据;所述判别器设置于符合预设要求的预训练模型组中;
5、通过所述预训练模型组对所述目标域数据进行数据推理和伪标签融合,得到融合后的伪标签数据;
6、通过预设模型训练方式和融合后的伪标签数据,对所述预训练模型组和所述判别器进行模型微调,并返回执行确定当前目标域数据的数量,直至当前目标域数据的数量不符合所述预设训练条件,得到目标模型;其中,所述预设模型训练方式为对所述目标域数据进行差异程度划分,并根据划分后的结果进行逐级训练的模型微调训练方式;差异度表示所述目标域数据与源域数据的差异程度。
7、可选的,所述确定当前目标域数据的数量,若当前目标域数据的数量符合预设训练条件,通过判别器筛选目标域数据,包括:
8、确定当前目标域数据的数量,若当前目标域数据的数量大于预设阈值,通过判别器对当前目标域数据进行推理,得到每一帧目标域数据的多组概率值;
9、通过预设聚类方式对每一帧目标域数据的多组概率值进行聚类,得到待执行伪标签融合的伪标签数据和目标域数据。
10、可选的,所述通过所述预训练模型对所述目标域数据进行数据推理和伪标签融合,得到融合后的伪标签数据,包括:
11、通过所述预训练模型对所述目标域数据进行推理,得到多组推理结果;
12、通过预设分类方式对所述多组推理结果进行分类,得到各个类别信息;
13、针对每一个类别信息,将类别信息的目标框中心位置信息和目标框中心位置信息对应搜索半径内的其他目标框作为初始集合;
14、若初始集合中存在重复的目标框,对初始集合中重复的目标框进行删除操作;
15、统计删除操作后的初始集合中剩余的目标框的个数;
16、当所述目标框的个数大于等于预设个数阈值时,将所述目标框的个数大于等于预设个数阈值所对应的初始集合确定为待融合的目标框集合;所述预设个数阈值由推理结果的组数确定;
17、通过预设确定方式确定待融合的目标框集合中的预设融合数据;所述预设融合数据至少包括融合后的目标框类别数据、融合后的目标框中心位置数据、融合后的目标框航向角数据、融合后的目标框三维信息和融合后的置信度;
18、根据所述预设融合数据对融合的目标框集合进行融合,得到融合后的伪标签数据。
19、可选的,所述通过预设确定方式确定待融合的目标框集合中的预设融合数据,包括:
20、统计待融合的目标框集合中的目标框所属类别信息,从目标框所属类别信息中选取数量最多的类别作为融合后的目标框类别数据;
21、统计待融合的目标框集合中每个中心位置的概率密度,选取概率密度最大的作为融合后的目标框中心位置;
22、统计待融合的目标框集合中每个航向角的概率密度,选取概率密度最大的作为融合后的目标框航向角;
23、统计待融合的目标框集合中所有目标框的三维信息的最小值和最大值,并基于三维信息的最小值和最大值,线性生成多组三维信息值;
24、统计多组三维信息值的概率密度,选取概率密度最大的三维信息值作为融合后的目标框三维信息;
25、统计待融合的目标框集合的置信度的概率密度,选取概率密度最大的置信度作为融合后的置信度。
26、可选的,所述通过预设模型训练方式和融合后的伪标签数据,对所述预训练模型组和所述判别器进行模型微调,并返回执行确定当前目标域数据的数量,直至当前目标域数据的数量不符合所述预设训练条件,得到目标模型,包括:
27、通过预设模型训练方式和融合后的伪标签数据,对所述预训练模型和所述判别器进行模型微调,并返回执行确定当前目标域数据的数量;
28、当前目标域数据的数量小于等于预设阈值时,确定当前目标域数据的数量不符合所述预设训练条件;
29、在当前目标域数据的数量不符合所述预设训练条件下,通过符合预设要求的预训练模型组对由所述判别器最近一轮筛选出的目标域数据进行推理,得到多组第一推理结果;
30、按照预设融合方式对所述多组第一推理结果进行伪标签融合;
31、基于源域数据和由所述多组第一推理结果融合得到的伪标签数据,对符合预设要求的预训练模型组的模型权重进行第一轮微调;
32、通过符合预设要求的预训练模型组对由所述判别器筛选出的所有目标域数据进行推理,得到多组第二推理结果;
33、按照预设融合方式对所述多组第二推理结果进行伪标签融合;
34、基于源域数据和由所述多组第二推理结果融合得到的伪标签数据,对完成第一轮微调的预训练模型组的模型权重进行第二轮微调,得到目标模型。
35、可选的,符合预设要求的预训练模型组的训练过程,包括:
36、针对符合预设要求的预训练模型组的每一个检测模型,通过检测模型的三维主干网络模块对获取到的点云数据进行编码,并利用三维稀疏卷积对编码后的点云数据进行三维特征提取,得到点云数据的三维特征;
37、通过预训练模型组的二维主干网络模块将点云数据的三维特征转换到bev空间,并利用二维卷积对bev空间的三维特征进行二维特征提取,得到点云数据的二维特征;
38、通过预训练模型组的密集特征提取模块对所述点云数据的二维特征进行密集特征提取,得到预测结果并输出,以完成符合预设要求的预训练模型组的训练过程。
39、可选的,对所述目标域数据进行差异程度划分的过程,包括:
40、通过判别器对当前目标域数据进行推理,得到每一帧目标域数据的多组概率值;
41、通过预设聚类方式对每一帧目标域数据的多组概率值进行聚类,得到待执行伪标签融合的伪标签数据和目标域数据,完成对目标域数据进行差异程度划分的过程。
42、本技术第二方面公开了一种数据处理方法,适用于第一方面任一项的模型训练方法得到的目标模型,所述数据处理方法包括:
43、实时采集点云数据;
44、通过所述目标模型,对所述点云数据进行处理,得到推理结果;
45、通过所述目标模型和预设排序方式将所述推理结果进行排序,得到排序结果;
46、通过所述目标模型和预设选取方式从所述排序结果中选取得到伪标签数据;
47、将所述伪标签数据反馈至车辆的决策端,以实现自动驾驶的感知、决策和控制执行。
48、本技术第三方面公开了一种模型训练装置,所述模型训练装置包括:
49、确定单元,用于确定当前目标域数据的数量,若当前目标域数据的数量符合预设训练条件,通过判别器筛选出目标域数据;所述判别器设置于符合预设要求的预训练模型组中;
50、推理融合单元,用于通过所述预训练模型组对所述目标域数据进行数据推理和伪标签融合,得到融合后的第一伪标签数据;
51、获取单元,用于通过预设模型训练方式和融合后的伪标签数据,对所述预训练模型组和所述判别器进行微调,并返回执行确定当前目标域数据的数量,直至当前目标域数据的数量不符合所述预设训练条件,得到目标模型;其中,所述预设模型训练方式为对所述目标域数据进行差异程度划分,并根据划分后的结果进行逐级训练的模型微调训练方式;差异度表示所述目标域数据与源域数据的差异程度。
52、本技术第四方面公开了一种数据处理装置,适用于第三方面所述的模型训练装置得到的目标模型,所述数据处理装置包括:
53、实时采集单元,用于实时采集点云数据;
54、处理单元,用于通过所述目标模型,对所述点云数据进行处理,得到推理结果;
55、排序单元,用于通过所述目标模型和预设排序方式将所述推理结果进行排序,得到排序结果;
56、选取单元,用于通过所述目标模型和预设选取方式从所述排序结果中选取得到伪标签数据;
57、反馈单元,用于将所述伪标签数据反馈至车辆的决策端,以实现自动驾驶的感知、决策和控制执行。
58、经由上述技术方案可知,本技术公开了一种模型训练方法、数据处理方法和装置,确定当前目标域数据的数量,若当前目标域数据的数量符合预设训练条件,通过判别器筛选出目标域数据,判别器设置于符合预设要求的预训练模型组中,通过预训练模型组对目标域数据进行数据推理和伪标签融合,得到融合后的伪标签数据,通过预设模型训练方式和融合后的伪标签数据,对预训练模型组和判别器进行模型微调,并返回执行确定当前目标域数据的数量,直至当前目标域数据的数量不符合预设训练条件,得到目标模型,实时采集点云数据,通过目标模型,对点云数据进行处理,得到推理结果,通过预设排序方式将所述推理结果进行排序,得到排序结果通过预设选取方式从排序结果中选取得到伪标签数据,将伪标签数据反馈至车辆的决策端,以实现自动驾驶的感知、决策和控制执行。通过上述方案,采用将目标域数据依据和源域数据的差异程度进行划分的方式,即先处理与源域数据差异程度较小的部分数据,再处理差异程度较大的部分数据,逐步进行模型微调,通过模型微调的训练方式得到目标模型,降低域适应过程的难度,让目标模型更好地适应目标任务的数据和任务需求,提高目标模型的精度。
- 还没有人留言评论。精彩留言会获得点赞!