一种基于随机掩码和稠密匹配的3D人体姿态估计方法
本发明涉及模式识别与计算机视觉,特别是一种基于随机掩码和稠密匹配的3d人体姿态估计方法。
背景技术:
1、随着人工智能技术的不断发展,计算机视觉已经广泛应用于现实生活中的众多领域,如人脸识别、自动化驾驶等。神经网络的成熟发展,进一步扩大了人们的想象力,在多种应用场景下,使得计算机视觉相关应用更加实用便捷。在众多应用场景中,3d视频姿态估计技术具有广泛的应用前景,包括体育竞赛、健身锻炼、学习专注度等。这将使得更多的人能够享受到ai应用带来的便利,无论是在体育锻炼、学习、还是其他日常活动中,都能够得到更好的支持和指导。这个技术的研发将进一步推动计算机视觉领域的发展,为未来的应用场景提供更多可能性。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于随机掩码和稠密匹配的3d人体姿态估计方法,能够有效地对视频中的3d人体姿态进行识别。
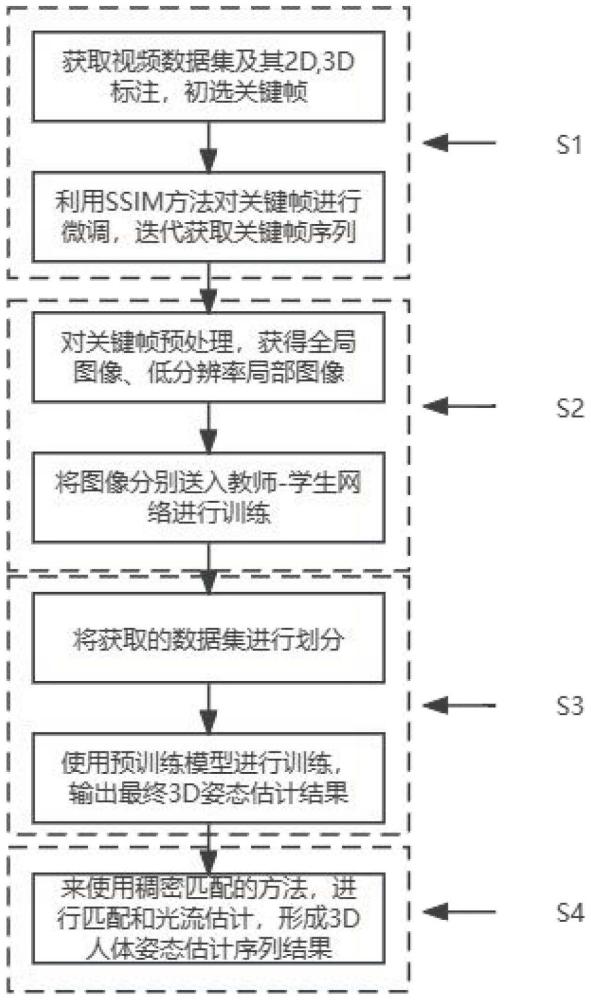
2、为实现上述目的,本发明采用如下技术方案:一种基于随机掩码和稠密匹配的3d人体姿态估计方法,其特征在于,包括以下步骤:
3、步骤s1:获取3d人体姿态估计数据集,将视频数据集拆分成图片,形成2d和3d的人体姿态估计数据,并用关键帧选取算法抽取关键帧;
4、步骤s2:利用基于随机掩码的dmformer框架,自监督进行预训练;
5、步骤s3:获取人体姿态估计数据集,划分训练集、测试集以及验证集,利用步骤s2中获得的预训练模型进一步进行训练,得到最终的3d姿态估计模型;
6、步骤s4:利用基于稠密匹配的方法,进行关键帧前后帧的稠密光流估计,完成整个视频数据集的3d姿态估计。
7、在一较佳的实施例中,所述步骤s1具体包括以下步骤:
8、步骤s11:从网上获取获取3d人体姿态估计数据集,并获取其标注;
9、步骤s12:对于视频数据集中的图像划分,给定代表视频v中共包含t帧,it代表t时刻的视频图像,提取其2d关节点真实值记为3d姿态估计真实值为
10、步骤s13:从视频序列中采用固定间隔选取的方法,提取n帧关键帧并令关键帧序列为f={f1,f2,…,fn};
11、步骤s14:利用ssim法对提取关键帧进行微调,记now为当前帧,pre为前一帧,即当前帧fnow以及序列中前一帧fpre,进行ssim计算,公式如下:
12、ssim(fnow,fpre)=[slight(fnow,fpre)*scon(fnow,fpre)*sstr(fnow,fpre)]δ)
13、
14、
15、
16、其中slight比较平均亮度的比值,scon比较对比度,sstr比较亮度协方差和亮度方差,为当前帧的亮度均值,为前一帧的亮度均值,为当前帧的亮度标准差,为前一帧的亮度标准差;δ,c1,c2,c3为常数,令阈值为r,若ssim(fnow,fpre)大于阈值,则将fpre帧替换成fnow帧,迭代最终得到最终关键帧序列s。
17、在一较佳的实施例中,所述步骤s2的具体方法为:
18、步骤s21:提出的基于随机掩码和稠密匹配的3d人体姿态估计框架dmformer,将原始数据进行裁剪,得到整体视图和低分辨率的局部视图;
19、步骤s22:对于每个训练样本,生成随机掩码randommask;掩码是一个与输入图像相同大小的矩阵,其中的某些元素被设置为0,表示掩盖或遮挡了图像的一部分;根据均匀分布生成掩码规则生成,假设每个元素生成0的概率为pmask,1的概率为1-pmask,对于一个大小为h×w的图像来说,掩码元素m(i,j)生成0的概率为:
20、p(m(i,j)=0)=pmask
21、其中i,j代表图像的坐标;
22、步骤s23:使用生成的随机掩码将低分辨率图像的一部分像素设为0,模拟不完整或者噪声输入,将整体视图it和处理后的低分辨率的局部视图in分别输入至教师编码器encodertc和学生编码器encoderstu中,损失函数包括更新损失lupdate和掩码损失lmask,公式为:
23、
24、
25、l=lupdate+lmask
26、其中,n是图像块的数量,ik代表每个图像块,mik是随机掩码,用于限制损失的计算范围,l为总的损失函数,encoderstu(in)ik代表第ik个图像块低分辨率局部视图in输入进学生编码器后的结果,encodertc(it)ik代表第ik个图像块整体视图it输入进教师编码器后的结果;通过优化上述损失函数,学生网络的编码器参数将动态更新,以使学生网络的编码器逼近教师网络的编码器。
27、在一较佳的实施例中,所述步骤s3具体包括以下步骤:
28、步骤s31:从网上获取3d姿态估计数据集human3.6,并获取其人体关键点标注,将其中的s1,s5,s6,s7作为训练集,s8,s11作为测试集进行测试;
29、步骤s32:采用步骤s2所述我们提出的基于随机掩码和稠密匹配的3d人体姿态估计框架dmformer进行训练,得到用于检测单帧人体姿态预训练模型预测结果。
30、在一较佳的实施例中,所述步骤s4中,具体包括以下步骤:
31、步骤s41:对每一对连续的关键帧之间执行稠密匹配,提取每个关键帧的sift特征描述符,对于每个2d中的关键点,将局部区域分成h个小的子区域,并在每个子区域内计算梯度直方图h,f是所有子区域直方图集合,表示为
32、f=[h1,h2…hh];
33、步骤s42:使用欧氏距离来建立特征描述符之间的关系,找到关键帧之间具有相似特征描述符的特征点对:
34、d(descriptorτ,descriptorθ)=|descriptorτ-descriptorθ|
35、其中,descriptorτ代表关键帧τ中的特征点,descriptorθ代表关键帧θ中的特征点,d(descriptorτ,descriptorθ)代表两个特征点的描述符之间的距离;
36、紧接着,利用匹配的特征点进行稠密光流估计,计算位移场:
37、
38、其中,x,y是像素的坐标,是位移向量,u(x,y)和v(x,y)分别表示像素在水平和垂直方向上的位移;
39、步骤s43:在获得像素级别的对应关系后,使用线性插值来生成两个关键帧之间的中间帧,对于每个像素(xm,ym),使用以下公式:
40、imiddle(xm,ym,e)=(1-e)*iframe1(xm,ym)+e*iframe2(xm,ym)
41、其中,imiddle(xm,ym,e)是中间帧在位置(xm,ym)处的像素值,iframe1(xm,ym)和iframe2(xm,ym)分别是两个关键帧在同一位置的像素值,e是插值参数,在[0,1]范围内;
42、步骤s44:重复上述步骤,对所有连续的关键帧对进行插值操作,生成整个视频序列的中间帧,完成整个视频数据集的3d姿态估计。
43、与现有技术相比,本发明具有以下有益效果:
44、1、能够高效地对视频中的3d人体姿态进行识别,提升了视频人体姿态估计的准确率。
45、2、能够利用ssim方法微调关键帧,使得选取更加准确,在少量增加参数量的同时,对候选帧的选取起到关键作用。
46、3、相比于传统的训练方法,使用教师-学生网络进行自监督训练,在提高准确率的同时还能增强泛化性。
47、4、针对视频逐帧检测过慢,耗时过高的问题,提出了稠密匹配和光流估计结合,恢复视频的方法,提高了检测速度。
- 还没有人留言评论。精彩留言会获得点赞!