一种预测余热锅炉蒸汽总管流量的方法
本发明涉及工业数据处理,具体涉及一种预测余热锅炉蒸汽总管流量的方法。
背景技术:
1、全球钢铁行业的碳排放随着粗钢产量稳步增长而逐年增加,然而,粗钢产量的增长促进经济发展的同时,也加剧了环境污染,示例性地,在无缝钢管的生产过程中,环形加热炉加热管坯时会产生大量高温废烟气,这造成严重的环境污染。
2、余热锅炉能够通过回收大量高温废烟气(所述高温废烟气达到400-500℃),加热除氧器处理后的水,产生大量过热蒸汽,该过热蒸汽可供应公司的蒸汽管网。
3、近年来,余热锅炉的过热蒸汽总管流量预测的常见方法分为两大类,第一类是从系统仿真的角度进行数学建模,第二类是从数据驱动的角度进行工业预测。其中,第一类是从理论上进行模拟,更适合规模简单、理论知识丰富的系统;第二类适应复杂的工业环境。
4、余热锅炉的蒸汽总管流量受余热锅炉系统中各设备参数的影响,已有大量研究从数据驱动的角度进行工业预测。然而,在预测时难以确保预测结果的准确性。
技术实现思路
1、本发明的目的是为了解决现有的余热锅炉的蒸汽总管流量受设备参数影响,预测结果准确性差的问题。
2、为了实现上述目的,本发明的第一方面提供一种预测余热锅炉蒸汽总管流量的方法,该方法包括以下步骤:
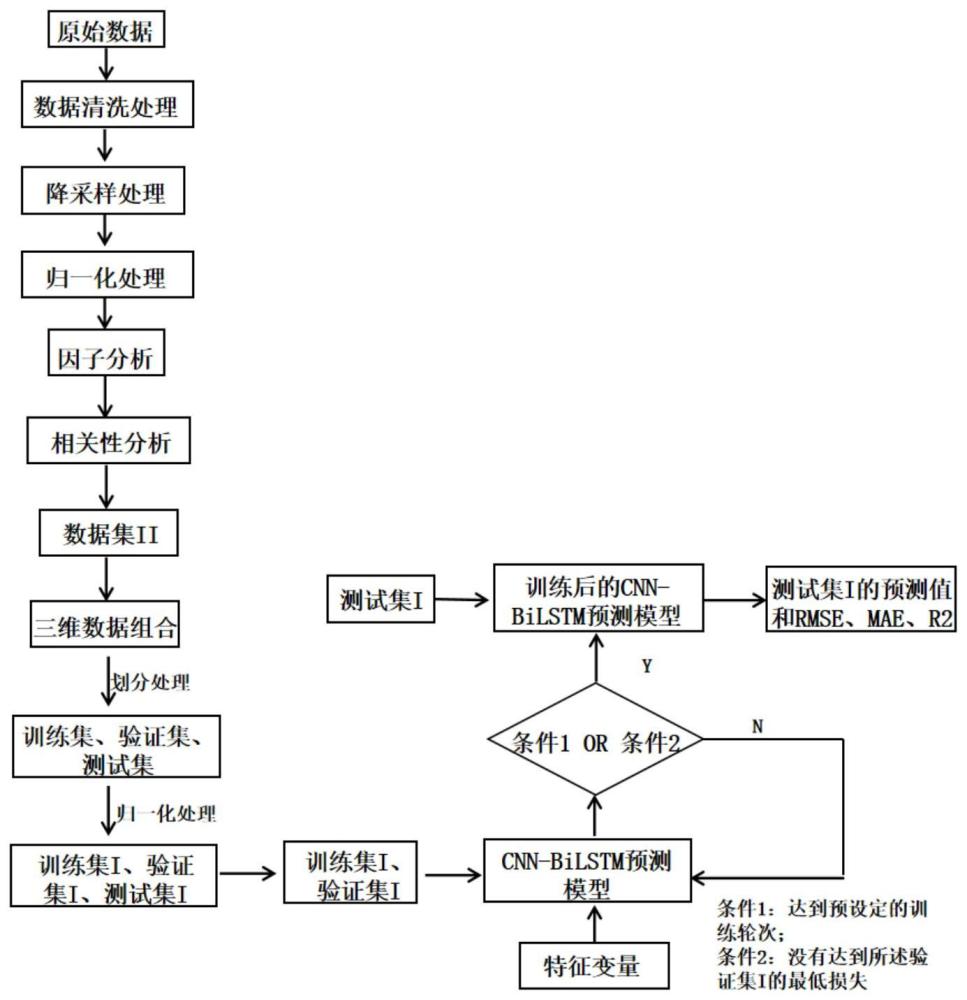
3、(1)对原始数据进行预处理,得到数据集i;
4、(2)对所述数据集i依次进行因子分析和相关性分析,得到数据集ii;
5、(3)采用所述数据集ii构建cnn-bilstm预测模型,并对所述cnn-bilstm预测模型进行训练处理,得到训练后的cnn-bilstm预测模型;
6、(4)采用所述训练后的cnn-bilstm预测模型对蒸汽总管流量进行预测,得到目标特征预测结果。
7、优选地,在步骤(1)中,所述预处理依次包括数据清洗处理、降采样处理、归一化处理。
8、进一步优选地,在步骤(1)中,该方法还包括:根据时间对经过所述预处理后的所述原始数据进行排序,再进行所述降采样处理。
9、优选地,在步骤(2)中,所述因子分析为通过提取公共因子进行;其中,所述公共因子为累计方差贡献率≥85%、对应特征值>1的因子,且各个所述公共因子中分别包括不同的特征变量。
10、更优选地,在步骤(2)中,所述相关性分析为基于所述公共因子,并分别计算蒸汽总管流量与待选特征变量、已选特征变量之间的整体相关性,再计算所述待选变量特征和所述已选变量特征之间的相关性,并优先选择总体相关性高的特征变量。
11、优选地,在步骤(2)中,所述相关性分析为根据如下表达式进行:
12、h(x)=-∑xp(x)logp(x), 式(1),
13、h(y|x)=-∑x∑yp(x,y)logp(y|x), 式(2),
14、
15、
16、i(x,y;z)=i(y;z)+i(x;z|y), 式(5),
17、所述p(x)表示边缘概率分布,所述p(x,y)表示同时选中x和y的概率分布,所述p(x,y,z)表示同时选中x、y、z的概率分布,所述p(x|z)表示z固定时x的概率分布,所述p(y|z)表示z固定时y的概率分布,所述p(x,y|z)表示表示z固定时(x,y)的概率分布,所述x为待选特征变量,所述y为已选特征变量,所述z为目标特征变量。
18、优选情况下,在步骤(3)中,所述cnn-bilstm预测模型包括cnn模型和bilstm模型,且根据如下表达式进行:
19、ft=sigmoid(wf[ht-1,xt]+bf, 式(6),
20、it=sigmoid(wi[ht--1,xt]+bi), 式(7),
21、
22、ot=sigmoid(wo[ht--1,xt]+bo), 式(9),
23、ht=ot*tanh(ct), 式(10),
24、其中,所述wf、所述wi、所述wc、所述wo分别表示t时刻的遗忘门、输入层、隐藏层、输出层的权重,所述bf、所述bi、所述bc、所述bo分别表示t时刻的遗忘门、输入层、隐藏层、输出层的偏置。
25、更优选地,在步骤(3)中,该方法还包括:将所述数据集ii重构成含有数据样本个数、时间步长、特征变量的三维数据组合,并将所述三维数据组合划分成训练集、验证集、测试集;再将所述训练集、所述验证集、所述测试集进行所述归一化处理,得到训练集i、验证集i、测试集i;
26、其中,相对于1个所述三维数据组合,所述训练集的数量为0.6个,所述验证集的数据为0.2个,所述测试集的数量为0.2个。
27、优选地,在步骤(3)中,构建所述cnn-bilstm预测模型的方法包括将所述训练集i、所述验证集i、特征变量输入至cnn-bilstm预测模型中,对所述cnn-bilstm预测模型进行训练处理,调整参数,当所述cnn-bilstm预测模型达到预设定的训练轮次,停止所述训练处理,得到训练后的cnn-bilstm预测模型,再将所述测试集i输入至所述训练后的cnn-bilstm预测模型中,得到所述测试集i的预测值和rmse、mae、r2;否则,当所述cnn-bilstm预测模型没有达到预设定的训练轮次,则继续进行所述训练处理;
28、或者当所述cnn-bilstm预测模型在连续规定训练次数内没有达到所述验证集i的最低损失mae,停止所述训练处理,得到训练后的cnn-bilstm预测模型,再将所述测试集i输入至所述训练后的cnn-bilstm预测模型中,得到所述测试集i的预测值和rmse、mae、r2;否则,当所述cnn-bilstm预测模型达到所述验证集i的最低损失,则继续进行所述训练处理。
29、优选地,在步骤(3)中,所述训练处理的条件至少满足:训练轮次为200-400次,批训练大小为16-64。
30、本发明提供的方法对神经网络预测模型的泛化能力有很大的提高,选出的30组特征变量降低了原始48组特征变量信息重叠带来的影响,能够更精准地预测蒸汽总管流量。
技术特征:
1.一种预测余热锅炉蒸汽总管流量的方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的方法,其中,在步骤(1)中,所述预处理依次包括数据清洗处理、降采样处理、归一化处理;
3.根据权利要求1或2所述的方法,其中,在步骤(2)中,所述因子分析为通过提取公共因子进行;其中,所述公共因子为累计方差贡献率≥85%、对应特征值>1的因子,且各个所述公共因子中分别包括不同的特征变量。
4.根据权利要求1-3中任意一项所述的方法,其中,在步骤(2)中,所述相关性分析为基于所述公共因子,并分别计算蒸汽总管流量与待选特征变量、已选特征变量之间的整体相关性,再计算所述待选变量特征和所述已选变量特征之间的相关性,并优先选择总体相关性高的特征变量。
5.根据权利要求1-4中任意一项所述的方法,其中,在步骤(2)中,
6.根据权利要求1-5中任意一项所述的方法,其中,在步骤(3)中,所述cnn-bilstm预测模型包括cnn模型和bilstm模型,且根据如下表达式进行:
7.根据权利要求1-6中任意一项所述的方法,其中,在步骤(3)中,该方法还包括:将所述数据集ii重构成含有数据样本个数、时间步长、特征变量的三维数据组合,并将所述三维数据组合划分成训练集、验证集、测试集;再将所述训练集、所述验证集、所述测试集进行所述归一化处理,得到训练集i、验证集i、测试集i;
8.根据权利要求6或7所述的方法,其中,在步骤(3)中,构建所述cnn-bilstm预测模型的方法包括:将所述训练集i、所述验证集i、特征变量输入至cnn-bilstm预测模型中,对所述cnn-bilstm预测模型进行训练处理,调整参数,当所述cnn-bilstm预测模型达到预设定的训练轮次,停止所述训练处理,得到训练后的cnn-bilstm预测模型,再将所述测试集i输入至所述训练后的cnn-bilstm预测模型中,得到所述测试集i的预测值和rmse、mae、r2;否则,当所述cnn-bilstm预测模型没有达到预设定的训练轮次,则继续进行所述训练处理;
9.根据权利要求1-8中任意一项所述的方法,其中,在步骤(3)中,所述训练处理的条件至少满足:训练轮次为200-400次,批训练大小为16-64。
技术总结
本发明涉及工业数据处理技术领域,公开了一种预测余热锅炉蒸汽总管流量的方法。该方法包括:(1)对原始数据进行预处理,得到数据集I;(2)对所述数据集I依次进行因子分析和相关性分析,得到数据集II;(3)采用所述数据集II构建CNN‑BiLSTM预测模型,并对所述CNN‑BiLSTM预测模型进行训练处理,得到训练后的CNN‑BiLSTM预测模型;(4)采用所述训练后的CNN‑BiLSTM预测模型对蒸汽总管流量进行预测,得到目标特征预测结果。本发明提供的方法对神经网络预测模型的泛化能力有很大的提高,选出的30组特征变量降低了原始48组特征变量信息重叠带来的影响,能够更精准地预测蒸汽总管流量。
技术研发人员:张林夕,刘琼
受保护的技术使用者:上海电力大学
技术研发日:
技术公布日:2024/5/8
- 还没有人留言评论。精彩留言会获得点赞!