非参数自适应的情绪识别模型、方法、系统和存储介质与流程
本发明涉及情绪识别和计算机大数据处理,尤其是一种非参数自适应的情绪识别模型、方法、系统和存储介质。
背景技术:
1、目前表情识别已经取得了广泛的应用,但在面部表情识别中,由于表情图像存在着模棱两可的情况以及标注者的主观性导致分类标签具有不确定性问题,如图1所示,这种不确定性阻碍了基于数据驱动的深度面部表情识别模型(fer)的性能。在fer模型训练过程中存在着以下问题:1)很难学习到一个具有很强判别性的模型,往往精度不高;2)由于存在着不正确标签的可能性,模型可能会过拟合到不确定性的样本;3)模型对于模糊不清的样本是敏感的,在优化过程中不容易收敛。
技术实现思路
1、为了克服上述现有技术中面部表情识别模型精度低的缺陷,本发明提出了一种非参数自适应的情绪识别模型的构建方法,可构建出高精度的情绪识别模型,且该构建方法可结合现有模型结构进行应用。
2、为实现上述目的,本发明采用以下技术方案,包括:
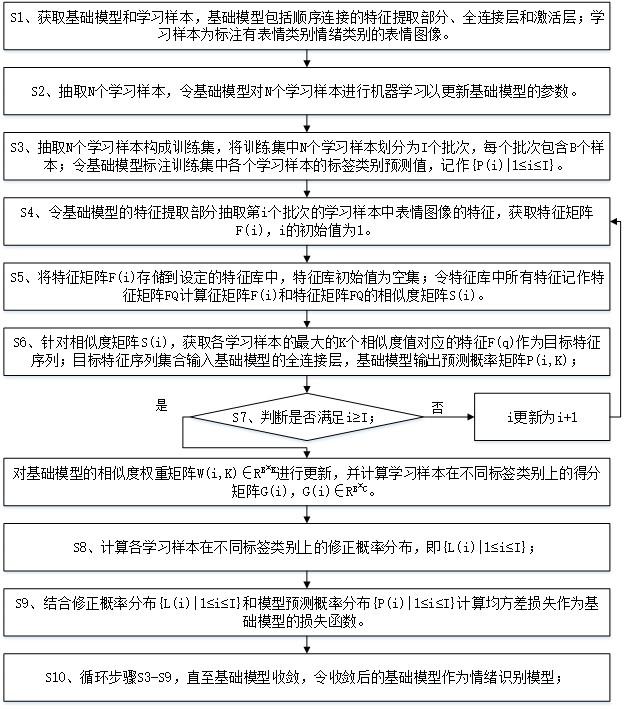
3、本发明提出的一种非参数自适应的情绪识别模型的构建方法,首先构建由顺序连接的特征提取部分、全连接层和激活层构成的基础模型,特征提取部分用于提取表情图像的特征,特征经过全连接层和激活层处理后生成表情图像对应各情绪类别的概率分布;获取标注有情绪类别的表情图像作为学习样本;然后令基础模型对设定数量的学习样本进行机器学习,进行模型参数的预训练;再针对预训练后的基础模型结合以下步骤s3-s10,进行非参数自适应训练,直至获取收敛后的基础模型作为情绪识别模型;
4、s3、抽取n个学习样本构成训练集,将训练集中n个学习样本划分为i个批次,每个批次包含b个样本;令基础模型标注训练集中各个学习样本的标签类别预测值,记作{p(i)|1≤i≤i},p(i)∈rb×c;p(i)为第i个批次的学习样本的模型预测概率分布,c为情绪类别数量;
5、s4、令基础模型的特征提取部分抽取第i个批次的学习样本中表情图像的特征,获取特征矩阵f(i)={f(i,1),f(i,2),…,f(i,b),…,f(i,b)};f(i,b)表示当前基础模型的特征提取部分针对本批次第b个学习样本提取的特征,1≤b≤b;i的初始值为1;
6、s5、将特征矩阵f(i)存储到设定的特征库中,特征库初始值为空集;令特征库中所有特征记作特征矩阵fq={f(q)|1≤q≤q};f(q)表示特征矩阵fq中第q个样本特征,f(q)∈{f(i,b)|1≤i≤i,1≤b≤b},q=i×b;计算特征矩阵f(i)和特征矩阵fq的相似度矩阵s(i),s(i)中第b行第q列元素s[f(i,b),f(q)]表示特征f(i,b)与特征f(q)的相似度值;
7、s6、针对相似度矩阵s(i),获取各学习样本的最大的k个相似度值对应的特征f(q)作为目标特征序列;令相似度矩阵s(i)中第b个学习样本对应的最大的k个相似度值的集合记作sk(i,b),相似度矩阵s(i)中第b个学习样本的目标特征序列记作fk(i,b);令目标特征序列集合{fk(i,b);1≤b≤b}作为基础模型的全连接层的输入,基础模型输出该b个学习样本的目标特征序列对应的预测概率矩阵p(i,k)∈rb×k×c,c为情绪类别数量;
8、s7、判断是否满足i≥i;否,则令i更新为i+1,然后返回步骤s4;是,则对基础模型的相似度权重矩阵w(i,k)∈rb×k进行更新,并计算学习样本在不同标签类别上的得分矩阵g(i),g(i)∈rb×c;
9、w(i,k)=[e{sk(i,b)|1≤i≤i,1≤b≤b}/τ]/[∑ke{sk(i,b)|1≤i≤i,1≤b≤b}/τ]
10、g(i)=∑k[w(i,k)·p(i,k)]
11、其中,τ为在(0,1)上取值的常数;
12、s8、计算各学习样本在不同标签类别上的修正概率分布,即{l(i)|1≤i≤i};
13、l(i)=arg max(eg(i)/∑ceg(i))
14、l(i)∈rb×c
15、s9、结合修正概率分布{l(i)|1≤i≤i}和模型预测概率分布{p(i)|1≤i≤i}计算基础模型的损失函数;
16、s10、判断基础模型是否收敛;否,则清空特征库,并返回步骤s3;是,则令该基础模型作为情绪类别模型。
17、优选地,特征提取部分采用resnet-18、scn、rul、eac或者dan。
18、优选地,激活层采用 softmax函数。
19、优选地,s10中,判断基础模型收敛的条件为:步骤s3-s9的循环次数达到设定的次数;或者是基础模型的损失函数收敛。
20、优选地,s9中,基础模型的损失函数为修正概率分布{l(i)|1≤i≤i}和模型预测概率分布{p(i)|1≤i≤i}的均方差损失。
21、本发明提出的一种情绪识别方法,首先采用所述的非参数自适应的情绪识别模型的构建方法构建情绪识别模型,然后将待识别的表情图像输入情绪识别模型,情绪识别模型输出表情图像在各情绪类别上的概率分布,取最大概率对应的情绪类别作为表情图像的情绪识别结果。
22、本发明还提出了承载上述非参数自适应的情绪识别模型的构建方法和情绪识别方法的情绪识别系统和存储介质,从而方便本发明提供的情绪识别模型的推广应用,实现高精度的情绪识别。
23、本发明提出的一种情绪识别系统,包括存储器和处理器,存储器中存储有计算机程序,处理器连接存储器,处理器用于执行所述计算机程序,以实现所述的非参数自适应的情绪识别模型的构建方法。
24、本发明提出的一种情绪识别系统,包括存储器和处理器,存储器中存储有计算机程序和情绪识别模型,处理器连接存储器,处理器用于执行所述计算机程序,以实现所述的情绪识别方法。
25、本发明提出的一种存储介质,存储有计算机程序,所述计算机程序被执行时用于实现所述的非参数自适应的情绪识别模型的构建方法。
26、本发明的优点在于:
27、(1)本发明提出的一种非参数自适应的情绪识别模型的构建方法,在模型训练过程中,通过修正概率分布l(i)的计算实现了对不确定性样本标签进行自动重新标注。本发明中,在每个轮次中随着学习样本批次i的增加,不断地将特征存储在一个可变的特征库中,在第i个批次学习中,计算每个样本的当前特征与特征库之间的相似度;然后,利用最相似的k个样本特征计算该样本在不同情绪类别上的权重分数;最后,根据上述的权重分数对样本的标签进行自动重新标注,更换标签后计算模型的损失函数。该方法可以提升fer模型(深度面部表情识别模型)的性能,同时对模型没有引入新的参数,本发明本质上是一种可结合现有任一种fer模型来实现的高精度情绪识别方法。
28、(2)本发明提出的非参数自适应的情绪识别模型的构建方法适用于现有任一种模型,且均能够有效地提升了面部表情识别的准确率。
29、(3)本发明提出的情绪识别方法,采用本发明提供的情绪识别模型,能够实现高精度的情绪识别。
- 还没有人留言评论。精彩留言会获得点赞!