神经元计算机操作系统的资源映射方法和装置与流程
本技术涉及神经网络与新型架构计算领域,特别是涉及神经元计算机操作系统的资源映射方法和装置。
背景技术:
1、神经形态计算是一种模拟大脑结构和功能的计算模式,脉冲神经网络(spikingneural network,简称为snn)是神经形态计算领域中最具有代表性的一种计算模型。snn通过模拟大脑神经元的行为和突触连接方式来完成信息的脉冲编码和传递,从而有效解决复杂任务,因低功耗和事件驱动特性而著称。
2、神经形态芯片是为运行snn而专门设计的一种硬件,其采用高密度的片上网络来模拟生物神经元的连接,从而实现大规模并行计算。在大规模的神经形态硬件系统中,多个神经形态芯片互联,形成更大规模的片上网络结构,以支持更加复杂的计算任务。snn与传统计算应用最大的区别在于,snn是通过脉冲输入输出完成计算的。片上网络不同核心间的脉冲传递路径,以及软件与片上网络的脉冲输入输出路径,对snn的运行性能和系统功耗有着显著影响。因此,对snn的资源映射和脉冲输入输出路由规划提出了较高的要求。目前,针对snn的资源映射,通常是在编译阶段将snn划分为神经元簇,并手动或自动地建立神经元簇与硬件的运行核心之间的映射,根据编译阶段完成的映射方案将snn加载到硬件上运行,然而,这种静态映射方法过于简单且缺乏灵活性,难以动态管理核心并根据核心的实时状态在庞大的解空间中高效找到最优解,生成最优的资源分配方法,从而造成资源浪费,从而影响snn的运行性能。
3、针对相关技术中存在核心资源利用率较低和脉冲神经网络运行性能较低的问题,目前还没有提出有效的解决方案。
技术实现思路
1、在本实施例中提供了一种神经元计算机操作系统的资源映射方法和装置,以解决相关技术中脉冲神经网络运行性能较低的问题。
2、第一个方面,在本实施例中提供了一种神经元计算机操作系统的资源映射方法,包括:
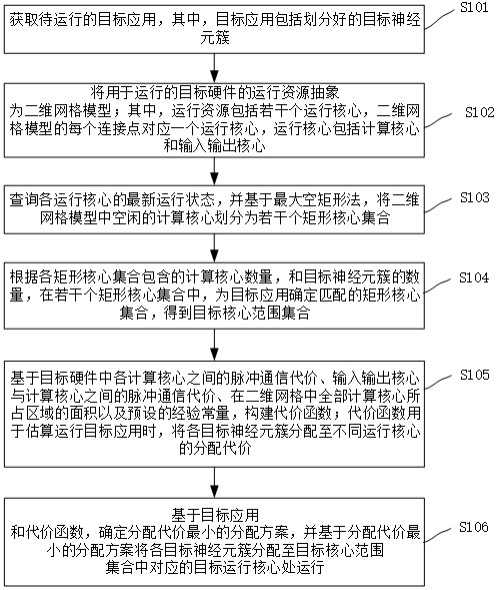
3、获取待运行的目标应用,其中,所述目标应用包括划分好的目标神经元簇;
4、将用于运行的目标硬件的运行资源抽象为二维网格模型;其中,所述运行资源包括若干个运行核心,所述二维网格模型的每个连接点对应一个所述运行核心,所述运行核心包括计算核心和输入输出核心;
5、查询各所述计算核心的最新运行状态,并基于最大空矩形法,将所述二维网格模型中空闲的计算核心划分为若干个矩形核心集合;
6、根据各所述矩形核心集合包含的计算核心数量,和所述目标神经元簇的数量,在若干个所述矩形核心集合中,为目标应用确定匹配的矩形核心集合,得到目标核心范围集合;
7、基于所述目标硬件中各所述计算核心之间的脉冲通信代价、所述输入输出核心与所述计算核心之间的脉冲通信代价、在所述二维网格中全部所述计算核心所占区域的面积以及预设的经验常量,构建代价函数;所述代价函数用于估算运行所述目标应用时,将各所述目标神经元簇映射至不同所述计算核心的映射代价;
8、基于所述目标应用和所述代价函数,确定映射代价最小的映射方案,并基于所述映射代价最小的映射方案将各所述目标神经元簇映射至所述目标核心范围集合中对应的目标运行核心处运行。
9、在其中的一些实施例中,所述目标神经元簇包括计算神经元簇和输入输出神经元簇。
10、在其中的一些实施例中,所述输入输出核心对应所述二维网格模型边缘的连接点。
11、在其中的一些实施例中,所述目标应用包括计算神经元簇集合、输入输出神经元簇集合、计算神经元簇连接集合以及输入输出神经元簇连接集合。
12、在其中的一些实施例中,所述基于所述目标应用和所述代价函数,确定映射代价最小的映射方案,并基于所述映射代价最小的映射方案将各所述目标神经元簇映射至所述目标核心范围集合中对应的目标运行核心处运行,包括:
13、基于所述目标应用、所述目标核心范围集合、所述输入输出核心构成的集合以及预设的最大遗传代数,利用遗传算法生成将所述目标神经元簇映射至所述运行核心的多个候选映射方案;
14、基于所述代价函数,将多个所述候选映射方案中映射代价最小的候选映射方案识别为目标映射方案;
15、根据所述目标映射方案,将各所述目标神经元簇映射至对应的所述目标运行核心;
16、基于所述目标运行核心运行所述目标应用。
17、在其中的一些实施例中,所述基于所述目标应用、所述目标核心范围集合、所述输入输出核心构成的集合以及预设的最大遗传代数,利用遗传算法生成将所述目标神经元簇映射至所述运行核心的多个候选映射方案,包括:
18、当所述目标神经元簇为输入输出神经元簇时,基于预设的脉冲输入输出最短距离优先策略,生成将所述目标神经元簇映射至距离最短的目标输入输出核心的输入输出映射方案;
19、基于所述输入输出映射方案,生成所述候选映射方案。
20、在其中的一些实施例中,所述根据所述目标核心范围集合中各所述计算核心之间的通信限制条件,构建代价函数,包括:
21、基于所述目标硬件中各所述计算核心之间的脉冲通信代价、所述输入输出核心与所述计算核心之间的脉冲通信代价、在所述二维网格中全部所述计算核心所占区域的面积以及预设的经验常量,构建所述代价函数。
22、在其中的一些实施例中,所述根据各所述矩形核心集合包含的计算核心数量,和所述目标神经元簇的数量,在若干个所述矩形核心集合中,为目标应用确定匹配的矩形核心集合,得到目标核心范围集合,包括:
23、将包含的计算核心数量不少于所述计算神经元簇的数量的所述矩形核心集合,确定为候选集合;
24、确定所述候选集合包含的计算核心数量与所述计算神经元簇的数量之间的数量差值,将所述数量差值最小的所述候选集合确定为所述目标核心范围集合。
25、第二个方面,在本实施例中提供了一种神经元计算机操作系统的资源映射装置,包括:获取模块、抽象模块、矩形划分模块、集合选择模块、函数构建模块以及映射模块,其中:
26、所述获取模块,用于获取待运行的目标应用,其中,所述目标应用包括划分好的目标神经元簇;
27、所述抽象模块,用于将用于运行的目标硬件的运行资源抽象为二维网格模型;其中,所述运行资源包括若干个运行核心,所述二维网格模型的每个连接点对应一个所述运行核心,所述运行核心包括计算核心和输入输出核心;
28、所述矩形划分模块,用于查询各所述运行核心的最新运行状态,并基于最大空矩形法,将所述二维网格模型中空闲的计算核心划分为若干个矩形核心集合;
29、所述集合选择模块,用于根据各所述矩形核心集合包含的计算核心数量,和所述目标神经元簇的数量,在若干个所述矩形核心集合中,为目标应用确定匹配的矩形核心集合,得到目标核心范围集合;
30、所述函数构建模块,用于基于所述目标硬件中各所述计算核心之间的脉冲通信代价、所述输入输出核心与所述计算核心之间的脉冲通信代价、在所述二维网格中全部所述计算核心所占区域的面积以及预设的经验常量,构建代价函数;所述代价函数用于估算运行所述目标应用时,将各所述目标神经元簇映射至不同所述计算核心的映射代价;
31、所述映射模块,用于基于所述目标应用和所述代价函数,确定映射代价最小的映射方案,并基于所述映射代价最小的映射方案将各所述目标神经元簇映射至所述目标核心范围集合中对应的目标运行核心处运行。
32、第三个方面,在本实施例中提供了一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述第一个方面所述的神经元计算机操作系统的资源映射方法。
33、与相关技术相比,在本实施例中提供的神经元计算机操作系统的资源映射方法和装置,通过获取待运行的目标应用,其中,所述目标应用包括划分好的目标神经元簇;将用于运行的目标硬件的运行资源抽象为二维网格模型;其中,运行资源包括若干个运行核心,二维网格模型的每个连接点对应一个运行核心,运行核心包括计算核心和输入输出核心;查询各计算核心的最新运行状态,并基于最大空矩形法,将二维网格中空闲的计算核心划分为若干个矩形核心集合;根据各矩形核心集合包含的计算核心数量,和目标神经元簇的数量,在若干个矩形核心集合中,为目标应用确定匹配的矩形核心集合,得到目标核心范围集合;基于所述目标硬件中各所述计算核心之间的脉冲通信代价、所述输入输出核心与所述计算核心之间的脉冲通信代价、在所述二维网格中全部所述计算核心所占区域的面积以及预设的经验常量,构建代价函数;代价函数用于估算运行目标应用时,将各目标神经元簇映射至不同计算核心的映射代价;基于目标应用和代价函数,确定映射代价最小的映射方案,并基于映射代价最小的映射方案将各目标神经元簇映射至目标核心范围集合中对应的目标运行核心处运行。解决了相关技术中脉冲神经网络运行性能较低的问题,提高了脉冲神经网络的运行性能。
34、本技术的一个或多个实施例的细节在以下附图和描述中提出,以使本技术的其他特征、目的和优点更加简明易懂。
- 还没有人留言评论。精彩留言会获得点赞!