一种对于分类型任务时间序列发布的差分隐私保护方法
本发明涉及数据安全与隐私保护,特别是涉及一种对于分类型任务时间序列发布的差分隐私保护方法(nsa-dp)。
背景技术:
1、在大数据时代,医疗保健和金融等不同领域已经使用人工智能技术来分析时间序列。这些时间序列总是包含隐私信息,例如个人健康状况和个人投资状况,这些信息很容易被攻击者获取。因此,研究人员通常采用差分隐私保护的方法对于时间序列的隐私进行保护。
2、对于时间序列差分隐私保护,主要有时间序列位置交换扰动、生成合成的数据和数值扰动三种方法。时间序列位置交换扰动是将数据点在时间序列中的位置按照一定的概率进行交换。然而,交换的数值的大小难以控制,这可能导致数据效用较低。生成合成数据是使用一些隐私保护的深度学习模型,如隐私 gan和隐私扩散模型,将噪声加入模型的梯度中以确保隐私保护。然而,这种技术非常耗时并且难以控制隐私的保护程度过程。
3、对于使用数值扰动的不同模型,有输出侧和隐私侧两个方面。
4、从输出方面来看,这些模型可以根据其发布时间序列统计数据和时间序列数据进行分类。fast实现采样、扰动和过滤来发布时序数据的聚合结果。隐私保护聚合找到显著的数据点并添加扰动。数据分析师可以采用人工智能算法对发布时间序列数据进行数据挖掘。隐私保护方案使用动态干扰阈值来获得低噪声,从而提高数据可用性。地标隐私将数据点区分为重要数据点(地标)和常规数据点,以提供不同的隐私保护。
5、从隐私方面来看,这些模型可以分为特征同等重要和特征不同等重要。特征同等重要意味着整个数据将得到相同的隐私保护。cts-dp使用特定滤波器生成相关噪声以获得序列不可区分性。sw-ats在周期性时间序列上使用滑动窗口来保护隐私。re-dpoctor采用自适应采样和预算分配的方法来实现健康数据的实时扰动,保证一段时间的差分隐私。隐私保护聚合和地标隐私分别保护显著数据点和地标的隐私。
6、然而,上述模型是时间序列数据的通用方法,仅考虑了隐私保护方面的特征。直接使用这些通用模型时,时间序列的可用性和不同特征的隐私性不能得到很好的保证。
7、需要说明的是,在上述背景技术部分公开的信息仅用于对本申请的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、针对传统方法对于时间序列的可用性和不同特征的隐私性不能得到很好保证的问题,本发明提供一种对于分类型任务时间序列发布的差分隐私保护方法。
2、为实现上述目的,本发明采用以下技术方案:
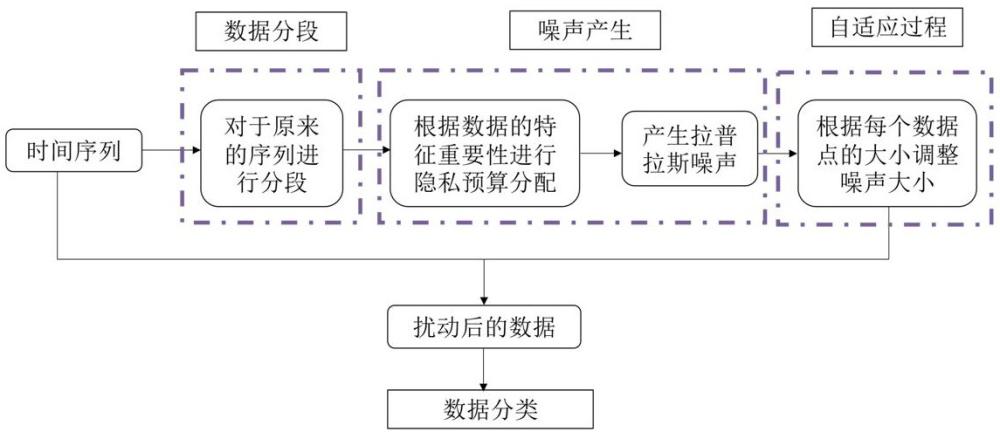
3、一种对于分类型任务时间序列发布的差分隐私保护方法(简称nsa-dp),包括:
4、数据分段:使用时间序列数据的均值作为参考点,将时间序列数据分成若干片段;
5、噪声产生:根据时间序列数据特征的重要性为时间序列数据的每个片段分配隐私预算,并根据隐私预算的分配结果,使用差分隐私的拉普拉斯机制为每个片段生成拉普拉斯噪声;其中,所述时间序列数据特征的重要性包括隐私保护重要性和数据分类任务重要性,所述隐私保护重要性和所述数据分类任务重要性根据时间序列数据的统计量来计算。
6、进一步地,所述数据分段包括:
7、使用均值与时间序列数据的交点作为时间序列数据分段的端点;
8、根据所述端点将时间序列数据分成若干片段;
9、计算每个时间序列数据片段的标准差,如果相邻时间序列数据片段的标准差均小于阈值,则将相邻时间序列数据片段合并为一个时间序列数据片段,其中,是用于控制合并的片段大小的参数,表示所有时间序列数据片段的标准差的最大值。
10、进一步地,还使用时间序列数据中连续为0的第一个点作为时间序列数据分段的端点,去除了时间序列末尾连续为0的时间序列片段。
11、进一步地,所述统计量包括均值、标准差、偏度、峰度和自相关系数。
12、进一步地,所述为时间序列数据的每个片段分配隐私预算包括:
13、计算时间序列数据每个数据类别的统计量;
14、确定各统计量的重要性权重,并根据各统计量的重要性权重来计算反映分类任务重要性的概率;
15、根据时间序列数据的统计量,为每个片段计算隐私重要性;
16、根据反映分类任务重要性的概率和每个片段的隐私重要性,进行隐私预算分配。
17、进一步地,各统计量的重要性权重根据标准差确定。
18、进一步地,使用如下公式来分配隐私预算:
19、
20、其中,是第j个片段的隐私预算,是每个时间序列数据片段的隐私预算的最大值,是第j个片段的隐私重要性,是反映分类任务重要性的概率,是调整隐私级别的参数。
21、进一步地,所述方法还包括:
22、自适应过程:根据数据偏离均值大小自适应地调整噪声,当数据值偏离均值越大时,对应的噪声值也相应增大。
23、进一步地,所述自适应过程包括:
24、将原始时间序列数据和产生的噪声归一化;
25、计算归一化后的噪声和原始时间序列数据各自与时间序列数据的均值之差的哈达玛积;
26、根据计算出的哈达玛积,将归一化的噪声恢复到原始的噪声范围;
27、从恢复的噪声中减去噪声平均值,得到无偏噪声;
28、将无偏噪声添加到原始时间序列数据中,得到扰动后的时间序列数据。
29、进一步地,一种计算机可读存储介质,存储有计算机程序,实现所述的差分隐私保护方法。
30、本发明具有如下有益效果:
31、本发明提出了一种对于分类型任务时间序列发布的差分隐私保护方法,该方法可以对时间序列的隐私进行有效的保护,并保留原始时间序列的可用性,能够有效解决分类型任务时间序列发布过程中的隐私泄露问题,是一种具有很高应用价值的隐私保护方法。本发明的方法首次在发布差分隐私时间序列时考虑分类任务特征,与当前最先进的方法(cts-dp)相比,本发明的方法更好地保证了数据的可用性和隐私保护性。
32、本发明实施例中的其他有益效果将在下文中进一步述及。
技术特征:
1.一种对于分类型任务时间序列发布的差分隐私保护方法,其特征在于,包括:
2.如权利要求1所述的差分隐私保护方法,其特征在于,所述数据分段包括:
3.如权利要求2所述的差分隐私保护方法,其特征在于,还使用时间序列数据中连续为0的第一个点作为时间序列数据分段的端点,去除了时间序列末尾连续为0的时间序列片段。
4.如权利要求1至3任一项所述的差分隐私保护方法,其特征在于,所述统计量包括均值、标准差、偏度、峰度和自相关系数。
5.如权利要求1至3任一项所述的差分隐私保护方法,其特征在于,所述为时间序列数据的每个片段分配隐私预算包括:
6.如权利要求5所述的差分隐私保护方法,其特征在于,各统计量的重要性权重根据标准差确定。
7.如权利要求5所述的差分隐私保护方法,其特征在于,使用如下公式来分配隐私预算:
8.如权利要求1至3任一项所述的差分隐私保护方法,其特征在于,还包括:
9.如权利要求8所述的差分隐私保护方法,其特征在于,所述自适应过程包括:
10.一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序由处理器执行时,实现如权利要求1至9任一项所述的差分隐私保护方法。
技术总结
一种对于分类型任务时间序列发布的差分隐私保护方法,包括:数据分段:使用时间序列数据的均值作为参考点,将时间序列数据分成若干片段;噪声产生:根据时间序列数据特征的重要性为时间序列数据的每个片段分配隐私预算,并根据隐私预算的分配结果,使用差分隐私的拉普拉斯机制为每个片段生成拉普拉斯噪声;其中,所述时间序列数据特征的重要性包括隐私保护重要性和数据分类任务重要性,所述隐私保护重要性和所述数据分类任务重要性根据时间序列数据的统计量来计算。本发明的方法首次在发布差分隐私时间序列时考虑分类任务特征,很好地保证了数据的可用性和隐私保护性。
技术研发人员:陈伟坚,冉爱,修宇璇,任欣悦
受保护的技术使用者:清华大学深圳国际研究生院
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!