部署于RRAM的深度学习模型的重训练及权重写入校验方法
本发明属于基于忆阻器的神经网络架构容错优化领域,更具体地,涉及部署于rram(resistive random access memory,non-volatile memory,忆阻器)的深度学习模型的重训练及权重写入校验方法。
背景技术:
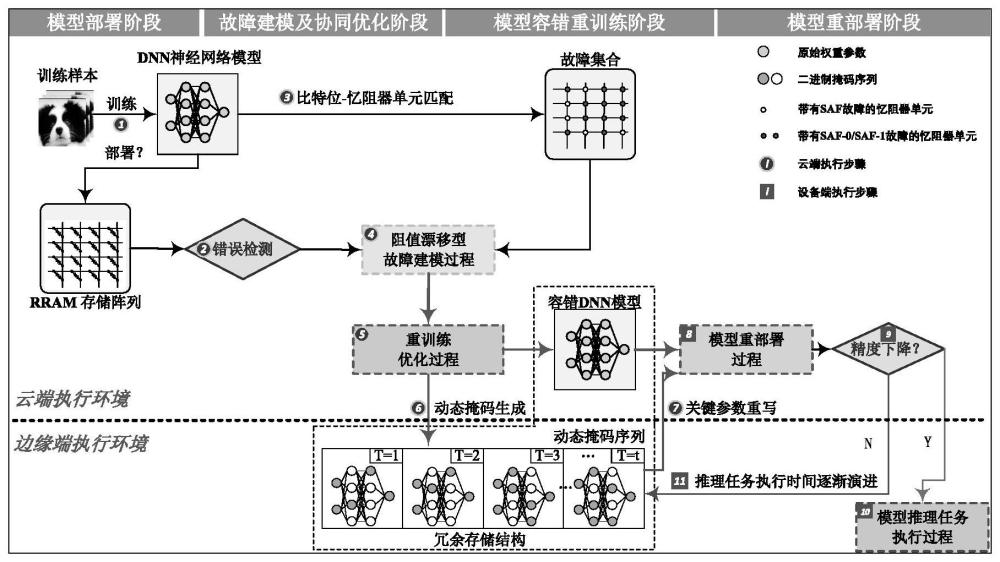
1、为解决一系列表现为阻值偏差的软错误,目前较为普遍的优化方法有数据重写、模型重训练、硬件冗余备份等。然而,对于执行推理任务的边缘端设备而言,设备发生阻值漂移型故障时的容错优化思路有所不同。首先,从边缘场景任务特性的角度出发,推理任务的执行周期一般为设备的生命周期,而且推理任务对时间延迟较为敏感,整体存在执行周期长、时延较敏感、能效要求高等特点,因此容错优化机制需保证时效性及高效性;其次,从故障特性的角度出发,阻值漂移型故障通常随设备工作时间、推理任务执行频度等因素而演化,器件阻值偏差以及对应模型权重参数的数值偏差呈现时序动态性。
2、写入-校验方案作为当前最直接的容错优化手段,写入-校验的方案能够从根本上纠正阻值的漂移行为,该类方案通过高频脉冲电压对忆阻器进行重写操作,然后验证已编程忆阻器单元的导电度,直到目标单元达到精确的目标值。然而,在使用该类方案解决阻值漂移问题时,存在两个主要限制:第一、写入验证等操作需要多个时钟周期,导致编程写入过程的时间延迟过高,例如在为vgg-16模型的全部权重进行写入编程时大约需要46分钟;第二、为在推理任务执行周期内能够持续性的补偿忆阻器单元电导漂移偏差,需要周期性的执行写入-校验过程,可以说上述不足将给边缘端执行推理任务带来大量的时间、能耗开销,使得写入-校验方案难以实际应用。
3、故障感知的模型重训练方法作为最为广泛采用的方法,利用了神经网络自身的容错能力,能够将一系列因故障行为而产生的硬件变化融入到模型的训练过程中。但是如若直接使用重训练方法应对具有动态时序特性的阻值漂移型故障,将面临以下挑战,需要针对阻值的漂移变化情况及时更新模型参数,频繁的重训练将给云端计算中心带来大量计算负载,而与此同时,在设备端接受更新后的模型副本将给云边环境带来大量的通信开销,进一步损害推理任务的时效性。
4、总的来说,当前主流容错优化方法难以有效应对阻值漂移型故障,单纯依靠某一容错机制难以保证神经网络的推理计算准确率。
技术实现思路
1、针对现有技术的缺陷,本发明的目的在于提供部署于rram的深度学习模型的重训练及权重写入校验方法,旨在解决容错机制面对阻值漂移型故障难以保证神经网络的推理计算准确率的问题。
2、为实现上述目的,第一方面,本发明提供了一种部署于rram器件上的深度学习模型的权重误差计算方法,所述权重误差由rram故障单元发生的阻值漂移行为导致,该方法包括:
3、计算rram器件上故障单元运行各时刻的电导值;
4、根据故障单元的电导值和电导偏差,计算存储于rram器件上故障单元的深度学习模型的权重误差。
5、优选地,所述rram器件上故障单元运行各时刻的电导值g(t)计算公式如下:
6、
7、其中,g0表示故障单元在运行起始时刻t0时测量的电导值,v表示电阻值的漂移系数,t表示rram器件的运行时间。
8、优选地,所述深度学习模型的权重误差σw(t)计算公式如下:
9、
10、其中,g(t)表示rram器件上故障单元在t时刻的电导值,σg表示rram器件上故障单元的电导偏差,n表示rram器件每个单元存储的位数。
11、为实现上述目的,第二方面,本发明提供了一种部署于rram器件上的深度学习模型的容错重训练方法,该方法应用于云端,包括:
12、采用如第一方面所述的方法,得到权重误差;
13、迭代进行重训练,直至满足停止条件,得到若干组基于动态时间戳的二进制掩码序列和训练好的容错深度学习模型,其中,每一轮重训练具体包括:
14、故障单元权重更新:根据权重误差计算并更新rram故障单元中的存放的权重;
15、前向传播:读取rram中各单元存放的权重值,代入forward函数,计算得出推理结果;
16、计算损失函数:计算推理结果与真实结果的偏差,作为损失函数;
17、反向传播:根据损失函数计算权重参数的梯度,并更新权重值;
18、数值写回:将更新后的权重值写回到rram上,再进行下一轮迭代。
19、优选地,所述根据权重误差计算并更新rram故障单元中的存放的权重:
20、w*(t)=w+σw(t)
21、其中,w*(t)表示t时刻故障单元更新后的权重,w表示故障单元的原始权重,σw(t)为t时刻的权重误差。
22、优选地,当阻值漂移到时间t时,重训练的前向传播中推理结果如下:
23、f′(x)(t)=f(w′(t),x)
24、
25、
26、其中,w′(t)表示在t时刻读取rram上存储深度学习模型的所有权重,x表示深度学习模型的输入,f()表示深度学习模型的forward函数,f′(x)(t)表示在t时刻的深度学习模型的前向传播推理结果,mb(t)表示t时刻时要恢复权重的动态掩码矩阵,⊙表示矩阵点乘,表示非运算,表示发生故障的单元位置上的权重值,w⊙mb(t)表示没有故障的单元位置上的权重值,mr(t)表示t时刻rram上各单元阻值误差构成的一个矩阵,τ表示预设的阈值。
27、为实现上述目的,第三方面,本发明提供了一种基于动态掩码的参数权重写入-校验方法,该方法应用于云端,包括:
28、采用如第二方面所述的重训练方法,得到二进制掩码序列和训练好的容错深度学习模型,并将二进制掩码序列按照推理任务的执行持续时间,发送给边缘端,以在边缘端存放若干组二进制掩码序列;
29、响应于边缘端的请求,将训练好的深度学习模型中与二进制掩码序列中掩码为1处对应的神经元网络参数,同步到发起请求的边缘端。
30、为实现上述目的,第四方面,本发明提供了一种基于动态掩码的参数权重写入-校验方法,该方法应用于边缘端,包括:
31、在边缘端上深度学习模型的精度下降且低于预设阈值时,向云端发送同步请求,所述同步请求中包含当前时刻对应的二进制掩码序列中掩码为1的位置;
32、接收并写入云端返回的神经元网络参数,以同步更新冗余阵列的深度学习模型网络参数。
33、为实现上述目的,第五方面,本发明提供了一种电子设备,包括:至少一个存储器,用于存储程序;至少一个处理器,用于执行所述存储器存储的程序,当所述存储器存储的程序被执行时,所述处理器用于执行如上述方法。
34、为实现上述目的,第六方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,当所述计算机程序在处理器上运行时,使得所述处理器执行如上述方法。
35、总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
36、(1)本发明提供了一种部署于rram器件上的深度学习模型的权重误差计算方法,根据电导值矩阵漂移,计算深度学习模型的权重误差,得到的权重误差能更好地刻画阻值漂移型故障。
37、(2)本发明提供了一种部署于rram器件上的深度学习模型的容错重训练方法,在每一轮重训练时根据权重误差计算并更新rram故障单元中的存放的权重,由于仅更新故障单元存放的权重,尽可能地对阻值漂移引起的权重偏差进行容错训练,同时减少需重写权重参数的规模,进而降低重训练的负载和耗时。
38、(3)本发明提供了一种基于动态掩码的参数权重写入-校验方法,通过在模型重训练中提取关键参数权重,根据关键参数对应的时序性动态掩码,对交叉阵列中的阻值漂移型的故障单元进行精确写操作,有效减少系统减错阶段的写入-校验次数,降低减错写入的能耗;同时有效减少云边参数通信规模,提升系统性能。所构建的云-边协同容错框架可以显著提升边缘设备计算系统可靠性,同时扩展到推理阶段对精度产生影响的阻值漂移型故障进行容错推理。
- 还没有人留言评论。精彩留言会获得点赞!