基于信创规则库的源码智能分析引擎的制作方法
本发明涉及代码分析,更具体的说是涉及一种基于信创规则库的源码智能分析引擎。
背景技术:
1、信创规则库是指基于人工智能和机器学习技术构建的一套规则或算法库,用于数据挖掘、风险识别、决策分析和智能推荐等领域。该规则库可以快速构建风控系统、反欺诈系统、智能推荐系统等,提高业务效率和用户体验。
2、现有公开号为cn115357481a的中国专利公开了一种web应用往国产信创环境迁移的数据驱动评估方法,评估方法包括以下几个步骤;s1:安装迁移探测器;s2:通过ie浏览器打开需要分析的浏览器页面,浏览器页面中的内容包括js和css-api;s3:通过bho插件注入js,在页面加载完成之后通过bho插件注入js;s4:分析页面html、js和css文件;s5:得出迁移评估工作量,根据本地分析服务分析的ie具有的js和css信息得出。通过获取到的浏览器应用包含的ie特有的js和css信息,可以快速和精准的评估出浏览器应用国产化迁移过程中解决这些js和css兼容性问题所需的工作量,然后通过获取到的特有js和css问题的位置信息可以帮助快速定位页面问题,加快迁移的速度和降低迁移的时间成本。
3、上述现有技术中虽然有通过信创环境的方式对web应用进行兼容性和工作量的处理,并提高整体的兼容性和应用安全性,但仍然处于应用端中使用信创规则,对于从代码端进行验证和代码端进行分析的技术内容未涉及到,对此一种能够基于信创规则库对源码进行验证和分析的分析引擎亟待解决。
技术实现思路
1、针对现有技术存在的不足,本发明的目的在于提供一种基于信创规则库的源码智能分析引擎,具有在信创规则库限定的环境中对源码进行智能分析的效果。
2、为实现上述目的,本发明提供了如下技术方案:
3、一种基于信创规则库的源码智能分析引擎,包括神经网络模型和代码分配器,所述神经网络模型用于训练源代码并分析,所述代码分配器用于获取待分析的源代码并分配,其特征在于:
4、所述神经网络模型构建,其构建方法包括:
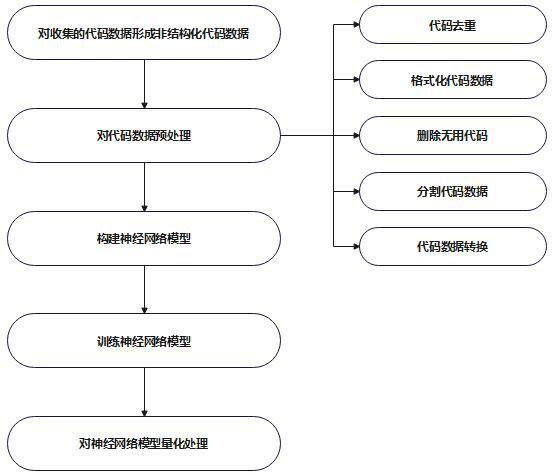
5、s1、收集用于训练模型的代码数据并转换为非结构化形式的代码数据;
6、s2、对数据进行预处理;
7、s3、构建神经网络模型;
8、s4、定义神经网络模型的损失函数;
9、s5、训练神经网络模型;
10、s6、对神经网络模型进行量化处理;
11、所述神经网络模型训练完成后用于部署至gpu对接收到代码分配器分配的源代码转码并预跑,以分析所述源代码。
12、作为本发明的进一步改进,所述步骤s2对数据预处理的步骤包括:
13、s21、代码去重,识别转换后的代码数据中出现重复的代码段,删除多余的代码段,以保留一段代码段;
14、s22、格式化代码数据,对去重后的代码进行格式化;
15、s23、删除无用代码,对格式化后的代码数据中出现的无用字段删除;
16、s24、分割代码数据,将较长的代码文件或函数分割成预设的代码段大小;
17、s25、代码数据转换,将代码数据转换成控制流图形式。
18、作为本发明的进一步改进,所述步骤s4中定义的损失函数选用多标签交叉熵损失函数,所述多标签交叉熵损失函数为:
19、设定有n个样本的代码数据和k个类别,其中每个样本可以属于多个类别,对于第i个样本的代码数据,记真实标签为,其中,为0或1,表示样本的代码数据是否属于第k个类别,同时模型在第i个样本的代码数据上的预测结果为,其中,表示预测样本的代码数据属于第k个类别的概率:
20、
21、其中,log表示自然对数。
22、作为本发明的进一步改进,所述步骤s6的量化处理步骤包括:
23、s61:获取要进行量化的神经网络模型,提取卷积层并对卷积层中神经元的权重梯度进行计算,根据计算后的权重梯度计算卷积层的权重影响力;
24、s62:计算卷积层的激活方差值并获得卷积层的量化位宽;
25、s63:确定每层卷积层的最佳量化位宽;
26、s64:将确定的量化位宽应用于每一卷积层中并使用量化函数对全精度神经网络转换;
27、s65:将量化后的神经网络模型用损失函数进行训练并统计训练误差。
28、作为本发明的进一步改进,所述权重影响力的计算方式为:
29、神经元的权重梯度为dwi并通过反向传播算法计算,公式为:
30、
31、其中,loss为全精度神经网络的误差函数,公式为:
32、
33、其中,为输入对应的真实值,为神经网络对输入的预测值,应用公式 计算每一层的权重影响力。
34、作为本发明的进一步改进,在神经网络模型训练的初期,计算卷积层的激活值方差,结合权重影响力,计算该层量化后引发的精度损失;
35、每层的激活值方差根据前向传播过程中的激活值统计获得,激活函数激活值采用relu函数计算,公式为:
36、
37、计算激活值的均值:
38、
39、方差公式为:
40、
41、精度损失采用以下公式进行计算:
42、
43、其中是第k层的量化位宽。
44、作为本发明的进一步改进,所述步骤s63中采用遗传算法确定每层的最佳量化位宽,设定种群大小并设置交叉率,初始化时随机分配量化位宽,每次迭代中,根据以下公式计算适应度并使得综合性能损失指标p最小化:
45、 。
46、作为本发明的进一步改进,所述步骤s64的量化函数为:
47、
48、其中,是第k层的全精度权重,是量化后的权重,是每个量化级别的步长,由量化位宽决定,的计算公式为:
49、。
50、作为本发明的进一步改进,部署于gpu上的所述神经网络模型对源代码分析时包括:
51、转换源代码为控制流图并输入至神经网络模型中预测分析,经过预测分析输出运行结果和多类别分类结果以评估源代码的质量,所述运行结果包括运行或不运行,所述多类别分类结果包括代码质量分类、功能分类和漏洞类型分类;
52、对代码质量进行分类时设定代码质量的评估指标并配置有评估指标的优先级,评估指标包括:可读性、可维护性、性能、安全性和可靠性。
53、作为本发明的进一步改进,所述安全性的评估包括边界检查,所述边界检查的判断方法包括:
54、a1:检查输入数据范围,对输入数据的数据类型、长度进行检查;
55、a2:检查数组边界,对使用数组的代码运行,检测代码的下标值是否在下表的有效范围内,若下标值超出数组的有效范围,判定为数组越界访问;
56、a3:检查指针引用,判断指针指向的内存空间是否合法,若指针为空或指向非法的内存空间,判断为攻击程序;
57、a4:检查文件操作,判断文件名是否合法,并进行权限检查,若文件名不合法或权限不足,判断为无效程序;
58、a5:检查网络通信,判断通信协议和端口是否符合规范,若通信协议或端口存在漏洞,判断为无效程序。
59、本发明的有益效果:
60、通过训练神经网络模型并对模型进行混合精度量化处理,减小了模型的存储需求和计算复杂度,整体模型能够在计算资源有限的环境下更加高效的运行,量化后的模型由于降低了计算负荷,使得能够在消耗少量能量的同时执行判断人物。在将模型部署到gpu中后对源代码进行预跑,并通过预跑后的多类别分类结果进行评估判断,尤其是进行边界检查来判断代码的安全性,从而达到源代码进行智能分析的效果。
- 还没有人留言评论。精彩留言会获得点赞!