电子设备及其数据处理方法与流程
本技术涉及神经网络的。尤其涉及一种电子设备及其数据处理方法。
背景技术:
1、随着神经网络技术的发展,智能模型开始越来越多地运用在视频或者图像生成领域。例如:神经辐射场(nerf,neural radiance fields)模型可以根据接收的一组或者一系列的已知拍摄视角的拍摄对象的输入图像,渲染出该拍摄对象的不同于已知拍摄视角的新拍摄视角的生成图像的图像集合,甚至还可以根据图像集合得到整个拍摄对象的三维结构和外观。通过多样化数据学习nerf模型重建过程中数据退化方式以及恢复方式,可以提升新场景下nerf模型所渲染的新视角的画质。该类方法提出的模型不需要有在新场景下重新训练,具有场景泛化性,然而目前这类方法只能应用在静态场景下。
2、但是,针对运动状态(也可以称为动态场景)下的拍摄对象来说,随着时间变化,即使在同一个拍摄视角下,拍摄对象的姿态也会发生变化,导致上述具有场景泛化性的插件式nerf新视角画质增强模型失效。因此,需要一种能够在静态、动态场景下均适用的,不需要针对每个场景下重新训练的,可泛化的nerf模型新视角画质增强方法。
技术实现思路
1、本技术提供了一种电子设备及其数据处理方法。
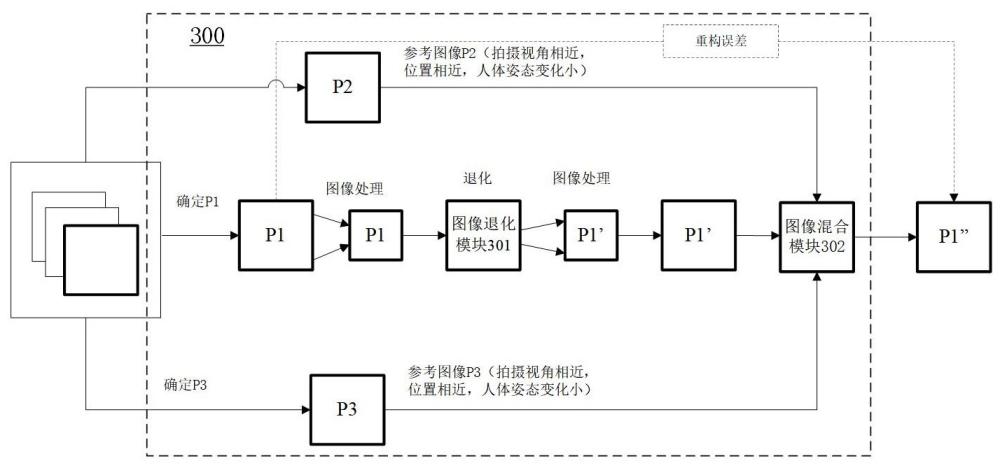
2、第一方面,本技术实施例提供了一种数据处理方法,方法包括:确定训练数据集合,其中,训练数据集合包括拍摄对象的第一训练图像以及第一训练图像对应的第一状态信息,第一状态信息用于表示拍摄对象的对象状态,对象状态包括拍摄对象至少处于运动状态;对应于对象状态为运动状态,确定第一状态信息包括第一训练图像对应的第一拍摄视角,拍摄对象的第一位置信息和第一姿态变化信息,以及确定出第一训练图像对应的第二训练图像,其中,第二训练图像对应的第二状态信息与第一状态信息满足预设条件;将第一训练图像、第一状态信息以及第二训练图像、第二状态信息输入第一模型进行训练,得到第二模型,其中,第二模型用于生成拍摄对象的生成图像,生成图像用于呈现拍摄对象的运动状态。
3、在本技术中,这里的训练数据集合可以是训练图像的图像集合。这里的第一训练图像可以是目标图像而第二训练图像可以是参考图像。第一状态信息可以是第一训练图像的拍摄视角,拍摄对象的第一位置信息和第一姿态变化信息,相对而言,第二状态信息可以是第二训练图像的拍摄视角,拍摄对象的第二位置信息和第二姿态变化信息。对应于拍摄对象处于运动状态,第一状态信息和第二状态信息相同/相近,这里的第一训练图像和第二训练图像可以是预先确定的拍摄视角相近、位置相近、姿态变化小的图像。
4、可以看出,这里的第一状态信息以及第二状态可以是从训练图像获取/解析出的信息。通过结合拍摄对象的位置信息以及姿态变化信息训练后的第二模型,在基于对应运动状态的拍摄对象的输入图像而生成拍摄对象的生成图像时,能够确保生成图像具有能够反映拍摄对象的更加逼真的效果。
5、在上述第一方面的一种可能的实现中,第一拍摄视角包括第一训练图像对应的拍摄设备在空间中的3d坐标以及拍摄设备的水平方向旋转角度以及垂直方向旋转角度。
6、在本技术中,这里的第一拍摄视角可以表示为(x,d),这里的x,也就是,(x,y,z),表示拍摄设备的3d点的坐标。这里的d,也就是,(θ,φ)表示拍摄设备的观测方向,θ和φ可以分别表示水平以及垂直旋转角度。
7、在上述第一方面的一种可能的实现中,第一位置信息和第一姿态变化信息用于表示对应于时间变化拍摄对象的位置变化以及姿态变化。
8、在上述第一方面的一种可能的实现中,对应于第二训练图像对应的第二状态信息与第一状态信息满足预设条件,第一拍摄视角与第二拍摄视角相同、且第一位置信息与第二位置信息之间的第一差值以及第一姿态变化信息与第二姿态变化信息之间的第二差值满足预设差值范围。
9、在本技术中,这里的第二状态信息与第一状态信息满足预设条件可以是选择至少两个训练图像的拍摄视角相同或者相近,相近可以表示两个训练图像的拍摄视角之间的差值满足差值范围,如:拍摄视角之间的差值小于1°;以及至少两个训练图像中的拍摄对象之间的旋转/平移等运动变化程度满足变化范围时,例如:运动变化程度小于1°,也就是,训练图像之间的拍摄对象的位置相近,姿态变化小。
10、在上述第一方面的一种可能的实现中,将第一训练图像、第一状态信息以及第二训练图像、第二状态信息输入第一模型进行训练,得到第二模型,包括:
11、将第一训练图像经过第一模型对应的第一图像训练模块,得到的第一处理图像,其中,第一处理图像包括表示拍摄对象的第一处理数据,第一处理数据包括拍摄对象对应的噪声、模糊和失真中的至少一种;将第一处理图像、第一状态信息以及第二训练图像、第二状态信息经过第一模型对应的第二图像训练模块,对第一处理图像和第二训练图像进行融合处理,得到第二处理图像,其中,第二处理图像包括第一处理数据以及第二处理数据,第二处理数据包括拍摄对象对应的纹理和光影中的至少一种。
12、在本技术中,这里的第一图像训练模块可以是图像退化模块,第二图像训练模块可以是图像混合模块。还可以对第一训练图像进一步执行图像处理,如:分割、改变分辨率等等。将第一训练图像经过第一图像训练模块的图像退化处理得到第一处理图像,也就是,退化图像,这里的第一处理图像可以包含表示拍摄对象的图像退化数据,例如:噪声、模糊和失真等等,经过图像退化处理的第一处理图像可以包括拍摄对象的真实性。这里的第二训练图像,也就是,参考图像,可以包含表示拍摄对象的高清图像数据,例如:表示纹理、光影等等的数据。将第一处理图像、第二训练图像以及第一状态信息、第二状态信息输入第二图像训练进行训练,第二图像训练可以融合第一处理图像和第二训练图像得到包括了第一处理数据以及第二处理数据的生成图像。
13、可以看出,经过训练后的第二模型具有融合来自多个图像数据能够渲染出包括了更佳的图像质量以及拍摄对象的真实的运动状态的生成图像的能力。
14、在上述第一方面的一种可能的实现中,对应于对象状态为拍摄对象处于静止状态,训练数据集合包括拍摄对象的第三训练图像以及第三训练图像对应的第三状态信息,其中,第三状态信息包括第三训练图像的第三拍摄视角。
15、在本技术中,对应静止状态的拍摄对象的输入图像,对第一模型进行训练的过程可以只关注第三训练图像以及第三训练图像对应的第三拍摄视角。
16、在上述第一方面的一种可能的实现中,还包括:
17、将第三训练图像以及第三训练图像对应的第三状态信息输入第一模型进行训练,得到第二模型,其中,第二模型生成的拍摄对象的生成图像呈现拍摄对象的静止状态。
18、可以看出,训练后的第二模型能够同时具有生成运动以及静止的拍摄对象的生成图像的能力。通过本技术的数据处理方法得到的第二模型既可以支持静态场景,也可以支持动态场景,也就是,训练后的第二模型可以具有能够在静态、动态场景下均适用的,不需要针对每个场景下重新训练的,可泛化的nerf模型新视角的画质增强能力。
19、第二方面,本技术实施例提供了一种数据处理方法,方法包括:
20、确定输入数据集合,其中,输入数据集合包括拍摄对象的第一输入图像;基于第一输入图像确定出第一状态信息,其中,第一状态信息用于表示拍摄对象的对象状态,对象状态包括拍摄对象至少处于运动状态;对应于对象状态为运动状态,确定第一状态信息包括第一输入图像对应的第一拍摄视角,拍摄对象的第一位置信息和第一姿态变化信息,以及确定出第一输入图像对应的第二输入图像,其中,第二输入图像对应的第二状态信息与第一状态信息满足预设条件;将第一输入图像、第一状态信息以及第二输入图像、第二状态信息输入第一渲染模型,得到拍摄对象的渲染图像,其中,渲染图像呈现拍摄对象的运动状态。
21、这里的输入数据集合可以是使用训练后的第一渲染模型对拍摄对象进行渲染的输入图像的图像集合。通过从图像集合中选择的参考图像,也就是,第二输入图像,将参考图像结合输入图像进行渲染,提高第一渲染模型的渲染速度,以及通过选择与输入图像的参数相近/相同的参考图像,使得渲染出的生成图像具有更好的渲染质量。
22、在上述第二方面的一种可能的实现中,第一拍摄视角包括第一输入图像对应的拍摄设备在空间中的3d坐标以及拍摄设备的水平方向旋转角度以及垂直方向旋转角度。
23、在上述第二方面的一种可能的实现中,第一位置信息和第一姿态变化信息用于表示对应于时间变化拍摄对象的位置变化以及姿态变化。
24、在上述第二方面的一种可能的实现中,对应于第二输入图像对应的第二状态信息与第一状态信息满足预设条件,第一拍摄视角与第二拍摄视角相同、且第一位置信息与第二位置信息之间的第一差值以及第一姿态变化信息与第二姿态变化信息之间的第二差值满足预设差值范围。
25、在本技术中,这里的第二状态信息与第一状态信息满足预设条件可以是至少两个输入图像的拍摄视角相同或者相近,相近可以表示两个输入图像的拍摄视角之间的差值满足差值范围,如:拍摄视角之间的差值小于1°;以及至少两个训输入图像中的拍摄对象之间的旋转/平移等运动变化程度满足变化范围时,例如:运动变化程度小于1°,也就是,训练图像之间的拍摄对象的位置相近,姿态变化小。
26、在上述第二方面的一种可能的实现中,将第一输入图像、第一状态信息以及第二输入图像、第二状态信息输入第一渲染模型,得到拍摄对象的渲染图像,包括:
27、将第一输入图像、第一状态信息以及第二输入图像、第二状态信息经过第一渲染模型对应的第一图像渲染模块,对第一输入图像和第二输入图像进行融合处理,得到渲染图像。
28、在本技术中,这里的第一图像渲染模块可以是训练后的第一渲染模型对应的图像混合模块。将第一输入图像、第二输入图像以及第一状态信息、第二状态信息输入第一渲染模型后,第二图像训练可以融合第一输入图像和第二输入图像得到渲染图像。
29、在上述第二方面的一种可能的实现中,对应于对象状态为拍摄对象处于静止状态,输入数据集合包括拍摄对象的第三输入图像以及第三输入图像的第三状态信息,其中,第三状态信息包括第三拍摄视角。
30、在本技术中,对应静止状态的拍摄对象的输入图像,对第一渲染模型进行渲染的过程可以只关注第三输入图像以及第三输入图像对应的第三拍摄视角。
31、在上述第二方面的一种可能的实现中,还包括:
32、将第三输入图像以及第三输入图像对应的第三状态信息输入第一渲染模型进,得到渲染图像。
33、可以看出,第一渲染模型能够同时具有生成运动以及静止的拍摄对象的生成图像的能力。通过本技术的数据处理方法,第一渲染模型既可以支持静态场景,也可以支持动态场景,也就是,第一渲染模型可以具有能够在静态、动态场景下均适用的,不需要针对每个场景下重新训练的,可泛化的nerf模型新视角画质增强能力。
34、第三方面,本技术提供一种电子设备,包括:
35、存储器,用于存储由电子设备的一个或多个处理器执行的指令,以及
36、处理器,是电子设备的处理器之一,用于执行第一方面或者第二方面的数据处理方法。
37、第四方面,本技术提供一种计算机程序产品,包括:非易失性计算机可读存储介质,非易失性计算机可读存储介质包含用于执行执行第一方面或者第二方面的数据处理方法的计算机程序代码。
- 还没有人留言评论。精彩留言会获得点赞!