一种水利工程施工用BIM模型数据管理方法与流程
本发明涉及数据处理,具体涉及一种水利工程施工用bim模型数据管理方法。
背景技术:
1、在基于bim模型对水利工程的物料数据进行管理之前,需要对物料数据进行异常检测;现有方法通常利用cblof(clustering based local outlier factor)基于局部离群因子的聚类离群因子算法对物料数据进行异常检测,而在cblof基于局部离群因子的聚类离群因子算法对物料数据进行异常检测时,通常先利用isodata(iterativeselforganizing data analysis techniques algorithm)迭代自组织聚类算法对物料数据进行聚类,根据聚类结果获取异常数据;但在实际的水利工程中,不同种类的物料在不同施工阶段中的需求不同,使不同种类的物料之间存在各自的数据变化特征,而传统的isodata迭代自组织聚类算法仅通过构建数据点计算其均值作为聚类中心,并没结合不同种类物料的需求情况,降低了传统聚类结果的准确性,降低了异常检测结果的准确性,降低了数据管理的效率。
技术实现思路
1、本发明提供一种水利工程施工用bim模型数据管理方法,以解决现有的问题:在实际的水利工程中,不同种类的物料在不同施工阶段中的需求不同,使不同种类的物料之间存在各自的数据变化特征,而传统的isodata迭代自组织聚类算法仅通过构建数据点计算其均值作为聚类中心,并没结合不同种类物料的需求情况。
2、本发明的一种水利工程施工用bim模型数据管理方法采用如下技术方案:
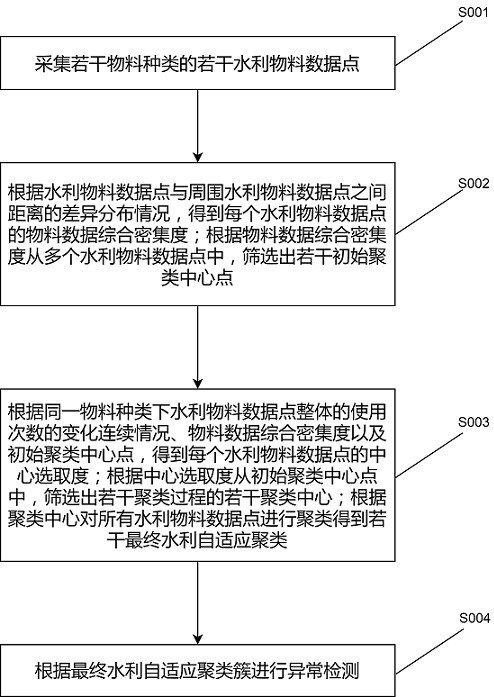
3、包括以下步骤:
4、采集若干物料种类的若干水利物料数据点,所述水利物料数据点对应一个使用次数;
5、根据水利物料数据点与周围水利物料数据点之间距离的差异分布情况,得到每个水利物料数据点的物料数据综合密集度;根据物料数据综合密集度从多个水利物料数据点中,筛选出若干初始聚类中心点;
6、根据同一物料种类下水利物料数据点整体的使用次数的变化连续情况、物料数据综合密集度以及初始聚类中心点,得到每个水利物料数据点的中心选取度;根据中心选取度从初始聚类中心点中,筛选出若干聚类过程的若干聚类中心;根据聚类中心对所有水利物料数据点进行聚类得到若干最终水利自适应聚类簇;
7、根据最终水利自适应聚类簇进行异常检测。
8、优选的,所述根据水利物料数据点与周围水利物料数据点之间距离的差异分布情况,得到每个水利物料数据点的物料数据综合密集度,包括的具体方法为:
9、将任意一个水利物料数据点记为目标水利物料数据点,将除目标水利物料数据点以外的每个水利物料数据点记为参考水利物料数据点;
10、将每个参考水利物料数据点与目标水利物料数据点的欧式距离的反比例值记为第一距离;将所有参考水利物料数据点与目标水利物料数据点的第一距离的累加和记为目标水利物料数据点的物料数据综合密集度。
11、优选的,所述根据物料数据综合密集度从多个水利物料数据点中,筛选出若干初始聚类中心点,包括的具体方法为:
12、获取所有水利物料数据点中的若干极大值点,将每个极大值点记为待筛选聚类中心数据点;将任意一个待筛选聚类中心数据点记为目标待筛选聚类中心点,将与目标待筛选聚类中心点的欧式距离最小的待筛选聚类中心数据点,记为目标待筛选聚类中心点的对照待筛选聚类中心点;获取目标待筛选聚类中心点的所有对照待筛选聚类中心点;根据目标待筛选聚类中心点的每个对照待筛选聚类中心点与目标待筛选聚类中心点的距离关系,得到参考判定距离阈值;
13、对于任意两个待筛选聚类中心数据点,若这两个待筛选聚类中心数据点之间的欧式距离小于,将这两个待筛选聚类中心数据点中物料数据综合密集度最小的待筛选聚类中心数据点记为中心干扰数据点,以此类推,获取所有中心干扰数据点;将除中心干扰数据点以外的每个待筛选聚类中心数据点记为初始聚类中心点。
14、优选的,所述根据目标待筛选聚类中心点的每个对照待筛选聚类中心点与目标待筛选聚类中心点的距离关系,得到参考判定距离阈值,包括的具体方法为:
15、将对照待筛选聚类中心点与目标待筛选聚类中心的欧式距离记为目标待筛选聚类中心的参考判定距离,获取所有待筛选聚类中心数据点的参考判定距离;将所有待筛选聚类中心数据点的参考判定距离的均值记为参考判定距离阈值。
16、优选的,所述根据同一物料种类下水利物料数据点整体的使用次数的变化连续情况、物料数据综合密集度以及初始聚类中心点,得到每个水利物料数据点的中心选取度,包括的具体方法为:
17、将每个初始聚类中心点作为isodata迭代自组织聚类算法中第一次聚类过程中的聚类中心,根据聚类中心,利用isodata迭代自组织聚类算法对所有水利物料数据点进行聚类,得到第一次聚类过程中的若干聚类簇;根据第一次聚类过程中的若干聚类簇,得到第二次聚类过程中的若干聚类中心的具体获取过程为:
18、对于第一次聚类过程中任意一个聚类簇,将聚类簇内的聚类中心与聚类簇内所有水利物料数据点之间欧式距离的方差记为聚类簇的分裂程度,获取所有聚类簇的分裂程度;将所有聚类簇按照分裂程度进行降序排列,将排列后的序列记为聚类簇序列;将聚类簇序列中相邻的任意两个聚类簇之间分裂程度的差值的绝对值记为参考分裂值,获取所有参考分裂值;将数值最大的参考分裂值对应的两个聚类簇中的第二个聚类簇记为待分裂终止聚类簇;
19、将任意一个待分裂聚类簇中任意一个水利物料数据点记为第一目标水利物料数据点;在待分裂聚类簇中,将与第一目标水利物料数据点所属同一个物料种类的所有水利物料数据点构成的序列,记为第一目标水利物料数据点的同物料数据点序列;
20、根据第一目标水利物料数据点的同物料数据点序列中相邻水利物料数据点对应使用次数之间的差异变化,得到第一目标水利物料数据点的水利工程变化连贯性;
21、根据第一目标水利物料数据点的同物料数据点序列中不同水利物料数据点与第一目标水利物料数据点之间的欧式距离、第一目标水利物料数据点的水利工程变化连贯性以及物料数据综合密集度,得到第一目标水利物料数据点的中心选取度。
22、优选的,所述根据第一目标水利物料数据点的同物料数据点序列中相邻水利物料数据点对应使用次数之间的差异变化,得到第一目标水利物料数据点的水利工程变化连贯性,包括的具体方法为:
23、在第一目标水利物料数据点的同物料数据点序列中,将相邻的任意两个水利物料数据点之间对应使用次数的差值的绝对值,记为第一绝对值;将所有第一绝对值的均值记为第一均值;将第一均值的反比例归一化值记为第一目标水利物料数据点的水利工程变化连贯性。
24、优选的,所述根据第一目标水利物料数据点的同物料数据点序列中不同水利物料数据点与第一目标水利物料数据点之间的欧式距离、第一目标水利物料数据点的水利工程变化连贯性以及物料数据综合密集度,得到第一目标水利物料数据点的中心选取度,包括的具体方法为:
25、在第一目标水利物料数据点的同物料数据点序列中,将所有水利物料数据点与第一目标水利物料数据点的欧式距离的累加和记为第一累加和;将第一累加和的反比例归一化值记为第一反比例值;将第一目标水利物料数据点的水利工程变化连贯性、第一目标水利物料数据点的物料数据综合密集度以及第一反比例值,这三者的乘积记为第一目标水利物料数据点的中心选取度。
26、优选的,所述根据中心选取度从初始聚类中心点中,筛选出若干聚类过程的若干聚类中心,包括的具体方法为:
27、将所有水利物料数据点按照中心选取度进行降序排列,将排列后的序列记为中心水利物料数据点序列;对于中心水利物料数据点序列中相邻的任意两个水利物料数据点,在这两个水利物料数据点中,将每个水利物料数据点与待分裂聚类簇内的聚类中心的欧式距离记为每个水利物料数据点的中心参考距离,将这两个水利物料数据点的参考距离的和记为这两个水利物料数据点的中心对照距离,获取任意两个水利物料数据点的中心对照距离;
28、将数值最大的中心对照距离对应的两个水利物料数据点均记为待分配聚类中心,获取所有待分配聚类中心,将每个待分配聚类中心作为第二次聚类过程中的聚类中心。
29、优选的,所述根据聚类中心对所有水利物料数据点进行聚类得到若干最终水利自适应聚类簇,包括的具体方法为:
30、参考根据第一次聚类过程中的若干聚类簇,得到第二次聚类过程中的若干聚类中心的具体获取过程;不断将最新聚类过程的聚类中心输入isodata迭代自组织聚类算法进行迭代聚类,直至最新聚类过程获取的若干聚类簇与其上一次聚类过程获取的若干聚类簇并没有变化时停止聚类,获取最新聚类过程的所有聚类簇,并将每个聚类簇记为最终水利自适应聚类簇。
31、优选的,所述根据最终水利自适应聚类簇进行异常检测,包括的具体方法为:
32、根据所有最终水利自适应聚类簇获取若干异常数据点,将所有异常数据点对应实际用料数据以及剩余用料数据均记为异常数据,使用bim模型对异常数据进行核对,将核对后不匹配的异常数据删除,将删除后剩余的实际用料数据以及剩余用料数据重新存储在新的数据库中。
33、本发明的技术方案的有益效果是:通过结合不同物料种类的水利物料数据点的分布情况以及数据连续情况,自适应调整的isodata迭代自组织聚类算法中每次迭代聚类过程内的聚类中心,提高了聚类过程的效率,提高了聚类结果的准确性;根据水利物料数据点与周围水利物料数据点之间距离的差异分布情况,得到水利物料数据点的物料数据综合密集度,用于反映水利物料数据点作为初始聚类中心的可能性,降低了传统随机选取初始聚类中心对聚类结果效率的延迟情况;然后根据同一物料种类下水利物料数据点整体的使用次数的变化连续情况、物料数据综合密集度以及初始聚类中心点,得到水利物料数据点的中心选取度,用于反映水利物料数据点的作为后续聚类过程的聚类中心的概率,提高了每次迭代聚类过程中聚类结果的准确性;本发明通过结合不同种类物料的需求情况,自适应调整聚类中心,获取最终水利自适应聚类簇并进行异常检测,提高了异常检测结果的准确性,提高了数据管理的效率。
- 还没有人留言评论。精彩留言会获得点赞!