基于大数据与人工智能的不动产金融风险防控方法及系统与流程
本发明涉及计算机,尤其涉及一种基于大数据与人工智能的不动产金融风险防控方法及系统。
背景技术:
1、在当前的经济环境下,不动产市场已成为吸引各类投资者的重要领域,它不仅关系到个人和企业的资产配置,还直接影响到整个金融体系的稳定。随着不动产交易活动的增加,涉及的金融产品和服务也变得更加多样化和复杂。相应地,不动产金融风险管理成为了市场参与者和监管机构关注的焦点。
2、传统的不动产金融风险管理主要依赖于历史数据的统计分析和专业人士的经验判断。然而,由于以下几个方面的局限性,这种方法在现实应用中面临着挑战:
3、1.复杂性:不动产市场受到多种因素的影响,包括经济周期、政策法规、市场供需、利率变化等,这些因素相互作用,增加了风险管理的复杂性。
4、2.数据量大:随着信息技术的发展,不动产相关数据呈爆炸性增长,包括交易记录、市场行情、信贷数据等,传统分析工具难以应对如此庞大的数据量。
5、3.动态变化:不动产市场是一个高度动态变化的市场,需要实时或近实时的数据监控和分析来捕捉市场的最新动向。
6、4.预测困难:由于不动产市场的非线性特性和预测模型的局限性,传统方法难以准确预测市场趋势和风险事件。
7、鉴于以上问题,亟需提出一种基于大数据与人工智能的不动产金融风险防控方法及系统,旨在利用数据分析和人工智能算法对大规模的数据进行高效处理和分析,实现实时监控、动态预测和智能预警,以提高风险管理的准确性和效率。
技术实现思路
1、有鉴于此,本发明的目的是提供一种基于大数据与人工智能的不动产金融风险防控方法及系统,通过深度学习模型和大数据分析技术,实现对不动产市场的全面监控,及时预测和识别潜在风险,从而提供更加精准有效的风险防控策略。
2、为实现上述目的,本发明提供如下技术方案:
3、第一方面,本发明提供了一种基于大数据与人工智能的不动产金融风险防控方法,包括以下步骤:
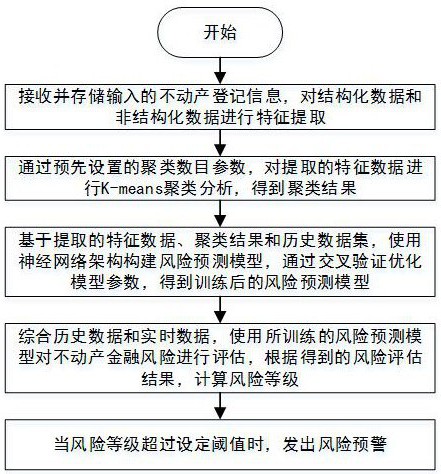
4、接收并存储输入的不动产登记信息,对结构化数据和非结构化数据进行特征提取;
5、通过预先设置的聚类数目参数,对提取的特征数据进行k-means聚类分析,得到聚类结果;
6、基于提取的特征数据、聚类结果和历史数据集,使用神经网络架构构建风险预测模型,通过交叉验证优化模型参数,得到训练后的风险预测模型;
7、综合历史数据和实时数据,使用所训练的风险预测模型对不动产金融风险进行评估,根据得到的风险评估结果,计算风险等级;
8、当风险等级超过设定阈值时,发出风险预警。
9、作为本发明的进一步方案,所述基于大数据与人工智能的不动产金融风险防控方法还包括:使用长短期记忆网络(lstm)对处理时间序列数据,预测不动产市场趋势。
10、作为本发明的进一步方案,接收并存储输入的不动产登记信息,对结构化数据进行特征提取,包括以下步骤:
11、从不动产登记信息中筛选与风险评估相关的数值型结构化特征,并根据风险等级对不动产的数值型结构化特征进行分组;
12、对每个分组的数值型结构化特征使用单因素anova检验不同风险等级组之间的平均值,进行单因素方差分析并计算组间平均值的f值和p值;
13、设定显著性阈值,选择p值小于设定显著性阈值水平的结构化特征作为特征提取。
14、作为本发明的进一步方案,计算组间平均值的f值和p值时,包括:
15、将不动产登记信息中的数值型结构化特征按风险等级分组,并计算每组的平均值和总平均值;其中,anova计算包括组间方差和组内方差;
16、组间方差(ssb, sum of squares between groups)的计算公式为:;
17、其中,k表示组数,ni是第i组的样本数量,是第i组的样本均值,是所有样本的总均值;
18、组内方差(ssw, sum of squares within groups)的计算公式为:;
19、其中,n表示行数,m表示列数,表示矩阵x中第i组中第j个观测值。
20、计算方差比率(f值)时,计算出组间平均平方(msb, mean square betweengroups):;
21、其中,k表示组数;
22、计算组内平均平方(msw, mean square within groups):;
23、其中,n是所有样本的总数量。
24、根据组间平均平方msb和组内平均平方msw,计算方差比率f统计量:;
25、计算组间平均值的p值时,使用f统计量和对应的自由度查f分布表或使用统计软件获取p值,其中,分子自由度为k-1,分母自由度为n-k。
26、作为本发明的进一步方案,接收并存储输入的不动产登记信息,对非结构化数据进行特征提取,包括以下步骤:
27、读取输入的不动产登记信息,将不动产登记信息的文本内容分割成单词,并进行清洗和规范化;
28、统计单词在文本内容中的词频以及逆文档频率,根据词频和逆文档频率计算出文档集中每个文档的tf-idf值;
29、使用文档集中每个文档的tf-idf值,构建特征矩阵,其中,每一列代表一个词汇,每一行代表一个文档,矩阵中的值为相应文档的词汇的tf-idf值。
30、作为本发明的进一步方案,通过预先设置的聚类数目参数,对提取的特征数据进行k-means聚类分析,得到聚类结果,包括以下步骤:
31、1)选择聚类数目k:
32、根据预先设置的聚类数目参数选择待划分的聚类数目k;
33、2)初始化质心:
34、随机选择k个特征数据作为初始质心,计算每个特征数据与每个初始质心的距离,并将每个特征数据分配到最近的初始质心所代表的类别;
35、3)更新质心:
36、重新计算所有分配给每个聚类的特征数据的中心,得到新质心;重复上述步骤直至达到预设的迭代次数,最终得到的质心位置和特征数据的分配结果为聚类结果。
37、作为本发明的进一步方案,使用所训练的风险预测模型对不动产金融风险进行评估,包括以下步骤:
38、将接收的实时数据集与历史数据集合并为特征集,并根据时间戳进行同步;
39、对特征集进行数据标准化预处理后输入到风险预测模型中进行评分,记录模型输出的风险评分,得到风险评估结果。
40、作为本发明的进一步方案,计算风险等级,包括以下步骤:
41、设定划分风险等级的阈值,将风险等级划分为若干级别;
42、计算风险预测模型输出的风险评分的分位数;
43、将计算得到的分位数映射到风险等级中,得到确定的风险等级。
44、第二方面,本发明还提供了一种基于大数据与人工智能的不动产金融风险防控系统,包括以下组件:
45、数据采集模块:用于接收并存储输入的不动产登记信息;
46、特征提取模块:用于对不动产登记信息中的结构化数据和非结构化数据进行特征提取;
47、聚类分析模块:用于通过预先设置的聚类数目参数,对提取的特征数据进行k-means聚类分析,得到聚类结果;
48、模型构建模块:用于基于提取的特征数据、聚类结果和历史数据集,使用神经网络架构构建风险预测模型,通过交叉验证优化模型参数,得到训练后的风险预测模型;
49、风险评估模块:用于综合历史数据和实时数据,使用训练好的风险预测模型对不动产金融风险进行评估,并根据风险评估结果计算风险等级;
50、预警模块:用于监控风险等级,当风险等级超过设定阈值时,发出风险预警。
51、与现有技术相比,本发明的基于大数据与人工智能的不动产金融风险防控方法及系统,具有如下有益效果:
52、1.提高了风险预测的准确性:本发明利用大数据分析处理和分析大量历史和实时数据,从而提供更为精确的风险评估,利用风险预测模型能够识别数据中的不动产金融风险。
53、2.动态风险监控:通过持续监控市场变动和实时数据,本发明能够即时更新风险评分,快速反应市场变化,及时调整风险等级,确保了风险评估的时效性和准确性。
54、3.提升了决策制定效率:自动化的风险评估流程减少了人工操作的时间和错误,提升了决策过程的效率。明确的风险等级帮助决策者快速做出贷款审批、资产管理和风险控制的决策。
55、4.减少人为偏差:基于客观的数据分析和模型预测,减少了人为因素在风险评估中的影响,提升了评估的客观性;并可以根据不同的市场环境和数据源进行调整,确保了其广泛的适应性和可扩展性;支持多种数据格式和来源,便于与现有的金融信息系统集成。
56、5.优化了资源配置:通过精确的风险分级,可以更优化地分配资本和资源,利于不动产的风险可控调整。
57、本发明的这些方面或其他方面在以下实施例的描述中会更加简明易懂。应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
- 还没有人留言评论。精彩留言会获得点赞!