一种境外互联网社交阵地多模态数据识别方法与流程
本发明涉及网络信息处理,具体为一种境外互联网社交阵地多模态数据识别方法。
背景技术:
1、在当前的境外互联网社交阵地,多模态数据识别方法主要围绕着文本、图像和声音等多种数据类型的综合分析和处理。这些方法的核心目标是从复杂和异质的社交媒体内容中提取有价值的信息。其中文本分析包括自然语言处理、机器翻译、关键词和主体识别;图像识别包括计算机视觉、图像分类和标注、面部识别;声音分析包括语音识别、情感分析、声音特征识别;多模态融合包括数据融合、上下文理解;
2、这些多模态数据识别方法在多语言互联网社交平台上的应用,通过结合不同类型的数据分析技术,可以更全面地理解和利用社交媒体中的复杂数据。随着技术的发展,这些方法在提升准确性和效率方面有着巨大的潜力。
技术实现思路
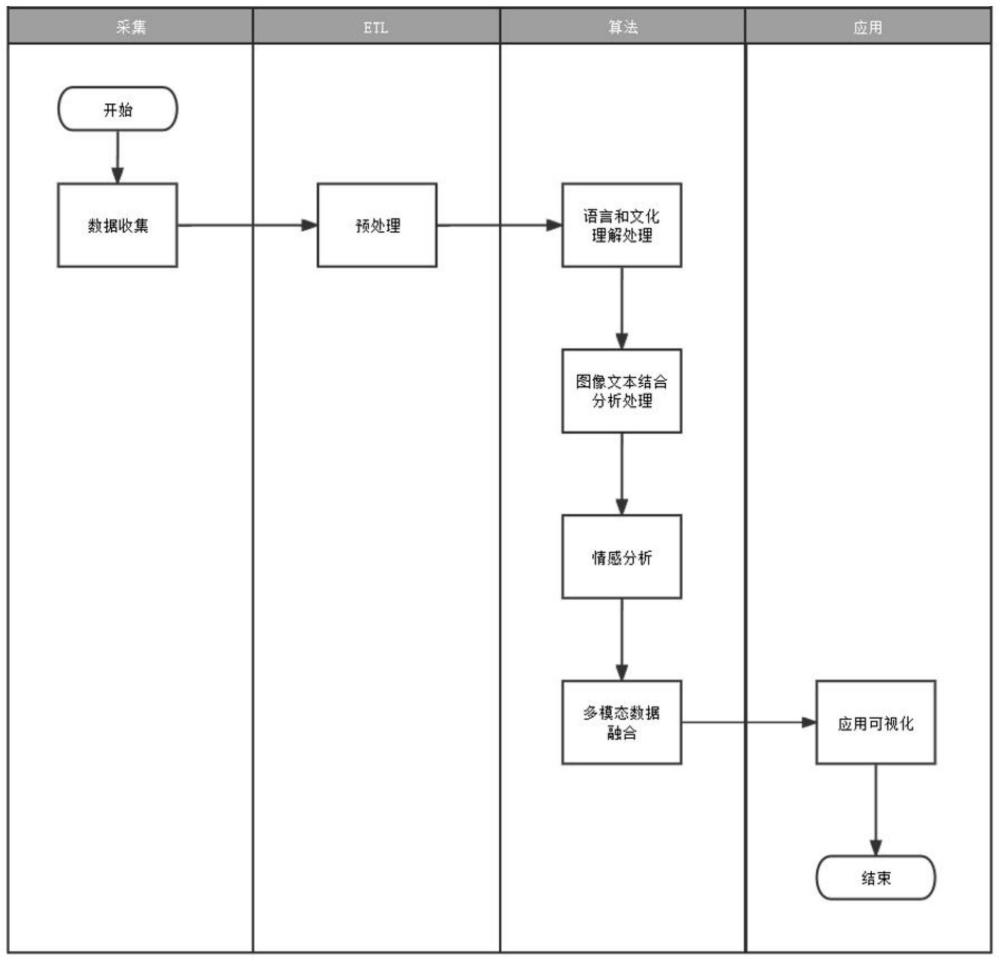
1、鉴于现有技术中所存在的问题,本发明公开了一种境外互联网社交阵地多模态数据识别方法,包括步骤如下:
2、步骤一、数据收集:从社交媒体平台收集多种形式的数据,包括文本、图像、声音,确保数据集的多样性,包括不同地区、语言的数据;
3、步骤二、预处理:对收集到的数据进行清洗和格式化,以便于进一步处理,具体的,对于文本数据,进行分词、去除停用词、词性标注的预处理步骤;对于声音数据,进行降噪、分段、特征提取的预处理工作;对于视频数据,进行格式转换、分辨率调整、帧提取与采样、去噪与增强、目标检测与跟踪、音轨提取、特征提取的预处理工作;
4、步骤三、增强的语言和文化理解:使用高级自然语言处理技术来分析文本数据,包括跨语言翻译和文化背景分析;应用机器学习和人工智能算法来理解不同语言和文化的特定表达方式;
5、步骤四、深入的图像-文本分析:利用计算机视觉技术分析图像内容,并将其与相关文本数据结合,以提高对图像-文本关联的理解,具体的:
6、(1)图像处理与特征提取:使用计算机视觉算法(如卷积神经网络)来处理图像并提取关键特征;这些特征包括图像中的对象、颜色、形状、纹理;
7、(2)文本处理:对相关文本数据进行处理,这可能包括自然语言处理技术,如分词、词性标注、命名实体识别等。提取文本中的关键词、短语或特定的概念;
8、(3)关联分析:使用生成对抗网络(gan)或变分自动编码器(vae)模型,让模型学会生成与图像相关的文本描述或生成与文本相关的图像;这些模型可以用于学习图像和文本之间的双向关联;
9、步骤五、精细化的情感分析:采用情感分析技术处理文本和声音数据,以识别和分析用户的情感和情绪;
10、步骤六、多模态数据融合和上下文分析:结合不同类型的数据(如文本、图像、声音),并利用上下文信息来提供更全面的分析;具体的:
11、(1)上下文分析:上下文理解:分析数据在特定环境下的含义;如社交媒体帖子的背景信息、发布时间、地点等。关联分析:识别不同数据之间的关联性和相互作用;
12、(2)数据融合:特征融合:将从文本、图像和声音中提取的特征结合起来,形成统一的特征表示;模型融合:使用多模态融合模型(如混合神经网络)来整合不同类型数据的处理结果。
13、步骤七、解析与应用:将分析结果用于市场趋势分析、用户行为研究、内容推荐等。
14、作为本发明的一种优选方案,步骤三具体包括:
15、(1)多语言语料库的收集与分析:收集和整理来自不同文化和语言的大量文本数据,包括书籍、新闻报道、社交媒体帖子,分析这些数据,寻找语言表达中的文化特征,如俚语、惯用语和特定的表达习惯;
16、(2)跨文化语境下的语义映射:使用nlp技术(如词义消歧、语义角色标注)来理解不同文化中词汇的具体含义和使用方式,通过比较不同文化中相似概念的表达方式,建立语义映射,这有助于理解文化差异下的语言使用。
17、(3)深度学习和机器学习模型的应用:利用深度学习模型(如transformer、bert等)来提取和理解跨文化文本的复杂特征,使用机器学习算法对跨文化数据进行训练,使模型能够识别和适应不同文化背景下的语义差异;
18、(4)持续的优化和迭代:定期更新和优化模型,以适应语言和文化的不断变化;收集和分析用户反馈,持续改进跨文化语义理解的准确性和适应性。
19、作为本发明的一种优选方案,步骤五具体包括:
20、(1)情感分析模型:文本情感分析:使用自然语言处理技术,如情感分类模型(可能基于机器学习或深度学习),来分析文本中的情感倾向;这些模型通常基于大量标注数据进行训练,能够识别正面、负面或中性情绪;声音情感分析:通过声学特征(如音高、音量、语速)来分析情感,可以使用深度学习模型来识别声音中的情绪特征,如愤怒、快乐、悲伤等;
21、(2)模型训练与优化:针对具体的数据集训练模型,并通过交叉验证、参数调优等方法进行优化,以提高模型的准确性和泛化能力;
22、(3)集成与分析:将文本和声音的情感分析结果集成,以获得更全面的情感理解,例如,某些情绪可能在文本中不明显,但在声音中表现得非常清晰。
23、本发明的有益效果:本发明针对跨语言和文化理解的提升、图像与文本之间深层关联的分析、情感分析的准确性和多样性提升,以及多模态数据融合和上下文分析的优化,有助于更准确地处理和理解多语言互联网社交平台上的复杂和异质数据,从而提供更深入、全面的内容分析和用户行为洞察。通过这些技术创新,可以显著提高数据处理的准确度和效率,特别是在多语言和多元文化的互联网社交环境中,更好地满足多元化和国际化的社交媒体环境需求。
技术特征:
1.一种境外互联网社交阵地多模态数据识别方法,其特征在于,包括步骤如下:
2.根据权利要求1所述的一种境外互联网社交阵地多模态数据识别方法,其特征在于:步骤三具体包括:
3.根据权利要求1所述的一种境外互联网社交阵地多模态数据识别方法,其特征在于:步骤五具体包括:
技术总结
本发明涉及一种境外互联网社交阵地多模态数据识别方法。本发明针对跨语言和文化理解的提升、图像与文本之间深层关联的分析、情感分析的准确性和多样性提升,以及多模态数据融合和上下文分析的优化,有助于更准确地处理和理解多语言互联网社交平台上的复杂和异质数据,从而提供更深入、全面的内容分析和用户行为洞察。通过这些技术创新,可以显著提高数据处理的准确度和效率,特别是在多语言和多元文化的互联网社交环境中,更好地满足多元化和国际化的社交媒体环境需求。
技术研发人员:陈学言,王波,王垒
受保护的技术使用者:广东数源智汇科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!