一种证据信息按需组织与精准分发方法与流程
本发明涉及人工智能和大数据,特别是一种证据信息按需组织与精准分发方法。
背景技术:
1、证据是指支撑人们在生活工作中做出重要决策信息,如专家在制定前沿技术清单时,需要相关技术的近年专利论文数、基金项目投资额、重要研发机构与研发人员信息等数据,即证据信息,专家通过证据计算研判各类技术的新兴度、技术重要性、技术投入度等,最终综合得到前沿技术清单。
2、随着信息化时代的建设,使证据素材越来越多可有效支撑决策正确性的提升,但也使得数据信息呈现爆炸式增长,海量数据使人们耗费大量时间、经历在证据的寻找过程中,制约研究进度。
技术实现思路
1、鉴于此,本发明提供一种证据信息按需组织与精准分发方法。
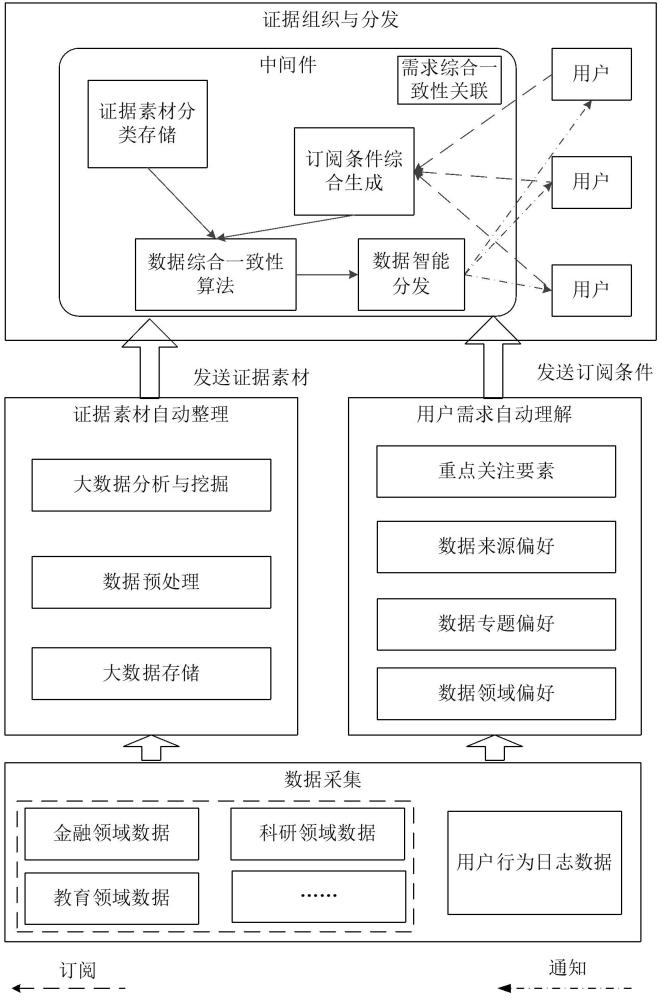
2、本发明公开了一种证据信息按需组织与精准分发方法,其包括:
3、步骤1:爬取网络上多个领域的相关数据信息并对其进行预处理,并对预处理得到的数据进行结构化存储,得到数据的规范化存储数据集;
4、步骤2:自动搜集用户行为日志,通过爬取服务器的数据和日志,获得用户行为数据,对用户进行需求画像,提炼总结出用户的需求,生成候选用户订阅条件;该需求包括数据领域偏好、专题偏好、数据来源偏好和重点关注要素;
5、步骤3:基于候选用户订阅条件和根据用户需求的输入订阅条件,生成综合约束集合,将满足综合约束集合的规范化存储数据集添加到匹配数据集中,并将得到的匹配数据集推送分发给用户。
6、进一步地,所述步骤1包括:
7、步骤11:构建分布式数据存储架构,设计三个存储模块,分别存储结构化、半结构化和非结构化的数据信息;
8、步骤12:对数据进行预处理包括对数据进行时间对齐、空间对齐、属性补齐与去除冗余以及删除不准确与不完整数据;
9、步骤13:运用通用信息抽取技术,提取经过预处理的数据,并将其进行结构化存储,最终得到数据的规范化存储数据集。
10、进一步地,在所述步骤12中,对数据进行时间对齐,包括:
11、首先,利用uie通用信息抽取技术得到数据的发布时间和时间修饰字符,其中,时间修饰字符包括大前天、前天、昨天、明天和后天;
12、其次,通过查表方式得到时间转移值与时间修饰字符的映射关系;
13、最后,将基准时间的规范表达式和偏移时间规范表达式对应的时间单位上的数值进行求和,得到数据发生时间的初始规范化表达,所采用的公式为:
14、
15、其中, g表示时间粒度,同时,基于不同时间单位的取值范围,对进行处理,即让中的年、月、日、时和分时间单位满足时间规范,规范后的时间结果记为时间的规范式表达;
16、对数据进行空间对齐,包括:
17、首先,利用uie通用信息抽取技术,得到数据中的地点名称,设数据中的空间名称为和,则空间名称可表示为多个地点名称单元的组合,即,其中,,表示所有地点名称单元组成的集合,表示第i个地点名称,表示第m个地点名称;,其中,,表示第j个地点名称,表示第n个地点名称;
18、取自然数;若=,p=1,2,...,q,则;通过如下计算公式,得到对空间名称的趋同值:
19、
20、其中,表示空间名称与空间名称的趋同值,表示空间名称与空间名称的趋同值;
21、令,则表示与两个空间名称的趋同值;如果空间名称之间的趋同值超过给定的阈值,则认为两个空间名称是同一个地点名称,实现空间对齐。
22、进一步地,在所述步骤12中,对数据进行属性补齐与去除冗余,包括:
23、首先,构造数据特征集合,利用uie通用信息抽取技术抽取数据的属性,得到数据的规范化表达式,其中,event表示数据本身,表示数据的第i个属性;表示数据属性数量;属性包括时间、地点、人物、实体、主题、类型和触发词;
24、其次,采用数据综合一致性算法,数据event的文本信息经过bert模型的embedding层,转化为文本语义向量,计算任何两个数据的语义一致性con_sem,其中,为数据event文本语义向量中的第k个维度分量, p表示数据event文本语义向量的维数;
25、在语义一致性的基础上,对数据的每个属性进行一致性检验,即属性一致性con_pro,最后得到数据间的综合一致性con_com。
26、进一步地,所述计算任何两个数据的语义一致性con_sem,包括:
27、假设任意两个数据的语义向量分别为、,其中,event1表示第一个数据,为数据event1文本语义向量中的第a个维度分量, p表示数据event1文本语义向量的维数,event2表示第二个数据,为数据event2文本语义向量中的第a个维度分量, p表示数据event2文本语义向量的维数,则数据event1和数据event2的语义一致性为:
28、
29、其中,表示数据语义一致性计算函数;
30、根据两个数据的语义向量在高维语义向量空间的夹角余弦值,判断该两个数据的语义向量是否一致,如果越趋一致,则夹角越小,其余弦值越大,即越大。
31、进一步地,所述对数据的每个属性进行一致性检验,即属性一致性con_pro,包括:
32、,其中表示数据event1的第i个属性,,其中表示数据event2的第i个属性;
33、将同一属性的一致性记为con_pro,和在第k个属性分别有和个元素,分别记为集合和,和分别表示和在第k个属性中的第i个和第j个元素,对每一个和运用bert模型的embedding层,得到向量表达形式和,其中表示在第k个属性中的第i个元素的语义向量中的第r个维度分量,表示在第k个属性的第j个元素的语义向量中的第r个维度分量,p表示语义向量的维度;记num=0,计算和的一致性;如果,则认为元素和相同,此时,num =num+1,最终得到两个数据在属性k的属性一致性con_pro:
34、
35、其中,表示两个数据属性一致性计算函数,num是计数参数,用于计量两个数据在属性k中相同属性元素的个数,表示求一个集合内元素的个数,如果两个集合中一致的元素越多,表明两个集合越一致,即两个数据在该属性的一致性越高,越大。
36、进一步地,所述得到数据间的综合一致性con_com,包括:
37、得到数据和在所有属性的综合一致性,记count=0,当两个数据的属性k一致时,count=count+1,得到和的综合一致性,如下式所示:
38、
39、其中,表示数据的综合一致性计算函数,count是计数参数,用于计量两个数据相同属性的个数;
40、最后,判断数据集的综合一致性,如果,且,则表明数据和在语义上和属性一致数量上均满足需求,即认为数据和数据是同一数据,对其进行属性元素的融合,实现数据补充与冗余剔除;其中,和是两个独立的数据一致性判断阈值,分别用于判断两个数据集在语义一致性方面是否满足条件,以及在综合一致性方面是否满足给定阈值条件。
41、进一步地,所述步骤3包括:
42、步骤31:用户根据自身需求,输入订阅条件,其中表示用户录入的第个需求;结合步骤2得到的候选用户订阅条件,记为,其中表示机器提炼得到用户的第个需求,判断候选用户订阅条件和输入订阅条件的一致性,最终生成综合约束集合;
43、步骤32:通过数据综合一致性算法计算规范化存储数据集中的各数据和综合约束集合之间的属性一致性及该属性下的要素一致性,如果数据的属性一致性及该属性下的要素一致性均满足阈值要求,即该数据满足综合约束集合,并将其添加到匹配数据集中;
44、步骤33:将匹配数据集推送给用户,实现数据信息按需组织分发。
45、进一步地,所述步骤31包括:
46、首先,按照数据的属性,分别对候选用户订阅条件和输入订阅条件进行划分,获得约束集合,其中,表示约束中的第j个属性,每个属性下有多个约束要素,则属性j下的约束要素集为,同理可得到输入订阅条件的第j个属性下的约束要素集,;
47、其次,运用数据一致性算法计算候选用户订阅条件和输入订阅条件在相同属性k下的要素一致性,以及属性k的一致性;如果超过阈值,则认为候选用户订阅条件和输入订阅条件的相同属性k是一致的;
48、最后,如果,则认为和是两个不同的约束要素,将和都加到综合约束集合中;如果,则认为这两个约束要素一致,只保留约束要素在综合约束集合中,最终形成综合约束集合;其中,表示判断约束要素是否为同一约束的阈值。
49、进一步地,所述步骤32包括:
50、针对步骤1得到的规范化存储数据集,记为,是第q个数据,,表示数据的第个属性,其下有多个属性要素,综合约束集合,是约束条件的属性,每个属性下有多个约束要素,判断数据是否满足订阅条件的综合约束集合c,只需计算集合和综合约束集合c之间的一致性即可,通过数据综合一致性算法得到和,如果和分别满足给定的阈值要求,即,,则表明证据规范化存储数据集e中的第q个数据满足综合约束集合c,此时,将添加到匹配数据集te;同时,根据一致性的结果决定推荐优先级,即一致性越高,在匹配数据集te中的推荐顺序越靠前;其中,和分别表示证据与订阅条件的语义一致性阈值和综合一致性阈值。
51、由于采用了上述技术方案,本发明具有如下的优点:通过对用户需求的精准把握,实现证据信息的高效、精准组织与分发,支撑用户研究的有序、高效开展。
- 还没有人留言评论。精彩留言会获得点赞!