一种基于大语言模型的个性化对话生成方法及系统
本发明属于自然语言处理领域,具体涉及基于大语言模型的个性化对话生成方法及系统。
背景技术:
1、开发像人类的对话系统是人工智能领域的一个重要主题,其中赋予聊天机器人人物个性信息是当中重要挑战之一。赋予聊天机器人人物个性信息,可以让机器人有了明确记忆,避免只根据最近的对话历史做出应,有效解决了传统的人机对话时机器人缺乏个性和特殊性的问题。现在已经有了用非结构化文本来描述人物个性信息的数据集,基于该数据集训练出的对话模型已经可以捕捉给定的人物个性化信息的简单含义,从而进行个性化对话回复。
2、然而,构建高质量的个性化对话数据集既昂贵又耗时,这限制了数据集的大小。现有数据集中的一个对话过程中,对人物个性化信息描述只有4~5句话,这导致了个性化对话中人物个性信息不足问题,聊天机器人很难回答超出预定义的人物个性信息的问题并且生成的回复还会与预定义的人物个性信息不一致。已有模型使用知识生成器通过常识性推理来扩展人物个性化信息,但这扩展仅限于一般的社会常识,并不是以人物个性信息为中心的知识框架。此外,个性化对话生成过程中需要额外考虑人物个性信息和对话历史,根据对话中的不同情境将这两者进行动态调整融合,生成的回复包含流畅性不足、信息冗余等问题。
技术实现思路
1、本发明提供了一种基于大语言模型的个性化对话生成方法及系统,可以有效扩展人物个性信息,并将对话历史和人物个性信息进行动态调整融合,生成能力生成更丰富、多样化和流畅的回复。
2、为达到上述目的,本发明所采用的技术方案是:
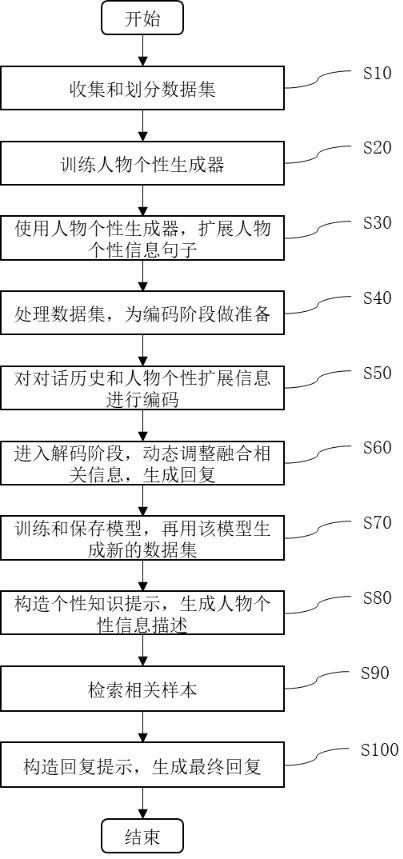
3、本发明第一方面提供了一种基于大语言模型的个性化对话生成方法,包括:
4、获取人物个性对话数据集合,对人物个性对话数据集合进行个性扩展获得人物个性扩展对话数据集;
5、利用预训练的融合模型对人物个性扩展对话数据集中的目标回复进行更新,构成新的个性对话数据集;
6、获取大型语言模型的当前对话历史信息,基于当前对话历史信息和人物个性扩展对话数据集中的人物个性扩展信息构造个性知识提示;
7、将个性知识提示输入至大型语言模型获得人物个性信息描述信息,由新的个性对话数据集中检索与大型语言模型当前对话历史信息的相关样本信息;根据所述相关样本信息、当前对话历史信息和人物个性信息描述信息生成回复提示;将回复提示重新输入至大型语言模型获得最终回复信息。
8、进一步地,对人物个性对话数据集合进行个性扩展获得人物个性扩展对话数据集,包括:
9、获取人物个性知识图谱数据集合,利用人物个性知识图谱数据集合对人物个性生成器进行训练;
10、利用训练后的人物个性生成器对人物个性对话数据集中的人物个性信息句子进行扩展获得人物个性扩展信息,利用句子匹配模型对人物个性对话数据集中的对话历史匹配人物个性扩展信息,得到人物个性扩展对话数据集。
11、进一步地,对所述融合模型进行训练过程包括:
12、由人物个性扩展对话数据集提取对话历史序列h,人物个性扩展信息序列p和目标回复序列t并做为输入序列;
13、通过对话历史编码器将对话历史序列h转化为对话历史编码向量;通过人物个性扩展信息编码器将人物个性扩展信息序列p转化为人物个性扩展信息编码向量;将对话历史编码向量、人物个性扩展信息编码向量和目标回复序列t输入至解码器获得初始回复;根据初始回复和输入序列计算训练损失值,根据训练损失值对融合模型的参数进行优化,重复迭代所述融合模型的训练过程直至训练损失值收敛,输出并保存训练后的融合模型。
14、进一步地,由人物个性扩展对话数据集提取对话历史序列h,人物个性扩展信息序列p和目标回复序列t,包括:
15、对人物个性扩展对话数据集中的对话历史数据用特殊令牌“”和“”拼接起来,形成对话历史输入序列,和代表用户话语,代表机器人的回复;
16、对人物个性扩展对话数据集中的目标回复数据需要在前面添加特殊令牌“”,形成目标回复输入序列;
17、对人物个性扩展对话数据集中的人物个性扩展数据用特殊令牌“”,“”和“”,形成人物扩展信息输入序列;其中,代表第i个人物个性信息句子;代表第i个人物个性信息句子的第1个关系;代表第i个人物个性信息句子的第1个扩展属性;
18、利用分词器对所述对话历史输入序列、目标回复输入序列和人物扩展信息输入序列分别转化得到对话历史向量序列h,人物个性扩展信息向量序列p和目标回复向量序列t。
19、进一步地,通过对话历史编码器将对话历史序列h转化为对话历史编码向量,包括:
20、;
21、公式中,是基于transformer模型架构的对话历史编码器。
22、进一步地,通过人物个性扩展信息编码器将人物个性扩展信息序列p转化为人物个性扩展信息编码向量,包括:
23、将人物个性扩展信息序列p输入至自注意力获得信息序列,使用公式:
24、;
25、公式中,表示为自注意力机制;
26、将自注意力向量输入至图感知注意力获得编码向量,表示公式为:
27、;
28、公式中,q、k 和 v 是由自注意力向量与相应的可学习参数、可学习参数和可学习参数相乘得到的序列,表示为序列k的维度;则是编码所需图结构的掩码,表示为类型编码矩阵;
29、将编码向量进行加和与规范化处理后输入至前馈神经网络中,再经过一次加和与规范化输出人物个性扩展信息编码向量。
30、进一步地,将对话历史编码向量、人物个性扩展信息编码向量和目标回复序列t输入至解码器获得初始回复,包括:
31、将目标回复序列t输入到解码器中的自注意力机制获得自注意力结果,公式为:
32、;
33、公式中,表示为自注意力机制;
34、将对话历史编码向量、人物个性扩展信息编码向量分别与自注意力结果进行交叉注意力计算获得人物个性扩展信息交叉注意结果和人物个性扩展信息交叉注意结果,公式为:
35、;
36、;
37、其中,表示交叉注意力机制函数;
38、将自注意力结果和人物个性扩展信息交叉注意结果进行拼接输入至全连接层,生成角色信息的权重,公式为:
39、;
40、其中,sigmoid是一个激活函数,fc是全连接层;
41、基于权重计算出输入源的掩码mp和掩码mh,公式如下:
42、;
43、;
44、其中,是二进制指示器,是一个超参数;
45、应用掩码对人物个性扩展信息交叉注意结果和人物个性扩展信息交叉注意结果进行加权求和获得融合结果res,公式为:
46、;
47、将融合结果res输入至前馈神经网络后,经过加和与规范化以及线性层得到初始回复。
48、进一步地,根据初始回复和输入序列计算训练损失值,包括:
49、;
50、其中,表示为训练损失值,代表初始回复序列中的第i个单词,表示输入序列,表示融合模型基于给定输入序列和已生成的初始回复序列预测的下一个单词的概率分布。
51、本发明第二方面提供了一种基于大语言模型的个性化对话生成系统,包括:
52、获取模块,用于获取人物个性对话数据集合,对人物个性对话数据集合进行个性扩展获得人物个性扩展对话数据集;
53、扩展模块,用于利用预训练的融合模型对人物个性扩展对话数据集中的目标回复进行更新,构成新的个性对话数据集;
54、提示模块,用于获取大型语言模型的当前对话历史信息,基于当前对话历史信息和人物个性扩展对话数据集中的人物个性扩展信息构造个性知识提示;
55、回复模块,用于将个性知识提示输入至大型语言模型获得人物个性信息描述信息,由新的个性对话数据集中检索与大型语言模型当前对话历史信息的相关样本信息;根据所述相关样本信息、当前对话历史信息和人物个性信息描述信息生成回复提示;将回复提示重新输入至大型语言模型获得最终回复信息。
56、本发明第三方面提供了电子设备包括存储介质和处理器;所述存储介质用于存储指令;所述处理器用于根据所述指令进行操作以执行本发明第一方面所述的方法。
57、与现有技术相比,本发明的有益效果:
58、本发明获取人物个性对话数据集合,对人物个性对话数据集合进行个性扩展获得人物个性扩展对话数据集;利用预训练的所述融合模型对人物个性扩展对话数据集中的目标回复进行更新,构成新的个性对话数据集;弥补了之前以往只使用常识推理器进行扩展的方法,可以有效的动态融合人物个性扩展信息和对话历史并且能够去除冗余信息。
59、本发明获取大型语言模型的当前对话历史信息,基于当前对话历史信息和人物个性扩展对话数据集中的人物个性扩展信息构造个性知识提示;将个性知识提示输入至大型语言模型获得人物个性信息描述信息,由新的个性对话数据集中检索与大型语言模型当前对话历史信息的相关样本信息;根据所述相关样本信息、当前对话历史信息和人物个性信息描述信息生成回复提示;将回复提示重新输入至大型语言模型获得最终回复信息;利用了大型语言模型的固有知识和强大生成能力,从而提高了最终回复的多样性和流畅性。
- 还没有人留言评论。精彩留言会获得点赞!