一种用于智能文档审阅系统的文档查重方法及存储介质与流程
本发明涉及自然语言处理,尤其是涉及一种用于智能文档审阅系统的文档查重方法及存储介质。
背景技术:
1、随着自然语言处理技术不断成熟,企业逐步开始通过云文档的方式进行办公。随着智能云文档的普及,对于智能文档的业务需求也日渐增加。其中对于智能文档审阅系统中的云文档查重的业务需要也越来越多样化。
2、在现有的对文档进行查重,也就是文档之间的相似度衡量过程中,其主要是通过分词将文档分割为一个个词语,之后对每个词进行词向量转换如,词袋模型、tf-idf模型,或是词嵌入如word2vec、glove等模型来完成,这些模型可以将每个单词映射为一个高维空间中的向量。在完成词嵌入之后,则将词向量根据分词过程中获取到的句子进行合并,再由句子合并为文档,这样就获取到了文档对应的文档向量。最后通过需要进行查重的两个文档向量的余弦相似度进行相似程度的衡量。上述过程如图1所示。
3、但现有技术还存在查重准确率较低等问题。因为在现有的文档查重过程中,对于文档之间的相似程度在本质上是根据文档中每个词在词嵌入过程中获取的词向量之间的相似性决定的,所以现有的文档查重方法存在着同样的语义但是通过不同的词语进行描述的句子无法准确进行查重的情况。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的文档查重过程中对于同义不同词的内容无法被准确查重的问题,而提供一种用于智能文档审阅系统的文档查重方法及存储介质。
2、本发明的目的可以通过以下技术方案来实现:
3、一种用于智能文档审阅系统的文档查重方法,包括以下步骤:
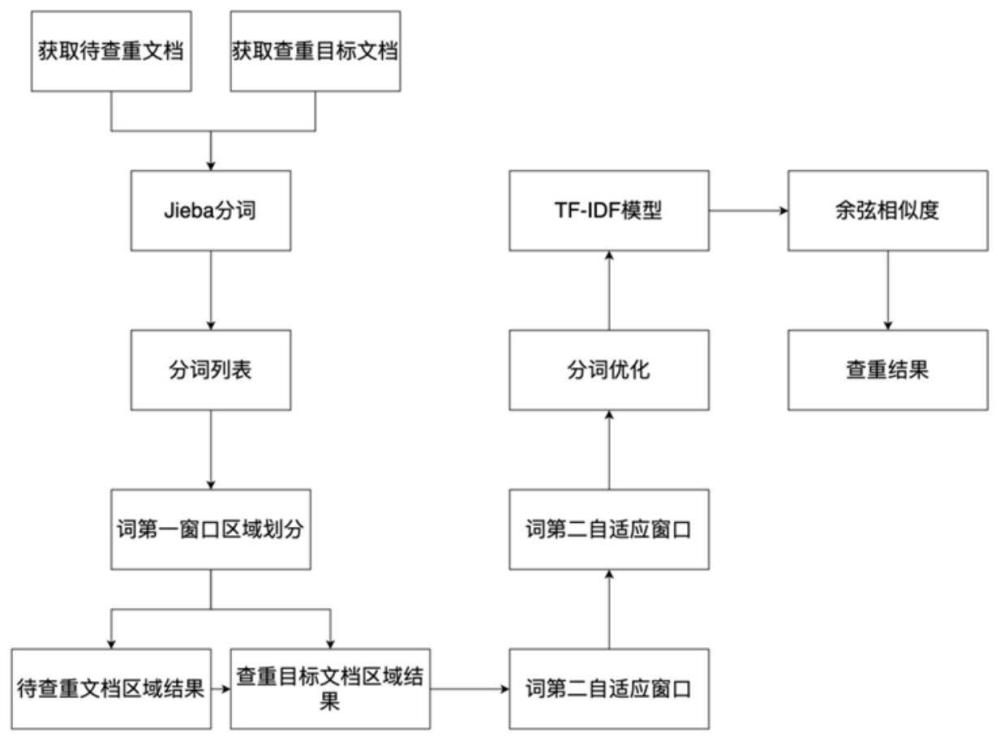
4、获取待查重文档与查重目标文档的初始分词结果;
5、针对待查重文档与查重目标文档,分别通过分词窗口进行文档区域划分;
6、基于文档区域划分结果,通过不同区域的自适应窗口进行所述初始分词结果的优化,获得优化分词结果;
7、通过tf-idf模型基于所述优化分词结果进行向量化处理,分别获得待查重文档与查重目标文档的文档特征向量;
8、通过待查重文档与查重目标文档的文档特征向量之间的余弦相似度获取待查重文档的文档重复程度。
9、进一步地,通过jieba分词获取待查重文档与查重目标文档的所述初始分词结果。
10、进一步地,所述通过分词窗口进行文档区域划分具体包括:
11、设定局部窗口范围,以某个词为中心词,基于所述局部窗口范围向左右扩展,获得文档中每个词的分词第一窗口;
12、基于各分词第一窗口之间的距离,确定每个词的分词第一窗口的最近邻窗口,并统计各分词第一窗口的最近邻窗口的数量;
13、基于所述各分词第一窗口的最近邻窗口的数量计算文档中每个词的可分割程度;
14、基于设定的分割点数量n,选择可分割程度最高的前n个词,在词的右侧进行分割,进而实现文档区域划分。
15、进一步地,计算两个分词第一窗口之间的距离前,先判断两个分词第一窗口所对应的中心词是否一致,仅在一致时进行距离计算。
16、进一步地,两个分词第一窗口之间的距离计算时,对于两个窗口中的词依次根据与中心词的距离进行向外扩充,对于每一个扩充的相似词数量占比进行均值计算,并以此作为两个词的第一窗口之间的距离。
17、进一步地,通过对各分词第一窗口的最近邻窗口的数量通过softmax进行归一化,获得词的可分割程度。
18、进一步地,所述通过不同区域的自适应窗口进行所述初始分词结果的优化具体包括:
19、根据文档区域划分结果,计算待查重文档与查重目标文档之间不同区域间的区域相似程度,获得待查重文档中的各区域在查重目标文档中的最大相似程度区域;
20、基于待查重文档中的各区域与对应最大相似程度区域的比对,自适应确定区域中每个词的分词第二窗口;
21、基于所述分词第二窗口对分词第二窗口进行填充,实现初始分词结果的优化。
22、进一步地,通过区域内各词的分词第一窗口之间的跨度进行所述待查重文档与查重目标文档中两个区域之间的相似程度,进而获得待查重文档中的各区域在查重目标文档中的最大相似程度区域。
23、进一步地,所述自适应确定区域中每个词的分词第二窗口具体包括:
24、设定初始窗口长度l1;
25、对于最近邻的待查重文档区域与查重目标文档区域,对每个词通过l1长度的窗口进行区域间距离的计算;
26、迭代更新窗口长度l1=l1+1,同时更新区域间距离,在相邻两次迭代获得的区域间距离的差小于设定时停止迭代,获得最终的窗口长度;
27、以最终的窗口长度作为待查重文档对应区域中词的分词第二窗口长度,确定区域中每个词的分词第二窗口。
28、本发明还提供一种计算机可读存储介质,包括供电子设备的一个或多个处理器执行的一个或多个程序,所述一个或多个程序包括用于执行如上所述用于智能文档审阅系统的文档查重方法的指令。
29、与现有技术相比,本发明具有以下有益效果:
30、1、本发明创新性地设计分词结果优化过程,通过文档中不同的全文语义相关性判断对文档进行区域划分,并对不同的局域进行自适应的窗口确定,将自适应的分词第二窗口中的分词作为新的词加入到文档向量中,从而可以在文档中出现同义不同词的情况时,通过优化后的文档向量中的新增词进行识别,从而保证在智能文档审阅系统中可以准确地进行文档查重。
31、2、本发明创新性设计文档的上下文划分方法,通过分词第一窗口之间的最近邻关系进行单个文档的划分,可以实现对文档不同的区域进行不同的自适应分词优化,从而对于文档的不同部分通过最优的分词第二窗口进行分词结果的更新,能够对同义不同词的文档内容表述进行准确的文档查重。
32、3、本发明在分词之后通过数据点之间的分布相似性确定词窗口将词通过窗口的方式进行组合,通过词窗口来替代tf-idf向量化过程中的词统计指标,在出现同义不同词时可以通过窗口中的相似词信息进行相似度的优化,从而使得存在着同义不同词的待查重文档与查重目标文档的相似度对比结果更加准确。
33、4、本发明对分词结果增加组合来优化基于tf-idf模型获取的文档特征向量之间的余弦相似度,可以对现有的基于tf-idf模型的文档查重方法在查重过程中出现的不同词的相似性进行衡量。也就是当一个词语与另一个词在一个文档中经常伴随出现时,对于另一个文档中的伴随词会将其判断为相似,以提高文档查重过程中的相似度,从而优化智能文档审阅系统中出现的同义不同词的情况。
技术特征:
1.一种用于智能文档审阅系统的文档查重方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的用于智能文档审阅系统的文档查重方法,其特征在于,通过jieba分词获取待查重文档与查重目标文档的所述初始分词结果。
3.根据权利要求1所述的用于智能文档审阅系统的文档查重方法,其特征在于,所述通过分词窗口进行文档区域划分具体包括:
4.根据权利要求3所述的用于智能文档审阅系统的文档查重方法,其特征在于,计算两个分词第一窗口之间的距离前,先判断两个分词第一窗口所对应的中心词是否一致,仅在一致时进行距离计算。
5.根据权利要求3所述的用于智能文档审阅系统的文档查重方法,其特征在于,两个分词第一窗口之间的距离计算时,对于两个窗口中的词依次根据与中心词的距离进行向外扩充,对于每一个扩充的相似词数量占比进行均值计算,并以此作为两个词的第一窗口之间的距离。
6.根据权利要求3所述的用于智能文档审阅系统的文档查重方法,其特征在于,通过对各分词第一窗口的最近邻窗口的数量通过softmax进行归一化,获得词的可分割程度。
7.根据权利要求3所述的用于智能文档审阅系统的文档查重方法,其特征在于,所述通过不同区域的自适应窗口进行所述初始分词结果的优化具体包括:
8.根据权利要求7所述的用于智能文档审阅系统的文档查重方法,其特征在于,通过区域内各词的分词第一窗口之间的跨度进行所述待查重文档与查重目标文档中两个区域之间的相似程度,进而获得待查重文档中的各区域在查重目标文档中的最大相似程度区域。
9.根据权利要求7所述的用于智能文档审阅系统的文档查重方法,其特征在于,所述自适应确定区域中每个词的分词第二窗口具体包括:
10.一种计算机可读存储介质,其特征在于,包括供电子设备的一个或多个处理器执行的一个或多个程序,所述一个或多个程序包括用于执行如权利要求1-9任一所述用于智能文档审阅系统的文档查重方法的指令。
技术总结
本发明涉及一种用于智能文档审阅系统的文档查重方法及存储介质,所述方法包括以下步骤:获取待查重文档与查重目标文档的初始分词结果;针对待查重文档与查重目标文档,分别通过分词窗口进行文档区域划分;基于文档区域划分结果,通过不同区域的自适应窗口进行所述初始分词结果的优化,获得优化分词结果;通过TF‑IDF模型基于所述优化分词结果进行向量化处理,分别获得待查重文档与查重目标文档的文档特征向量;通过待查重文档与查重目标文档的文档特征向量之间的余弦相似度获取待查重文档的文档重复程度。与现有技术相比,本发明具有保证在智能文档审阅系统中可以准确地进行文档查重等优点。
技术研发人员:慕世勋,刘鹏
受保护的技术使用者:上海天玑科技股份有限公司
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!