基于状态序列的无人系统自主行为决策方法及相关装置
本发明涉及深度强化学习,特别是涉及一种基于状态序列的无人系统自主行为决策方法及相关装置。
背景技术:
1、近年来,智能无人系统在越来越多的场景中得到应用。强化学习使智能体能够通过最大化奖励函数来学习最优策略,但一些现实任务没有奖励功能,或者人类很难设计奖励功能。模仿学习通过直接从专家演示中学习来避免奖励函数的设计,并且在自动驾驶、机器人操纵等领域取得了很大进展。
2、传统模仿学习方法假设演示数据中包含完整的状态-动作对,但在现实中,许多专家演示可能只有状态序列,例如从视频中学习或者动作数据难以收集的情况。当前已有一些方法考虑到去解决仅使用状态序列来进行模仿学习的这一问题。例如,使用逆动力学模型推断出缺失的动作,再基于完整数据进行模仿学习。但直接通过逆动力学模型对演示数据进行补充完整,会导致后续模仿学习过程存在误差,导致最终策略效果欠佳。
3、综上,当前模仿学习方法,普遍假设演示数据完整,无法在演示数据残缺的情况下使用。
技术实现思路
1、本发明的目的是提供一种基于状态序列的无人系统自主行为决策方法及相关装置,保证了在演示数据残缺的情况下进行强化学习的效果。
2、为实现上述目的,本发明提供了如下方案:
3、一方面,本发明提供了一种基于状态序列的无人系统自主行为决策方法,包括以下步骤:
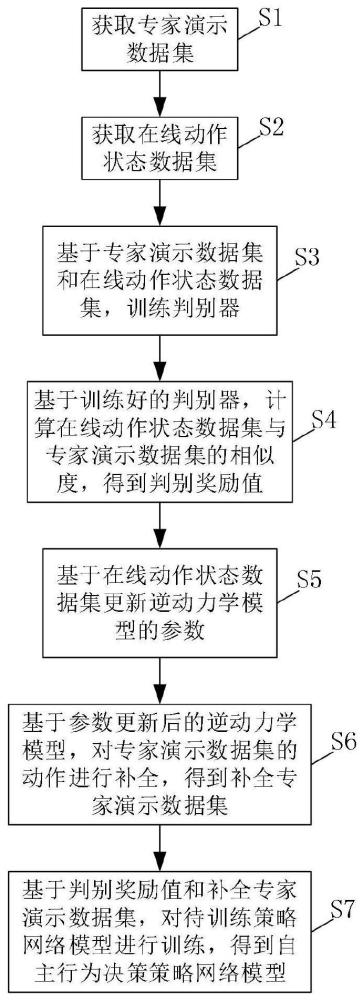
4、获取专家演示数据集;专家演示数据集中包括若干条演示轨迹序列;演示轨迹序列包括一个时序序列下连续的若干个状态数据。
5、获取在线动作状态数据集;在线动作状态数据集中包括若干条在线轨迹序列;在线轨迹序列包括一个时序序列下连续的状态数据和待训练策略网络模型在某一状态数据下采取的动作数据。
6、基于专家演示数据集和在线动作状态数据集,训练判别器,并基于训练好的判别器,计算在线动作状态数据集与专家演示数据集的相似度,得到判别奖励值。
7、基于在线动作状态数据集更新逆动力学模型的参数,并基于参数更新后的逆动力学模型,对专家演示数据集的动作进行补全,得到补全专家演示数据集。
8、基于判别奖励值和补全专家演示数据集,对待训练策略网络模型进行训练,得到自主行为决策策略网络模型。
9、可选地,基于专家演示数据集和在线动作状态数据集,训练判别器,具体包括以下步骤:
10、基于专家演示数据集,构建若干条演示状态数据对;演示状态数据对包括相邻两个状态数据。
11、基于在线动作状态数据集,构建若干条在线状态数据对;在线状态数据对包括相邻两个状态数据。
12、将演示状态数据对的标签设定为真,将在线状态数据对的标签设定为否,得到正负状态数据训练集。
13、基于正负状态数据训练集进行对抗训练,对判别器的参数进行更新,得到训练好的判别器。
14、可选地,根据下式对判别器的参数进行更新:
15、
16、其中,πθ为待训练策略网络模型,d()为判别器,s和s'为时序相邻的两个状态数据,e为数学期望,πe为专家策略。
17、可选地,根据下式计算判别奖励值:
18、rd=-log(dω(s,s'))。
19、其中,rd为判别奖励值,d()为判别器,ω为判别器的参数,s和s'为时序相邻的两个状态数据。
20、可选地,基于在线动作状态数据集更新逆动力学模型的参数,具体包括以下步骤:
21、基于在线动作状态数据集构建若干条在线动作状态数据对,得到在线动作状态数据对样本集;在线动作状态数据对包括相邻两个状态数据以及两个状态数据之间的动作数据。
22、基于在线动作状态数据对样本集,更新逆动力学模型的参数,得到参数更新后的逆动力学模型。
23、可选地,基于在线动作状态数据对样本集,更新逆动力学模型的参数,得到参数更新后的逆动力学模型,具体包括以下步骤:
24、针对任一条在线动作状态数据对,以两个状态数据作为逆动力学模型的输入,得到预测动作数据。
25、基于在线动作状态数据对的动作数据和预测动作数据,计算逆动力学模型损失。
26、基于逆动力学模型损失,更新逆动力学模型的参数,得到参数更新后的逆动力学模型。
27、可选地,根据下式计算逆动力学模型损失:
28、lidm=||a't-at||2,a't=hφ(st,st+1)。
29、其中,lidm为逆动力学模型损失,a't为预测动作数据,at为在线动作状态数据对的动作数据,hφ()为逆动力学模型,st和st+1为时序相邻的两个状态数据。
30、可选地,基于判别奖励值和补全专家演示数据集,对待训练策略网络模型进行训练,得到自主行为决策策略网络模型,具体包括以下步骤:
31、根据判别奖励值和环境奖励值,确定综合奖励值。
32、根据综合奖励值,确定优势函数值,并确定第一策略梯度。
33、将补全专家演示数据集输入到待训练策略网络模型中,确定第二策略梯度。
34、基于第一策略梯度和第二策略梯度,确定综合策略梯度。
35、基于综合策略梯度,采用梯度下降的方法更新待训练策略网络模型的参数,得到自主行为决策策略网络模型。
36、可选地,综合策略梯度如下式所示:
37、
38、其中,gpofo为综合策略梯度,grr为第一策略梯度,λ2和λ3为超参数,k为迭代次数,s为状态数据,a为动作数据,tidm为补全专家演示数据集,πθ为待训练策略网络模型,θ为待训练策略网络模型的参数。
39、另一方面,本发明提供了一种计算机设备,包括:存储器、处理器以存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序以实现上述任一项所述的一种基于状态序列的无人系统自主行为决策方法的步骤。
40、另一方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述任一项所述的一种基于状态序列的无人系统自主行为决策方法的步骤。
41、另一方面,本发明提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述任一项所述的一种基于状态序列的无人系统自主行为决策方法的步骤。
42、根据本发明提供的具体实施例,本发明公开了以下技术效果:
43、本发明提供了一种基于状态序列的无人系统自主行为决策方法及相关装置,方法包括以下步骤:获取专家演示数据集和在线动作状态数据集;基于专家演示数据集和在线动作状态数据集,训练判别器;基于在线动作状态数据集更新逆动力学模型的参数,并基于参数更新后的逆动力学模型,对专家演示数据集的动作进行补全,得到补全专家演示数据集;基于训练好的判别器,计算在线动作状态数据的判别奖励值;基于判别奖励值和补全专家演示数据集,对待训练策略网络模型进行训练,得到自主行为决策策略网络模型。本发明使用判别器对在线策略和专家演示策略的相似程度进行判断,并促使在线策略接近专家演示策略;且通过在线动作状态数据集更新逆动力学模型的参数,并基于参数更新后的逆动力学模型,对专家演示数据集的动作进行补全,保证模仿学习的效果,避免了直接使用逆动力学模型对演示数据集进行补全,导致后续模仿学习过程存在误差,最终策略效果欠佳的问题发生。
44、另外,在综合策略目标中,通过超参数使得逆动力学模型这一项在训练过程中对策略的影响逐渐减小,逐渐减少对逆动力学模型的依赖,避免误差累积,在训练早期通过该逆动力学模型加快模仿学习速度,而到了后期则可以避免该逆动力学模型对策略性能的限制,使无人系统可以学习到优于专家演示性能水平的决策策略。
- 还没有人留言评论。精彩留言会获得点赞!