隐私预算分配方法、装置、存储介质及计算机设备
本技术涉及深度强化学习,尤其涉及一种隐私预算分配方法、装置、存储介质及计算机设备。
背景技术:
1、如今,许多机器学习辅助应用都促进了人们的生活。机器学习模型的集中训练要求客户端将数据发送到中央服务器,这就带来了数据隐私泄露的风险。作为替代方案,由谷歌提出的联邦学习是一个分布式学习框架。它允许客户端通过只上传本地模型更新而不共享他们的数据来训练一个共享的机器学习模型。
2、然而,在联邦学习中仍然存在隐私泄漏的问题。现有的研究指出,上传的本地模型仍然包含关于私有训练数据的信息,导致潜在的隐私泄露风险。为了进一步加强隐私保护,提出了差分隐私联邦学习框架,在该框架中,客户可以在其本地模型中添加随机噪声,以防止他们的训练数据被攻击者区分。
3、目前,客户一般在多个通信轮次中平均地添加噪声,但由于在模型训练的早期,梯度很大,可以容忍高噪声水平。然而,随着训练的进行,梯度变小,高噪声水平会显著降低模型的精度,因此,这种隐私预算分配方式的灵活性较差,进而导致模型的精度下降。
技术实现思路
1、本技术的目的旨在至少能解决上述的技术缺陷之一,特别是现有技术中客户一般在多个通信轮次中平均地添加噪声,但由于在模型训练的早期,梯度很大,可以容忍高噪声水平。然而,随着训练的进行,梯度变小,高噪声水平会显著降低模型的精度,因此,这种隐私预算分配方式的灵活性较差,进而导致模型的精度下降的技术缺陷。
2、第一方面,本技术提供了一种隐私预算分配方法,应用于参与联邦学习的任意一个节点,所述方法包括:
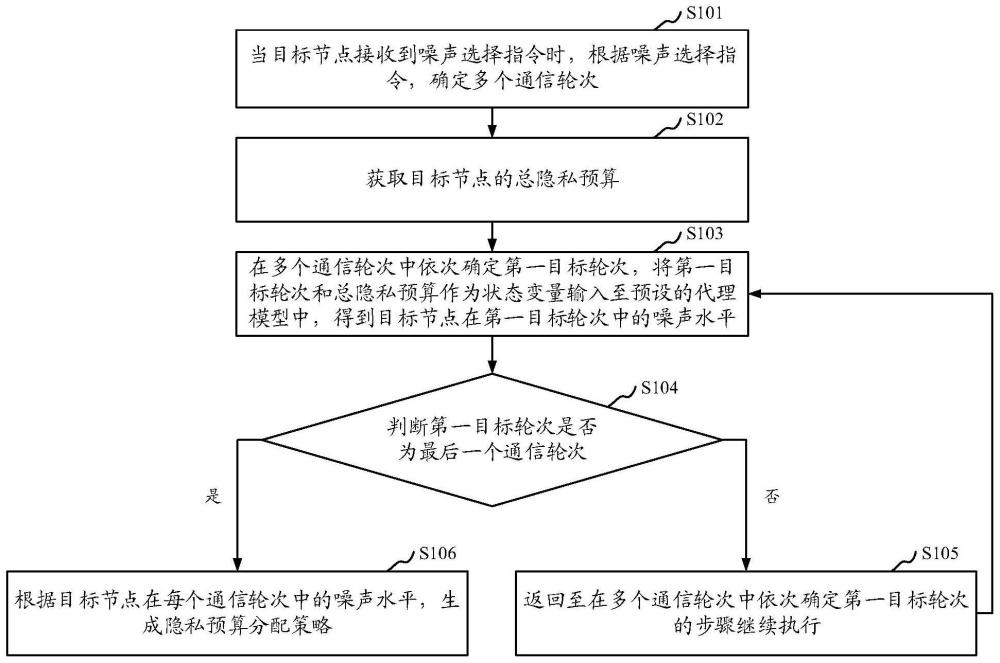
3、当目标节点接收到噪声选择指令时,根据所述噪声选择指令,确定多个通信轮次;
4、获取所述目标节点的总隐私预算;
5、在多个通信轮次中依次确定第一目标轮次,将所述第一目标轮次和所述总隐私预算作为状态变量输入至预设的代理模型中,得到所述目标节点在所述第一目标轮次中的噪声水平;
6、判断所述第一目标轮次是否为最后一个通信轮次,若否,则返回至在多个通信轮次中依次确定第一目标轮次的步骤继续执行,若是,则根据所述目标节点在每个通信轮次中的噪声水平,生成隐私预算分配策略;
7、其中,所述代理模型的训练过程,包括:
8、获取每次迭代训练的训练数据集,以对所述学习模型进行迭代训练,当迭代次数达到预设阈值时,则将最新的学习模型中的策略网络确定为代理模型;其中,所述训练数据集包括多个样本数据,每个样本数据包括状态变量、动作变量、奖励函数以及下一状态变量;所述状态变量包括通信轮次和总隐私预算,所述动作变量包括其对应轮次的噪声水平。
9、在其中一个实施例中,所述根据所述目标节点在每个通信轮次中的噪声水平,生成隐私预算分配策略,包括:
10、在预设的动作映射模块中获取仿射映射函数;其中,所述仿射映射函数包括第一参数和第二参数;
11、根据所述目标节点在每个通信轮次中的噪声水平,确定第一参数值和第二参数值;其中,所述第一参数值为所述仿射映射函数中第一参数对应的参数值,所述第二参数值为所述仿射映射函数中第二参数对应的参数值;
12、将所述第一参数值和所述第二参数值输入值所述仿射映射函数中,得到目标映射函数;
13、将所述目标节点在每个通信轮次中的噪声水平输入至所述目标映射函数中,得到所述目标节点在每个通信轮次中的目标噪声水平;
14、根据所述目标节点在每个通信轮次中的目标噪声水平,生成隐私预算分配策略。
15、在其中一个实施例中,所述对所述学习模型进行迭代训练,包括:
16、在一次迭代中,确定本次迭代对应的训练数据集,将该训练数据集中的状态变量输入至所述学习模型中的策略网络中,并确定多个第二目标轮次,以及确定每个第二目标轮次中与该训练数据集中的状态变量对应的动作变量;
17、基于预设的动作映射模块,根据每个第二目标轮次中与该训练数据集中的状态变量对应的动作变量,确定每个第二目标轮次中与该训练数据集中的状态变量对应的目标动作变量;
18、在每个第二目标轮次中,根据当前第二目标轮次中与该训练数据集中的状态变量对应的目标动作变量,对所述目标节点的本地模型进行训练,以确定当前第二目标轮次对应的奖励函数,获取样本数据集,将所述样本数据集输入至所述学习模型的评价网络中,得到动作值函数,并根据所述动作值函数对所述学习模型中的策略网络进行更新,根据当前第二目标轮次对应的奖励函数以及所述样本数据集,确定当前第二目标轮次对应的损失函数,以对所述学习模型中的评价网络进行更新;
19、当当前第二目标轮次达到预设的总通信轮次时,进入下一次迭代。
20、在其中一个实施例中,所述确定当前第二目标轮次对应的奖励函数,包括:
21、获取第一目标参数;其中,所述第一目标参数为所述目标节点在当前第二目标轮次中经过训练后的本地模型参数;
22、将所述第一目标参数发送至执行联邦学习的服务器中,并接收当前第二目标轮次中与全局模型对应的参数;其中,所述全局模型为所述服务器对参与联邦学习的节点的本地模型参数进行聚合得到的;
23、判断当前第二目标轮次是否为首个第二目标轮次,若是,则获取预设的默认参数,并将所述默认参数确定为第二目标参数,若否,则将上一第二目标轮次中所接收到的与全局模型对应的参数确定为第二目标参数;
24、根据所述第二目标参数和当前第二目标轮次中与全局模型对应的参数,生成当前第二目标轮次对应的奖励函数;其中,所述奖励函数用于衡量前后相邻第二目标轮次对应的全局模型的精度的差距。
25、在其中一个实施例中,所述根据所述动作值函数对所述学习模型中的策略网络进行更新的表达式为:
26、
27、式中,为表示策略网络的参数ψ的梯度,l为样本数据集中的样本数据的数量,n为参与联邦学习的节点的集合,为节点n在样本数据集中对应的样本数据i的状态变量,为动作值函数,表示动作值函数关于动作变量a的梯度,表示输入的状态变量为时策略网络的输出,表示策略网络关于策略网络的参数ψ的梯度。
28、在其中一个实施例中,按照以下表达式确定当前第二目标轮次对应的损失函数:
29、
30、式中,表示损失函数,l为样本数据集中的样本数据的数量,i为样本数据集中的样本数据的索引号,ri为样本数据集中的样本数据i对应的奖励函数,γ为奖励折扣系数,n为参与联邦学习的节点的集合,qφ′为目标评价网络,为节点n在样本数据集中对应的样本数据i+1的状态变量,为节点n在样本数据集中对应的样本数据i的状态变量,πψ′为目标策略网络,为节点n在样本数据集中对应的样本数据i的动作变量。
31、在其中一个实施例中,执行根据所述目标节点在每个通信轮次中的噪声水平,生成隐私预算分配策略之后,所述方法还包括:
32、在一个通信轮次中,根据所述隐私预算分配策略,对所述目标节点在该通信轮次中对应的本地模型进行训练,得到该通信轮次的本地模型参数;
33、将所述本地模型参数发送至执行联邦学习的服务器中;
34、当接收所述服务器发送的全局模型时,将所述全局模型确定为下一通信轮次中所述目标节点对应的本地模型,并进入下一通信轮次。
35、第二方面,本技术提供了一种隐私预算分配装置,应用于参与联邦学习的任意一个节点,所述装置包括:
36、信息确定模块,用于当目标节点接收到噪声选择指令时,根据所述噪声选择指令,确定多个通信轮次;
37、数据获取模块,用于获取所述目标节点的总隐私预算;
38、噪声确定模块,用于在多个通信轮次中依次确定第一目标轮次,将所述第一目标轮次和所述总隐私预算作为状态变量输入至预设的代理模型中,得到所述目标节点在所述第一目标轮次中的噪声水平;
39、轮次判断模块,用于判断所述第一目标轮次是否为最后一个通信轮次,若否,则返回至在多个通信轮次中依次确定第一目标轮次的步骤继续执行,若是,则根据所述目标节点在每个通信轮次中的噪声水平,生成隐私预算分配策略;
40、其中,所述代理模型的训练过程,包括:
41、获取每次迭代训练的训练数据集,以对所述学习模型进行迭代训练,当迭代次数达到预设阈值时,则将最新的学习模型中的策略网络确定为代理模型;其中,所述训练数据集包括多个样本数据,每个样本数据包括状态变量、动作变量、奖励函数以及下一状态变量;所述状态变量包括通信轮次和总隐私预算,所述动作变量包括其对应轮次的噪声水平。
42、第三方面,本技术提供了一种存储介质,所述存储介质中存储有计算机可读指令,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行如上述任一项实施例所述隐私预算分配方法的步骤。
43、第四方面,本技术提供了一种计算机设备,包括:一个或多个处理器,以及存储器;
44、所述存储器中存储有计算机可读指令,所述一个或多个处理器执行时所述计算机可读指令时,执行如上述任一项实施例所述隐私预算分配方法的步骤。
45、从以上技术方案可以看出,本技术实施例具有以下优点:
46、本技术提供的隐私预算分配方法、装置、存储介质及计算机设备,所述方法包括:通过代理模型能够灵活地根据当前通信轮次和目标节点的总隐私预算确定当前通信轮次所选择的噪声水平,进而根据目标节点在每个通信轮次中的噪声水平,确定隐私预算分配策略。而且,由于代理模型在训练过程中,所使用的训练数据集包括多个样本数据,每个样本数据包括状态变量、动作变量、奖励函数以及下一状态变量;而状态变量包括通信轮次和总隐私预算,动作变量包括其对应轮次的噪声水平,如此,能够通过灵活调整目标节点在每个通信轮次的噪声水平,在保证数据安全性的同时,降低所增加的噪声对执行联邦学习的服务器中的全局模型的精度的影响。
- 还没有人留言评论。精彩留言会获得点赞!