一种基于数据增强的两阶段工业质量预测方法
本发明专利涉及一种工业质量预测方法,在工业生产领域具有重要的应用前景。
背景技术:
1、在工业生产中,长时间的运行常常引发一系列问题,如效率下降、质量不稳,甚至造成重大损失。为应对这些问题,可以通过建立有效的监控体系是关键,预测生成过程中的关键质量变量,提高生产效率,进而实现企业的持续发展并最大化其价值。然而,工业现场复杂的生产环境与欠佳的在线测量仪器使得这一过程充满挑战。
2、此时,软测量技术应运而生,它通常包含四个步骤:(1)辅助变量的选择;(2)数据预处理;(3)软测量建模;(4)模型的应用与矫正。其最关键的部分是软测量建模,目前软测量建模方法主要分为三大类:第一原理模型(基于过程机理建模方法)、基于数据驱动建模方法和基于混合模型建模方法。第一原理模型是基于物理和化学的知识基础上,这种方法往往耗时并且难以获得的,在大多数的工业生产中无法使用。
3、随着以分布式控制系统(dcs)为代表的各类信息系统在工业中的普及,大量的历史过程数据被记录和存储,这些数据为软测量建模提供了宝贵资源。基于数据驱动的软测量技术通过分析易测的辅助变量来构建质量变量的预测模型,具有高效、低成本、实时等优势,因此在工业生产中得到了广泛应用。它不仅有助于提高生产效率、降低能耗,还能助力企业实现可持续发展和价值最大化。
技术实现思路
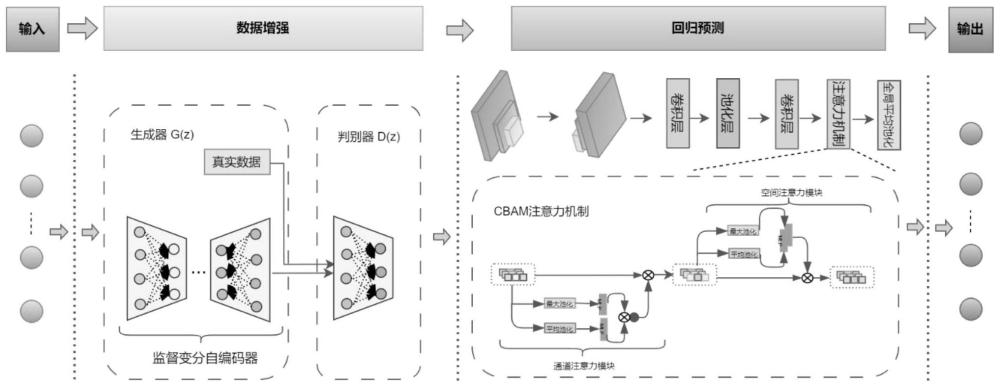
1、卷积神经网络在软测量建模中展现了其独特的优势,得益于其局部感受野和权值共享的特点。然而,基于卷积神经网络的现有软测量建模方法仍面临两大挑战:(1)许多卷积神经网络及其变体需要大量数据才能进行有效的训练。数据不足可能导致过拟合问题,进而影响质量变量的预测精度。(2)现有的生成式模型主要关注生成样本的输入,而输出则完全依赖于基于标记样本构建的模型的预测。这种方法生成的输入与输出之间的相关性有限,尤其在训练样本稀缺的情况下,会降低预测模型的准确性。此外,生成样本的多样性对于构建高性能的软测量模型也至关重要。即使使用相同的训练样本,不同的生成模型通常会生成具有一定随机性的样本,这不利于确保模型预测的稳定性。因此,针对上述两个问题,本发明提出一种基于数据增强的两阶段工业质量预测方法。
2、本发明主要包括六个部分:(1)获取数据,确定输入输出变量。(2)数据预处理。(3)构建并训练基于监督变分自编码器和对抗神经网络与梯度惩罚的数据增强模型。(4)将数据增强阶段的数据和原始数据结合得到混合数据。(5)建立基于卷积自编码器和带有注意力机制的卷积神经网络的工业质量预测模型。(6)使用混合数据训练预测模型,并用真实数据验证本发明提出的模型性能。下面详细介绍以上六部分的内容:
3、(1)、获取数据,确定输入变量和目标变量。首先,通过各种传感器和手段收集工业现场的真实数据。这些数据主要包括辅助变量,它们将作为模型的输入。而与工业过程产品密切相关的关键质量变量则被视为目标变量,用于模型的预测。
4、(2)、对数据进行预处理。真实工业场景下的数据并不能够直接使用,真实数据有部分数据存在异常,需要剔除异常数据和消除不同的辅助变量的量纲问题,增加了模型学习数据的挑战,因此这一部分主要负责对原始数据进行清洗和整理,包括去除异常值、缺失值处理以及不同量纲的归一化处理,以确保数据的一致性和准确性。
5、(3)、构建并训练基于监督变分自编码器和对抗神经网络与梯度惩罚的数据增强模型。在工程实践中,高质量数据的获取需要大量的人力和物力。如何充分利用有限的数据进行数据扩充是一个可行的方法。为了解决数据量不足的问题,采用变分自编码器和对抗神经网络进行数据增强。通过结合这两种方法来生成新的数据。这种技术可以在有限的数据基础上生成新的、多样化的样本,增强模型的泛化能力。
6、(4)、将数据增强阶段的数据和原始数据结合得到混合数据。在生成新的数据后,将增强阶段的数据与原始数据进行混合,以创建更丰富、更具代表性的训练集。
7、(5)、建立基于卷积自编码器和带有注意力机制的卷积神经网络的工业质量预测模型来预测目标变量值。这种模型结构能够更好地捕捉数据的内在特征和关联性,提高预测的准确性。
8、(6)、使用混合数据对预测模型进行训练,并用真实数据进行验证。通过比较预测结果与实际结果的误差,评估模型的性能。误差越小,模型的性能越好。
9、本发明所采用的技术方案的详细实施步骤如下:
10、步骤1:确定输入输出变量。利用各种传感器和手段获取真实工业场景下的数据,在训练数据增强模型时,挑选整个工业状况中与关键变量相关度较高的过程变量为辅助变量,必须满足其挑选的辅助变量能够简单并且容易测量。
11、步骤2:数据预处理。工业数据中采集到的实时数据往往由于传感器的问题,有部分数据存在异常,需要剔除异常数据和消除不同的辅助变量的量纲问题。因此在剔除异常数据后还需要进行最大最小归一化进行无量纲化操作,有助于提高模型的预测性能。本发明采用最大最小归一化将数据集变为[0,1]区间之内,即归一化后数据为x'=(x-xmin)/(xmax-xmin)。
12、步骤3:构建并训练基于监督变分自编码器和对抗神经网络与梯度惩罚的数据增强模型。该模型主要由对抗神经网络为基础网络,与传统对抗神经网络不同的是生成器输入的数据不是随机噪声,而是通过监督变分自编码器学习到的数据,然后与真实数据对抗训练。包括以下三个步骤:
13、步骤3.1:使用堆叠的监督变分自编码器进行数据的内部分布的学习。编码器将复杂的输入空间(x,y)映射到相对简单的潜在空间z,产生在该潜在空间上的分布,并且解码器通过编码器得到的解码z来实现输入变量的重构。堆叠的svae生成模型是svae叠加后的重建模型。通过双层svae构造深层生成模型,可以在深层挖掘重要特征。其中每一层的输入是svae已经被外部堆叠之后的前一层的输出。采用贪婪训练法逐层训练svae,然后训练整个堆叠的svae神经网络。svae模型图如图2所示。
14、步骤3.2:使用带有梯度惩罚的对抗神经网络。传统的gan训练困难,生成样本缺乏多样性,wgan解决了gan的问题,而wgan中的1-lipschitz函数可能会导致梯度消失或梯度爆炸,梯度惩罚允许生成器参数的平滑更新,并提高wgan的训练速度,gan的结构如图3所示。wgangp的损失函数定义为:
15、
16、
17、步骤3.3:采用一种新的数据增强模型ssv-wgangp,该模型利用svae的解码器作为wgan-gp的生成器。在堆叠的svae的指导下,生成器可以准确地探索输入的近似空间分布。两种神经网络可以相互补充,提高各自的模型性能,生成更接近原始样本的虚拟样本。ssv-wgangp的模型图如图4所示。ssv-wgangp模型的损失函数可以定义为
18、
19、步骤4:将数据增强阶段的数据和原始数据结合得到混合数据,创建更丰富、更具代表性的训练集。
20、步骤5:建立基于卷积自编码器和带有注意力机制的卷积神经网络的预测模型来预测目标变量值。包括以下两个步骤:
21、步骤5.1:首先通过编码学习数据的浅数据特征,然后执行解码。通过比较解码数据和原始数据之间的差异来进行训练,最终获得稳定的参数。卷积自动编码器结构如图5所示。卷积自动编码器的学习也通过重构最小损失误差来训练,对于输入数据x={x1,x2,x3,...xi},它有s个卷积核,每个卷积核由参数ws,bs组成。然后编码器得到公式:
22、hs=f(x*ws+bs)
23、其中f是relu激活函数;*表示2d卷积。通过卷积解码器对编码器的输出值进行重构,得到重构运算,如下公式所示:
24、y=f(∑h∈shs*ws+c)
25、其中f是relu激活函数;*表示2d卷积;y是重建数据;c是偏差。输入样本数据通过卷积自动编码器进行特征重构,并通过bp算法进行优化,通过使用mse可以获得完整的卷积自动编码器损失函数l(θ),如下所示:
26、
27、步骤5.2:将解码后的数据通过带有注意力机制的卷积神经网络进行处理。因其感知场特性,特别适合处理非线性数据的复杂特征。为了构建一个性能卓越的工业质量预测模型,需要充分挖掘过程数据的局部特征。而卷积神经网络恰好能满足这一需求。通过使用混合数据对注意力机制卷积神经网络进行训练,将实际数据输入至训练得到的模型中,获得关键变量的预测值。将这些预测值与真实标签进行对比,若预测值与真实值的误差较小,则证明该工业蒸汽量预测模型具有较高的有效性。
28、步骤6:模型有效性验证,将整个软测量模型训练完成后,并将模型各部分的参数保存下来。将提前处理好的测试数据通过该模型进行前向传播,得到预测值。通过指标rmse、mse、mae和r2用于评价本发明的性能。其各公式定义如下:
29、
30、
31、
32、
33、其中,n表示需要预测的样本数量,yi和分别表示样本i的真实值和预测值,是平均值。采用mae、mse和rmse三个有效性指标对结果进行评价,这三个指标都是逆的,即,指标越小,模型对应于其生成的数据的结果越好。r2解释了回归模型的方差得分,其取值范围在0和1之间。r2越接近1,模型与实际值拟合得越好。
- 还没有人留言评论。精彩留言会获得点赞!