一种地址信息的标准化治理及动态匹配的方法及设备与流程
本发明涉及人工智能数据处理领域,尤其涉及一种地址信息的标准化治理及动态匹配的方法及设备。
背景技术:
1、随着我国数字化进程的不断推进与信息化系统应用的不断普及,地址字段作为唯一标识一个地点的关键信息,准确填写符合标准的地址字段是国家政务、物流、贸易等众多领域的信息化系统操作的关键环节。然而,在实际操作过程中由于领域或行业的不同,地址字段的填写与标注也不尽相同。同时符合国家统一标准的地址必须包括行政区域名称、基本区域限定物名称、一级局部点位置描述、二级局部点位置描述等多个要素信息,呈现分级多且不同级别所描述信息较为复杂的特点,故在对原始地址信息标注化的过程中,需要耗费大量的人力进行校正处理,同时,用户在地址填写过程中存在填写时间长,费时费力且极易出现关键要素信息缺失、错字、漏字等情况,导致信息失真。因此,如何根据国家标准来统一各个领域和行业等所涉及的标准地址字段,简化用户地址填写的流程,提高填写效率和准确度成为亟待解决的问题。
技术实现思路
1、为了解决上述问题,本发明的目的在于提供一种地址信息的标准化治理及动态匹配的方法,其实现原始地址信息的自动化治理,提高地址标准化的准确率及效率,降低人工成本。
2、为实现上述目的,本发明采用以下技术方案:
3、技术方案一
4、一种地址信息的标准化治理及动态匹配方法,包括如下步骤:
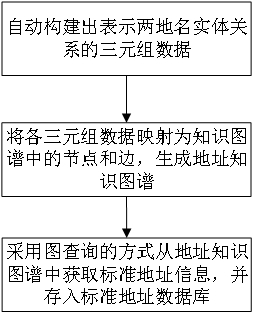
5、自动构建出表示两地名实体关系的三元组数据(地名实体1,关系,地名实体2):定义地名实体间存在的关系,为每一种关系创建初始提示和与该初始提示对应的若干示例实体对,从该些示例实体对中随机选择一个实体对插入对应的初始提示中,生成初始句子,将所述初始句子进行转述,生成多个具有相同含义的转述句子,筛选出相似度最小的若干句子作为候选句子;删除候选句子中的地名实体,每个候选句子对应生成一个新提示,将新提示按照其对应的关系类型进行集合,每种关系类型均对应生成一提示集;将所述新提示输入语言模型lm,搜索出与所有新提示均一致的新实体对;根据新提示对应的关系类型,将搜索出的新实体对与对应的类型的关系组合在一起,构建出所述三元组数据;
6、使用cypher语法将各三元组数据中的地名实体和关系分别映射为知识图谱中的节点和边,生成地址知识图谱;根据标准地址的七级行政层级关系,从所述地址知识图谱中筛选出行政层级为第七级的地址实体,然后采用图查询的方式逐级向上查询上一级行政层级的地址实体,将七级地名实体补全后,得到标准地址,将所述标准化地址保存至标准地址数据库,完成原始地址信息的标准化治理。
7、更优地,为了确保搜索出的实体对与其对应关系的一致性,还执行如下步骤:在生成所述提示集后,为体现实体对以及该实体对中的各单个地址实体与提示集中各新提示之间匹配程度,计算一新提示与其对应的各个示例实体对的匹配性得分,所述匹配性得分的计算公式为:
8、
9、 ,其中,是平衡因子,公式中的第一项是在新提示p的条件下所对应实体对为的预测概率;第二项是新提示p和实体对中单个地名实体的对数似然最小值;将该些匹配性得分经过softmax函数归一化处理后得到的值,作为该新提示的置信度权重;遍历提示集中的所有新提示,得到各新提示对应的置信度权重;所述将提示集中的新提示输入语言模型lm,所述语言模型lm搜索出与该提示集中所有新提示均一致的新实体对,其执行过程如下:预设该提示集对应的关系所需要的新实体对数量m;在搜索过程中,通过考虑单个地址实体的最小对数可能性筛选出m个一致性高的新实体对:每一个新提示输入后,存储最先搜索到的m个新实体对作为候选堆,计算每个新实体对的单体对数似然值
10、,然后按照从小到大的顺序对候选堆进行排序,将最小的单体对数似然值所对应的新实体对作为堆顶且将该单体对数似然值作为阈值;当搜索到下一个新实体对时,计算其对数似然值,若低于当前阈值,则丢弃,若高于当前阈值,则根据对数释然值的大小插入候选堆中对应的位置,同时将堆顶的新实体对推出,动态更新当前阈值;检索结束后将候选堆中新实体对存入候选集合中;将候选集合中的新实体对记为,采用构建的一致性得分函数计算出一致性分数,所述一致性得分函数计算公式为:
11、,其中,为置信度权重,p表示新提示;对候选集合中的所有新实体按照一致性分数从高到低的顺序对进行重新排序,取排名在前的n1个新实体对作为搜索结果输出;然后执行所述步骤:查询搜索出的新实体对所对应的提示集,确定该提示集对应的关系类型,将搜索出的新实体对与对应的类型的关系组合在一起,构建出所述三元组数据。
12、更优地,基于构建的所述地址知识图谱,对信息化系统中实时输入的地址信息进行动态匹配,步骤如下:实时获取用户输入的地址信息,将其作为关键信息;将所述关键信息输入训练好的映射模型,输出标准地名实体;判断该标准地名实体是否为行政层级中的第七级,若是,则通过图查询方式从所述地址知识图谱获取标准地址信息,然后提供给用户选择;若否,则通过图查询方式,从所述地址知识图谱中获取到上级行政区域的信息,对该标准地名实体的上级行政区域信息进行补全,再通过匹配模型与所述标准地址数据库的标准地址进行匹配,从匹配结果中取排名在前n2个标准地址输出,提供给用户选择或修改。
13、更优地,所述映射模型采用基于机器学习算法的transformer模型来实现,通过用注意力机制来获取地址信息文本中的依赖关系和上下文信息;在训练数据集中,待训练的地址数据包含地址的关键信息和从所述地址知识图谱中获取节点的地名实体,将节点的地名实体作为标签或真实值起监督学习的作用;在输入该模型之前,采用mlm遮盖预训练方式对输入的关键信息进行随机掩码处理,然后经过transformer模型的编码器得到对应的隐藏表示,将所述隐藏通过额外的全连接层进行映射,得到对每个可能的标准地名实体的得分;最后将得分输入softmax函数,将其转换为概率分布,即得到各标准地名实体的预测概率,输出预测概率最大值对应的标准地名实体;在训练的过程中,采用交叉熵损失函数来衡量模型输出的预测标准地址实体与所述地址知识图谱中节点的地址实体之间的差异,其计算方式如下:
14、,其中,代表样本数量,i是样本的编号,是第i个实际标签,是模型对第i个样本的预测概率。
15、更优地,所述匹配模型采用基于无监督的simcse模型来实现。
16、基于同一发明构思,本发明还提供一种地址信息的标准化治理及动态匹配的设备。
17、技术方案二
18、一种地址信息的标准化治理及动态匹配的设备,包括存储有可执行程序的存储器和处理器,所述处理器运行所述程序,执行如下步骤:自动构建出表示两地名实体关系的三元组数据(地名实体1,关系,地名实体2);使用cypher语法将各三元组数据中的地名实体和关系分别映射为知识图谱中的节点和边,生成地址知识图谱;根据标准地址的七级行政层级关系,从所述地址知识图谱中筛选出行政层级为第七级的地址实体,然后采用图查询的方式逐级向上查询上一级行政层级的地址实体,将七级地名实体补全后,得到标准地址,将所述标准化地址保存至标准地址数据库,完成原始地址信息的标准化治理。
19、本发明具有如下有益效果:
20、1、本发明在定义初始提示及相关示例实体对后,即可对原始地址信息进行全流程自动化治理,自动构建地址知识图谱并生成标准地名实体,导入标准化地址数据库。
21、2、本发明通过转述模型自动生成新提示,确保了关系的广泛表达,提高地址搜索的全面性。
22、3、本发明根据实体对与新提示的匹配性确定新提示的置信度权重,并将置信度权重应用于语言模型的搜索过程,将置信度权重应用于一致性判断中,提高了搜索结果的准确率和效率。
23、4、本发明实时采集地址的关键信息,基于地址知识图谱实现地址信息自动填补,同时结合匹配模型,自动生成推荐的标准地址信息,避免因不想填写,不会填写等原因造成标准数据信息不全或出现错误,在简化办理业务流程的同时提高用户办理业务效率。
- 还没有人留言评论。精彩留言会获得点赞!