基于过采样和改进SSA算法的不平衡数据分类方法及系统
本发明涉及数据分类,更具体的说是涉及基于过采样和改进ssa算法的不平衡数据分类方法及系统。
背景技术:
1、目前,在数据科学领域,分类是一项具有挑战性的任务,许多来自数据挖掘和机器学习领域的模型被提出以处理复杂的数据;大部分分类算法仅聚焦于数据分布较为平衡的数据集进行分类。
2、但是,现实生活中,数据集中不同类别的样本数量很难大致相同且误分类代价也不同,传统的机器学习算法在分类时通常以追求高准确率为目标而忽略少数类样本,分类模型的误分类概率会大大增加,因此,一昧地追求分类准确率的svm改进策略并不适用于不平衡数据。例如,信用卡非法交易与正常交易,信用卡非法交易在银行交易中仅占一小部分,但却会给社会带来极大的损失,利用现有机器学习模型很难在大数据中准确识别出信用卡非法交易。
3、对数据进行预处理成为处理不平衡数据的主要方法,通过采样的方式将不平衡数据转为平衡数据,过采样是一种通过将少数类数据增多以达到数据平衡的技术。smote算法以及borderline-smote算法,有效解决了过采样算法的盲目性采样问题。但是无法避免过采样后会发生的过拟合现象。
4、因此,如何有效扩充数据、减少过拟合问题并提升不平衡数据的分类效率,是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于过采样和改进ssa算法的不平衡数据分类方法及系统,有效扩充了数据、减少过拟合问题并提升了不平衡数据的分类效率。
2、为了实现上述目的,本发明采用如下技术方案:
3、基于过采样和改进ssa算法的不平衡数据分类方法,包括:
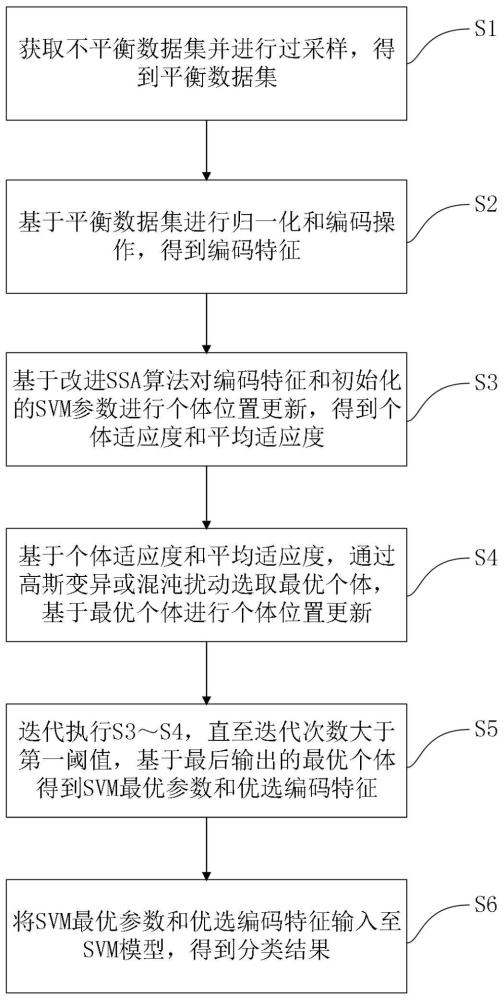
4、s1获取不平衡数据集并进行过采样,得到平衡数据集;
5、s2基于所述平衡数据集进行归一化和编码操作,得到编码特征;
6、s3基于改进ssa算法对所述编码特征和初始化的svm参数进行个体位置更新,得到个体适应度和平均适应度;
7、s4基于所述个体适应度和所述平均适应度,通过高斯变异或混沌扰动选取最优个体,基于最优个体进行所述个体位置更新;
8、s5迭代执行s3~s4,直至迭代次数大于第一阈值,基于最后输出的最优个体得到svm最优参数和优选编码特征;
9、s6将所述svm最优参数和所述优选编码特征输入至svm模型,得到分类结果。
10、优选的,得到平衡数据集的具体过程为:
11、将所述不平衡数据集划分为多数类样本和少数类样本;
12、基于所述少数类样本得到所述不平衡数据集中多个最近邻样本;
13、基于所述最近邻样本对所述少数类样本进行归类,得到安全样本、边界样本和噪声样本;
14、所述安全样本和所述边界样本组成待处理样本;
15、基于所述待处理样本进行过采样,得到所述平衡数据集。
16、优选的,基于所述最近邻样本对所述少数类样本进行归类,具体包括:
17、基于所述最近邻样本中多数类样本的占比对所述少数类样本进行归类:
18、若则该少数类样本归类为安全样本;
19、若则该少数类样本归类为边界样本;
20、若ml=m,则该少数类样本归类为噪声样本;
21、其中,m表示最近邻样本数量,ml表示最近邻样本中多数类样本的数量,0≤ml≤m。
22、优选的,对所述待处理样本进行过采样前,还包括:
23、基于边界控制因子控制所述待处理样本的生成范围;
24、所述边界控制因子sr为:
25、
26、其中,sc max表示待处理样本中每项特征的最大值集合,lmin表示多数样本中每项特征的最小值集合。
27、优选的,过采样具体过程为:
28、基于所述待处理样本得到k个最近邻同类样本和k个最近邻反类样本;
29、基于所述最近邻同类样本和所述最近邻反类样本得到最小向量值vmin;
30、基于所述最小向量值vmin和sc max得到数组var;
31、基于所述数组和所述最小向量值对所述待处理样本进行过采样;
32、过采样公式为:
33、
34、优选的,得到个体适应度和平均适应度,具体过程包括:
35、将所述编码特征和所述初始化的svm参数作为种群个体并得到初始计算适应度,记为第一适应度;
36、基于所述第一适应度选择多个个体并基于所述个体得到第二适应度及第一位置;
37、基于所述第二适应度和所述第一位置得到生产者数量和跟随者数量;
38、基于所述生产者数量和所述跟随者数量得到第三适应度和第二位置;
39、基于所述第三适应度和所述第二位置进行个体位置更新,得到更新生产者位置、更新跟随者位置和更新预警者位置;
40、基于所述更新生产者位置、所述更新跟随者位置和所述更新预警者位置得到所述个体适应度和所述平均适应度。
41、优选的,选取最优个体,具体包括:
42、基于所述个体适应度fi和所述平均适应度favg进行比较;
43、若fi≤favg,则通过所述高斯变异选取最优个体;
44、若fi>favg,则通过所述混沌扰动选取最优个体。
45、优选的,所述混沌扰动具体过程为:
46、基于公式并通过迭代得到混沌变量td;
47、将所述混沌变量td带入求解问题的解空间,得到第d维产生的混动扰动量newxd:
48、newxd=mind+(maxd-mind)·td;
49、基于newxd得到第d维混沌扰动的个体newxd':
50、
51、其中,ti+1表示经过混动扰动后的个体,mod1表示任意实数的小数部分,表示随机变量,rand(0,1)表示(0,1)之间的随机数,n表示序列中的粒子数,x'表示需要扰动的个体。
52、优选的,s6后还包括s7:
53、s7循环迭代执行s3~s6,直至迭代次数大于第二阈值,得到多个迭代输出分类结果,基于所述迭代输出分类结果得到最优分类结果。
54、基于过采样和改进ssa算法的不平衡数据分类系统,包括:数据采集处理模块、数据编码模块、适应度获取模块、最优个体获取模块、最优参数获取模块和结果获取模块;
55、所述数据采集处理模块,用于获取不平衡数据集并进行过采样,得到平衡数据集;
56、所述数据编码模块,用于基于所述平衡数据集进行归一化和编码操作,得到编码特征;
57、所述适应度获取模块,用于基于改进ssa算法对所述编码特征和初始化的svm参数进行个体位置更新,得到个体适应度和平均适应度;
58、所述最优个体获取模块,用于基于所述个体适应度和所述平均适应度,通过高斯变异或混沌扰动选取最优个体,基于最优个体进行所述个体位置更新;
59、所述最优参数获取模块,用于迭代经历所述适应度获取模块和所述最优个体获取模块,直至迭代次数大于第一阈值,基于最后输出的最优个体得到svm最优参数和优选编码特征;
60、所述结果获取模块,用于将所述svm最优参数和所述优选编码特征输入至svm模型,得到分类结果。
61、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于过采样和改进ssa算法的不平衡数据分类方法及系统,具有以下有益效果:
62、1、采用范围可控过采样算法对不平衡数据集进行少数类样本的精准合成,生成有效的优质人工样本。
63、2、用范围可控的过采样算法,通过对边界样本和安全样本计算最小向量值来控制人工样本生成的范围,并优先对边界样本进行过采样操作。
64、3、对麻雀搜索算法进行改进,利用猫映射对其进行种群初始化并改进个体更新方式,然后引入高斯变异和混沌扰动使得优化算法不易陷入局部最优。
65、4、将数据特征二进制化后,结合gssa-svm在训练迭代中寻找svm的最优参数以及最佳特征组合,从而提升分类性能。
66、5、使用gssa对svm中的参数以及二进制化后的特征进行迭代优化,克服了由过采样算法引起的过拟合现象。
- 还没有人留言评论。精彩留言会获得点赞!