一种多模态短视频的情感可视化分析方法及系统
本发明涉及人工智能,尤其是涉及一种多模态短视频的情感可视化分析方法及系统。
背景技术:
1、现代多模态视频情感识别的现代技术主要是通过文本、语音、面部表情、手势、姿势等帮助理解人们在视频中传达出来的情绪。总体上看,多模态视频情感识主要是通过获取和分析声音、视觉和文本三个方面的特征,从而训练获得情感识别的能力。在现有的基于多模态的视频情感识别工作中,声学模态特征通常由opensmile工具包或基于rnn的深度学习网络提取。随着深度学习的发展,如今的视觉模态特征提取主要依赖于深度学习网络。对于文本模块,常利用nlp技术,比如transformer和bert来实现。
2、以2022年wei等人提出的fv2es系统为例。将视频数据输入给fv2es模型,首先得到输入视频的完整对话文本和音频梅尔谱图。同时,对图像帧进行预处理,将整个视频分成几个短视频片段。接着,使用时间表对齐三种模式的数据。选择同一时期的文本、光谱和图像帧,并将它们直接作为v2em的输入。在该模型中,针对输入采用分层注意力的方法对输入中音频模态的每个频谱块进行特征提取,通过声谱分割、块内自注意力和块聚合处理,提取分层的谱特征,以获得音频谱的内部关系信息,并增强音频模态的效果。同时,采用基于repvgg的多分支特征学习和单分支推理结构,提取帧的视觉模态信息。对于文本模态,采用预训练的开源的albert模型来提取文本特征。同时使用基本的transformer来获得视觉和听觉的顺序信息。最后,通过加权的前馈网络执行多模式融合,输出最后的各类情感预测概率,选择概率最大者作为最终的情感预测。最后,将多个短视频的情感预测值作为输入视频的情感预测结果。
3、但是,现有技术中仍存在以下不足:
4、一是,经过调研与分析,在近三年以来的所有情感分析模型中,文本模态对结果的影响最大。但是v2em所使用的albert模型在文本模态上针对情感分析任务的特征提取效果不够优秀,导致对结果影响最大的文本模态的分析不够完善。此外,还有其他的方案尝试采用大语言模型对文本模态进行分析,虽然大语言模型有更多的参数以及更大的规模,但是会导致推理时间变长和推理开销增大,且经过我们的实验,大语言模型在类似系统中的文本模态的情绪预测方面表现不如经过训练的小语言模型好。
5、二是,在v2em模型中,视频模态的输入是图像帧,然而完整的图像帧中会出现其他与情绪分析无关的内容,且短视频既有横屏又有竖屏,图像帧的分辨率也有所差异,这些因素会影响到视频模态的情感预测。
6、三是,现有的数据集大多数只对每个视频的按语段进行切分的片段进行了情感标注,缺乏对视频整体的情感的标注,且通常采用人工的方式对视频进行分段和转录。
技术实现思路
1、本发明的目的是提供一种多模态短视频的情感可视化分析方法及系统,可以解决上述背景技术中存在的问题。
2、为实现上述目的,本发明提供了一种多模态短视频的情感可视化分析方法,包括以下步骤:
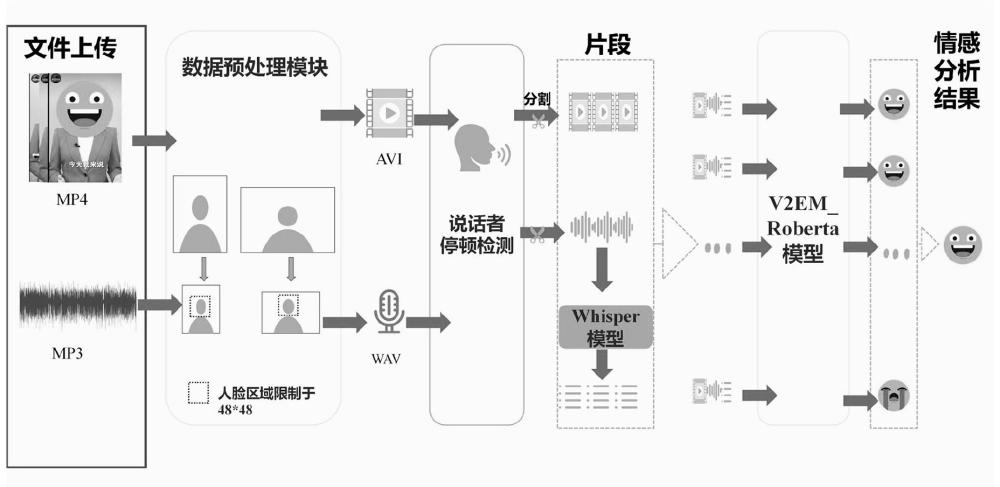
3、s1、将多模态短视频数据集输入数据格式预处理模块进行预处理,实现不同分辨率视频的自适应压缩,得到视频模态和音频模态的数据;
4、s2、将得到的视频模态和音频模态的数据输入无声检测模块,通过检测音频的说话人的停顿点,将视频和音频切分为若干片段;
5、s3、将每个片段的音频数据输入到whisper模型,转录得到文本模态的数据;
6、s4、利用步骤s2检测的停顿点,对齐视频模态、音频模态和文本模态的数据,将同一时期的三种模态数据输入到v2em-roberta模型中,得到每个片段的情感预测结果;
7、s5、将各个片段的情感预测结果进行决策层线性融合,得到多模态短视频整体的情感预测结果。
8、优选的,步骤s1中,数据格式预处理模块将不同分辨率的多模态短视频进行压缩,并使用ffmpeg工具将mp3、mp4格式的音频转化为avi、wav格式,得到视频模态数据和音频模态数据。
9、优选的,步骤s4中,v2em-roberta模型中,对于视频模态数据,使用mtcnn facerecognition模型截取视频帧中的人脸图片,针对人脸图片使用repvgg网络提取视觉特性,使用transformer模型对视觉特征进行包含时序信息的编码,最后通过ffn层得到视频模态的预测结果;
10、对于声学模态数据,提取原始音频的对数频率特征,将其展开为二维频率特征图,之后将二维频率特征图划分为16个子图序列,并输入到nest结构中提取声学特征,然后将声学特征输入到transformer模型中进行包含时序信息的编码,最后通过ffn层得到音频模态的预测结果;
11、对于文本的模态数据,使用开源的预训练语言模型roberta提取文本特征,然后使用transformer模型对文本特征进行包含时序信息的编码,最后通过ffn层得到文本模态的预测结果;
12、最后,将视频模态、音频模态和文本模态的预测结果使用线性融合的方式得到最终的情感预测结果。
13、优选的,步骤s1中,多模态短视频数据集的构建方法包括以下步骤:
14、(1)设计自动分割和转录的方法;
15、(2)数据集清洗和标注整体情感。
16、优选的,步骤(1)中,设计自动分割和转录的方法,包括以下步骤:
17、1.1、根据讲话者的说话节奏,将短视频的音频部分进行自动分割,得到音频片段,获取每个音频片段中每句话的开始时间和结束时间;
18、1.2、将音频片段输入到whisper模型,将中文语音和英文语音均转录成英文文本;
19、1.3、对于每一个音频片段生成的每个句子的字幕文本和分割时间戳输出到csv文件中。
20、优选的,步骤1.1中,自动分割的实现是通过pydub库中的detect-silence函数检测讲话者讲话时的沉默间隔,将音频自动分割后可以有效提高语音转录文本的质量;
21、将原始音频分割成与每个句子相对应的短段的阈值为0.8s。
22、优选的,步骤(2)中,数据集清洗和标注整体情感,包括以下步骤:
23、2.1、从网站上爬取与事件相关的短视频;
24、2.2、设计短视频标准并人工选择短视频,得到初始数据集;
25、2.3、通过评委来为初始数据集中的短视频整体标注情感,筛选短视频后,得到最终数据集即为多模态短视频数据集,并对标注结果进行一致性验证。
26、为了验证数据集的标注结果的一致性,计算数据集的3位注释者的标签的fleiss’kappa,得到k>0.60时,证明标注具有相当程度的一致性。
27、为了验证标注的质量,还选取了数据集中出现不同确切情感的标注的短视频,并邀请了一位新的标注者再次对这些短视频进行标注,计算cohen’s kappa来衡量与原注释的一致性,得到k>0.80时,表明非常好的一致性。
28、优选的,步骤2.2中,短视频标准如下:
29、视频画面中仅有一至二位主要人物、主要人物全讲中文或英文、视频时长短于3分钟和有明显的情感倾向;
30、同时,为了保证数据集的客观性,过滤政策类的相关短视频。
31、本发明还提供了一种用于实现如上述的一种多模态短视频的情感可视化分析方法的系统,包括数据格式预处理模块、无声检测模块、whisper模型、数据对齐模块、v2em-roberta模型、融合模块和可视化模块。
32、因此,本发明采用上述一种多模态短视频的情感可视化分析方法及系统,其技术效果如下:
33、(1)本发明设计的数据格式预处理模块通过将视频中的人脸部分通过mtcnn facerecognition模型截取并统一到同一分辨率下,实现了对后续情绪识别模块的输入数据的统一,解决了短视频横竖屏差异和图像帧的分辨率不同,对文本模态情感预测产生影响的问题。
34、(2)本发明构建了v2em-roberta模型,并通过使用预训练的小语言模型roberta,提高了现有模型的文本模态的情感分析性能和准确性,并通过实验验证大语言模型在类似任务上的性能不如小语言模型。
35、(3)本发明使用detect-silence函数将短视频按照讲话者的说话间隔自动进行划分,标注每句话的开始时间与结束时间,通过whisper模型将音频转化为全部是英文的文本进行标注并设计严谨的方案进行整体情绪的人工标注。
36、(4)本发明提出了多语言自动分割和转录的方法,提高了构建多模态数据集的效率,结合严谨的人工整体情感标注,构建了一套对短视频整体的情感进行标注的数据集bili_news。
37、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!