基于局部-全局面部关键点关系的疲劳驾驶姿态识别方法
本发明涉及信息,尤其涉及一种基于局部-全局面部关键点关系的疲劳驾驶姿态识别方法。
背景技术:
1、随着机动车数量增长,道路交通事故成为严重社会问题。20%的道路事故由疲劳驾驶导致,严重事故中占比达40%。因此,研究驾驶员疲劳检测方法具有重大社会价值。这不仅能提高道路安全,降低事故发生率,还能推动科技创新和社会进步。实时监测和预警驾驶员疲劳状态,能有效预防疲劳驾驶,保障人民生命财产安全。
2、中国专利申请公布号cn114937260a《基于传统方法与深度神经网络相结合的疲劳驾驶检测方法》提出了一种基于传统方法与深度神经网络相结合的疲劳驾驶检测方法,首先利用hog人脸定位算法对驾驶者图像进行人脸定位,将人脸定位框图像输入到深度神经网络yolov5模型中,判断hog人脸定位框中眼部睁闭状态,以及嘴部张闭状态,再基于眼部睁闭状态和嘴部张闭状态判断驾驶者是否处于疲劳状态。中国专利申请公布号cn117533341a《一种基于人脸识别的疲劳驾驶监控方法》提出了一种基于人脸识别的疲劳驾驶监控方法,根据识别后的面部状态判断驾驶员是否为疲劳驾驶,若驾驶员为疲劳驾驶,则控制报警器报警和或控制方向盘震动。
3、在驾驶员疲劳行为的检测领域,人们已经提出了许多方法来应对这一问题。然而,大部分方法在处理过程中未能充分考虑驾驶员疲劳行为检测的关键因素,即驾驶员的眼睛、嘴巴和下巴的位置关系。这些方法在一定程度上影响了驾驶员疲劳行为的准确检测。事实上,驾驶场景中的不同视角关键点之间的空间关系对驾驶员疲劳行为的检测具有重要影响。例如,在不同视角下,驾驶员的眼睛、嘴巴和下巴的位置关系可能发生变化,这些变化可能会导致疲劳程度的差异。然而,目前大部分方法通常只使用单一视角进行处理和判断,忽视了不同视角下关键点之间的空间关系。
技术实现思路
1、本发明目的就是为了弥补已有技术的缺陷,通过探讨局部与全局面部关键点之间的关系,提供一种基于局部-全局面部关键点关系的疲劳驾驶姿态识别方法,本发明通过收集驾驶员的驾驶姿态数据集,运用关键点间局部与全局的空间关系,结合transformer模型检测关键点热图,从而提高检测的准确性,具有实际应用价值。
2、本发明是通过以下技术方案实现的:
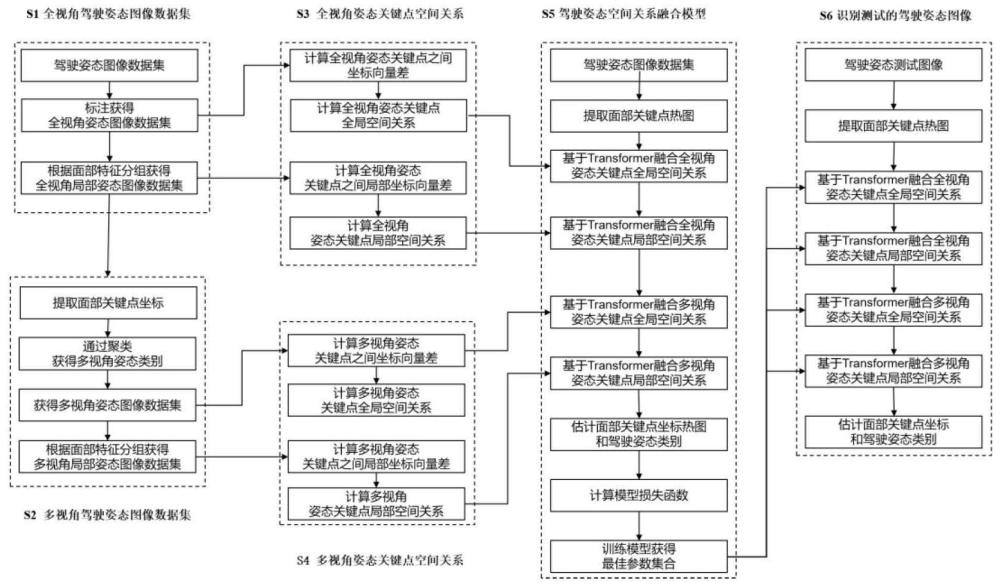
3、一种基于局部-全局面部关键点关系的疲劳驾驶姿态识别方法,具体包括如下步骤:
4、s1:构建全局和局部全视角驾驶姿态图像数据集;
5、s2:构建全局和局部多视角驾驶姿态图像数据集;
6、s3:提取全视角姿态关键点的局部和全局空间关系;
7、s4:提取多视角姿态关键点的局部和全局空间关系;
8、s5:构建基于transformer的驾驶姿态空间关系融合模型;
9、s6:识别测试的驾驶姿态图像。
10、步骤s1所述的构建全局和局部全视角驾驶姿态图像数据集,具体如下:
11、s1-1:在驾驶的过程中,使用位于驾驶员右前方的红外摄像头,获取驾驶员头部图像数据集其中,表示图像,表示图像标签,裁剪获得的驾驶员头部图像集,将其尺寸调整为64×48;
12、s1-2:标注图像集姿态标签,构建全视角姿态图像数据集其中,代表输入全视角姿态图像,为全视角姿态图像集标签,姿态类别1表示正常,姿态类别2表示眨眼,姿态类别3表示打哈欠,姿态类别4表示瞌睡点头;
13、s1-3:根据面部特征,分组获得全视角局部姿态图像数据集;
14、s1-3-1:根据面部特征分组面部关键点,局部关键点特征分组l={1,2,3,4},其中,分组1表示左眼,分组2表示右眼,3表示嘴巴,分组4表示脸部轮廓;
15、s1-3-2:将全视角姿态图像数据集,根据面部特征,分组获得全视角局部姿态图像数据集其中,代表全视角局部姿态图像,为聚类后的全视角局部姿态图像数据集标签,根据步骤s1-2获得的全视角姿态图像集标签数量,标签类别数量为数量乘上分组l的数量。
16、步骤s2所述的构建全局和局部多视角驾驶姿态图像数据集,具体如下:
17、s2-1:根据步骤s1-2标准获得的全视角姿态图像数据集datag,获得头部关键点坐标i表示面部第i个关键点,n表示关键点个数,为第i个关键点在x轴上的真实值坐标,为第i个关键点在y轴上的真实值坐标;
18、s2-2:利用头部关键点坐标,通过聚类获得全局多视角姿态类别m={1,2,3},视角类别1表示左侧视角,视角类别2表示正面视角,视角类别3表示右侧视角,获得多视角驾驶姿态图像数据集其中,为分组后的多视角全局姿态图像,为分组后的多视角全局姿态图像集标签,根据步骤s1-2获得的全视角姿态图像集数量,标签类别数量为数量乘上多视角m的数量;
19、s2-3:根据步骤s2-2获得的多视角驾驶姿态图像数据集datam,g,通过聚类,获得多视角局部姿态图像数据集其中,为分组后的多视角局部姿态图像,为分组后的多视角局部姿态图像集标签,标签类别数量为数量乘上多视角m的数量。
20、步骤s3所述的提取全视角姿态关键点局部和全局空间关系,具体如下:
21、s3-1:计算全视角姿态关键点之间坐标向量差;
22、s3-1-1:首先计算全视角姿态关键点之间向量
23、
24、其中,i是第i个关键点,j是第j个关键点,i→j表示第i个关键点指向第j个关键点;
25、s3-1-2:计算全视角姿态关键点之间坐标向量差
26、
27、其中,(x,y)表示关键点坐标;
28、s3-2:计算全视角姿态关键点全局空间关系特征
29、
30、其中,conv表示卷积神经网络,norm表示归一化;
31、s3-3:计算全视角姿态关键点之间局部坐标向量差;
32、s3-3-1:计算全视角姿态关键点之间局部坐标向量
33、
34、其中,i表示第i个关键点,j表示第j个关键点,i→j表示第i个关键点指向第j个关键点;
35、s3-3-2:计算全视角姿态关键点之间局部坐标向量差
36、
37、s3-4:计算全视角姿态关键点局部空间关系
38、
39、其中,conv表示卷积神经网络,norm表示归一化。
40、步骤s4所述的提取多视角姿态关键点局部和空间关键点空间关系,具体如下:
41、s4-1:计算多视角姿态关键点之间坐标向量差:
42、s4-1-1:计算多视角姿态关键点之间坐标向量
43、
44、其中,i表示第i个关键点,j表示第j个关键点,i→j表示第i个关键点指向第j个关键点;
45、s4-1-2:计算多视角姿态图像数据集样本关键点坐标向量
46、
47、s4-2:计算多视角姿态关键点全局空间关系
48、
49、其中,conv表示卷积神经网络,norm表示归一化;
50、s4-3:计算多视角姿态关键点之间局部坐标向量差:
51、s4-3-1:计算多视角姿态关键点之间局部坐标向量
52、
53、其中,i表示第i个关键点,j表示第j个关键点,i→j表示第i个关键点指向第j个关键点;
54、s4-3-2:计算多视角姿态关键点之间坐标向量差
55、
56、s4-4:计算多视角姿态关键点局部空间关系
57、
58、其中,conv表示卷积神经网络,norm表示归一化。
59、步骤s5所述的构建基于transformer的驾驶姿态空间关系融合模型,具体如下:
60、s5-1:,利用卷积神经网络hrnet模型提取关键点特征:
61、
62、其中,表示驾驶姿态图像;
63、s5-2:基于transformer融合全视角姿态关键点全局空间关系;
64、s5-2-1:获取transformer中的q,k,v张量:
65、
66、其中,wq,wk,wv表示学习参数;
67、s5-2-2:利用spatialconv(input,kernel)空间卷积操作,其中,input表示输入对象,kernel表示卷积核,使用空间关系作为卷积核,卷积核在input上滑动,测量并提取与卷积核所代表的空间关系相似性,卷积核的每个元素与input对应位置的元素相乘,生成一个新的特征,该特征图强调了与卷积核相似的空间关系;根据步骤s3-2获得的全视角姿态关键点的全局空间关系rg,计算与k,v融合,得到的新张量k′,v′:
68、k′=spatialconv(k,rg),v′=spatialconv(v,rg),
69、其中,spatialconv表示空间卷积操作;
70、s5-2-3:计算融合全视角姿态关键点全局空间关系的关键点特征:
71、fg=transformer(q,k′,v′);
72、s5-3:基于transformer融合全视角姿态关键点局部空间关系;
73、s5-3-1:获取第二个transformer中的ql,kl,vl张量;
74、
75、其中,表示可学习参数;
76、s5-3-2:根据步骤s3-3获得的全视角姿态关键点的局部空间关系rl,计算与k,v融合后新的张量kl′,vl′:
77、kl′=spatialconv(kl,rl),vl′=spatialconv(vl,rl)
78、s5-3-3:计算融合全视角姿态关键点局部空间关系的关键点特征:
79、fl=transformer(ql,kl′,vl′);
80、s5-4:基于transformer融合多视角姿态关键点全局空间关系;
81、s5-4-1:获取第三个transformer中的qm,g,km,g,vm,g张量;
82、
83、其中,表示可学习参数;
84、s5-4-2:根据步骤s3-3多视角姿态关键点的全局空间关系rm,g,计算与km,g,vm,g融合后新的张量km,g′,vm,g′:
85、km,g′=spatialconv(km,g,rm,g),vm,g′=spatialconv(vm,g,rm,g);
86、s5-4-3:计算融合全视角姿态关键点局部空间关系的关键点特征:
87、fm,g=transformer(qm,g,km,g′,vm,g′),
88、s5-5:基于transformer融合多视角姿态关键点局部空间关系;
89、s5-5-1:获取第四个transformer中的qm,g,km,g,vm,g张量;
90、
91、其中,为可学习参数;
92、s5-5-2:获得的多视角姿态关键点的局部空间关系rm,l,计算与km,l,vm,l融合后新的张量km,l′,vm,l′:
93、km,l′=spatialconv(km,l,rm,l),vm,l′=spatialconv(vm,l,rm,l);
94、s5-5-3:计算融合全视角姿态关键点局部空间关系的关键点特征:
95、fm,l=transformer(qm,g,km,l′,vm,l′),
96、s5-6:预测面部关键点热图和驾驶姿态类别;
97、s5-6-1:预测关键点热图
98、
99、其中,fc表示全连接层,i表示第i个关键点;
100、s5-6-2:预测驾驶姿态类别label:
101、s5-6-2-1:预测驾驶姿态类别分数score,
102、score=softmax(fm,l),
103、其中,softmax表示分类函数;
104、s5-6-2-2:然后选择score分数最高的类别作为驾驶姿态类别label预测结果;
105、s5-7:计算模型总损失函数;
106、s5-7-1:计算关键点坐标热图损失函数:
107、s5-7-1-1:根据步骤s2-1获得的关键点i的真实值坐标利用高斯热图像素计算方法,计算关键点i的真实值热图
108、
109、其中,σ2表示高斯方差,(xi,yi)表示关键点i热图上某一点的坐标;
110、s5-7-1-2:根据步骤s5-6-1获得的关键点坐标热图计算关键点坐标损失函数
111、
112、其中,n表示关键点个数;
113、s5-7-2:根据步骤s5-6-2-1获得的驾驶姿态类别分数score,计算驾驶姿态类别损失函数:
114、
115、其中,表示驾驶姿态真实标签one-hot编码,4表示类别的数量;
116、s5-7-3:根据步骤s5-7-1-2获得的关键点坐标损失函数和步骤s5-7-2驾驶姿态类别损失函数,计算模型的总损失函数:
117、
118、s5-8:使用步骤s5-7-3计算获得的总损失函数作为梯度,使用反向传播算法,依次对模型的参数求解,在反向传播过程中,求解步骤s5-3、s5-4、s5-5、s5-6中四层transformer层的参数;当训练结束后,获得模型的最佳参数集合。
119、步骤s6所述的识别测试的驾驶姿态图像,具体如下:
120、s6-1:输入驾驶姿态测试图像;
121、s6-2:提取面部关键点热图;
122、s6-3:提取步骤s5-3中基于transformer融合全视角姿态关键点全局空间关系融合模型的最佳参数集合;
123、s6-4:提取步骤s5-4中基于transformer融合全视角姿态关键点局部空间关系融合模型的最佳参数集合;
124、s6-5:提取步骤s5-5中基于transformer融合多视角姿态关键点全局空间关系融合模型的最佳参数集合;
125、s6-6:提取步骤s5-6基于transformer融合多视角姿态关键点局部空间关系融合模型的最佳参数集合;
126、s6-7:识别测试的驾驶姿态;
127、s6-8:对步骤s6-7识别的驾驶姿态类别进行判断,如果类别不是正常则发出警报。
128、本发明的优点是:本发明将面部关键点分成左眼睛、右眼睛、嘴巴、下巴局部分组,学习基于位置的局部关键点关系,进一步将面部姿态划分为多个视角,学习多视角的全局关键点关系,多视角的局部关键点关系。本发明构建多视角局部-全局transformer,通过使用上述的面部关键点关系,用于识别疲劳驾驶姿态;本发明通过收集驾驶员的驾驶姿态数据集,运用关键点间局部与全局的空间关系,结合transformer模型检测关键点热图,从而提高检测的准确性,能够避免局部疲劳状态和局部正常状态的错误判断,具有实际应用价值。
- 还没有人留言评论。精彩留言会获得点赞!