工单分类方法、装置及存储介质与流程
本技术涉及通信,尤其涉及一种工单分类方法、装置及存储介质。
背景技术:
1、近年来,随着各平台和各领域服务热线的开通,以及服务热线服务能力的不断提升,各平台和各领域用户对热线服务的使用量大幅增长,热线工单受理也面临前所未有的挑战。现有的工单分类主要依赖人工标注,效率低下且成本高昂;而机器学习虽有所应用,但面对工单数量与类型的激增,其分类效率逐渐下降。因此,如何提高工单分类的效率成为亟待解决的技术问题。
技术实现思路
1、本技术提供一种工单分类方法、装置及存储介质,能够进行工单分类。
2、为达到上述目的,本技术采用如下技术方案:
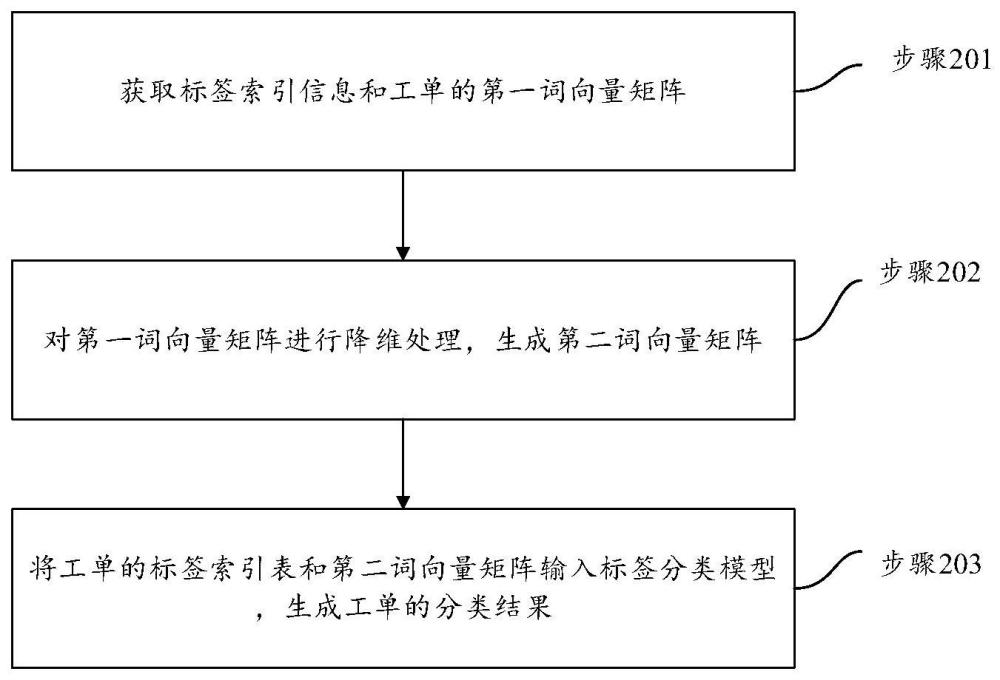
3、第一方面,本技术提供了一种工单分类方法,方法包括:获取标签索引信息和工单的第一词向量矩阵;标签索引信息用于指示工单标签与索引值之间的映射关系;第一词向量矩阵是基于工单的工单类型和工单的工单内容转化成的词向量矩阵;对第一词向量矩阵进行降维处理,生成第二词向量矩阵;将工单的标签索引表和第二词向量矩阵输入标签分类模型,生成工单的分类结果;工单的分类结果包括工单对应的至少一个工单标签,以及每个工单标签对应的概率值。
4、结合上述第一方面,在一种可能的实现方式中,对第一词向量矩阵进行降维处理,生成第二词向量矩阵,包括:对第一词向量矩阵进行去中心化处理,得到第一词向量矩阵对应的协方差矩阵;对协方差矩阵进行分解,得到协方差矩阵对应的特征值和特征向量;基于特征值对特征向量进行排序,生成第二词向量矩阵。
5、结合上述第一方面,在一种可能的实现方式中,输入层、卷积层、金字塔池化层、全连接层;卷积层包括多个子卷积层;每个子卷积层对应的卷积核不同;金字塔池化层包括多个子金字塔池化层;每个金字塔池化层对应的池化窗口的大小不同;相邻的两个子金字塔池化层之间具有残差连接;将工单的标签索引表和第二词向量矩阵输入标签分类模型,生成工单的分类结果,包括:基于输入层,将第二词向量矩阵输入标签分类模型;基于卷积层的多个子卷积层,提取第二词向量矩阵的多个局部特征;基于多个子金字塔池化层对第二词向量矩阵的多个局部特征进行池化操作,生成多个金字塔池化特征值;基于全连接层和归一化函数对多个金字塔池化特征值进处理,生成工单的分类结果。
6、结合上述第一方面,在一种可能的实现方式中,获取工单的标签索引表,包括:获取历史工单数据;历史工单数据包括:工单标签、工单类型、工单内容;对历史工单数据进行文本清洗,生成目标工单数据;目标工单数据包括:目标工单标签、目标工单类型、目标工单内容;基于数据编码算法对目标工单标签进行数值化处理,生成工单的标签索引信息;基于预训练词向量模型对目标工单类型和目标工单内容进行特征提取,生成工单的第一词向量矩阵。
7、结合上述第一方面,在一种可能的实现方式中,基于预训练词向量模型对工单类型和工单内容进行特征提取,生成工单的第一词向量矩阵,包括:基于预训练词向量模型对工单内容进行分词处理,生成多个工单词组;确定多个工单词组中每个工单词组的词频;基于工单词组的词频,确定工单内容对应的词索引列表;词索引列表用于映射工单词组对应的词向量;基于词索引列表和工单类型,生成工单的第一词向量矩阵。
8、结合上述第一方面,在一种可能的实现方式中,基于数据编码算法对工单标签进行数值化处理,生成工单的标签索引信息,包括:基于去重算法对目标工单数据的工单标签进行处理,生成目标工单标签;基于目标工单标签,生成工单的标签索引信息。
9、结合上述第一方面,在一种可能的实现方式中,方法还包括:获取工单对应的至少一个工单标签,以及每个工单标签对应的概率值;确定概率值满足预设阈值的工单标签为工单的目标工单标签。
10、第二方面,本技术提供了一种工单分类装置,装置包括:处理单元;处理单元,用于获取标签索引信息和工单的第一词向量矩阵;标签索引信息用于指示工单标签与索引值之间的映射关系;第一词向量矩阵是基于工单的工单类型和工单的工单内容转化成的词向量矩阵;处理单元,还用于对第一词向量矩阵进行降维处理,生成第二词向量矩阵;处理单元,还用于将工单的标签索引表和第二词向量矩阵输入标签分类模型,生成工单的分类结果;工单的分类结果包括工单对应的至少一个工单标签,以及每个工单标签对应的概率值。
11、结合上述第二方面,在一种可能的实现方式中,处理单元,具体用于:对第一词向量矩阵进行去中心化处理,得到第一词向量矩阵对应的协方差矩阵;对协方差矩阵进行分解,得到协方差矩阵对应的特征值和特征向量;基于特征值对特征向量进行排序,生成第二词向量矩阵。
12、结合上述第二方面,在一种可能的实现方式中,目标分类模型包括:输入层、卷积层、金字塔池化层、全连接层;卷积层包括多个子卷积层;每个子卷积层对应的卷积核不同;金字塔池化层包括多个子金字塔池化层;每个金字塔池化层对应的池化窗口的大小不同;相邻的两个子金字塔池化层之间具有残差连接;处理单元,还具体用于:基于输入层,将第二词向量矩阵输入标签分类模型;基于卷积层的多个子卷积层,提取第二词向量矩阵的多个局部特征;基于多个子金字塔池化层对第二词向量矩阵的多个局部特征进行池化操作,生成多个金字塔池化特征值;基于全连接层和归一化函数对多个金字塔池化特征值进处理,生成工单的分类结果。
13、结合上述第二方面,在一种可能的实现方式中,处理单元,还具体用于:获取历史工单数据;历史工单数据包括:工单标签、工单类型、工单内容;对历史工单数据进行文本清洗,生成目标工单数据;目标工单数据包括:目标工单标签、目标工单类型、目标工单内容;基于数据编码算法对目标工单标签进行数值化处理,生成工单的标签索引信息;基于预训练词向量模型对目标工单类型和目标工单内容进行特征提取,生成工单的第一词向量矩阵。
14、结合上述第二方面,在一种可能的实现方式中,处理单元,还具体用于:基于预训练词向量模型对工单内容进行分词处理,生成多个工单词组;确定多个工单词组中每个工单词组的词频;基于工单词组的词频,确定工单内容对应的词索引列表;词索引列表用于映射工单词组对应的词向量;基于词索引列表和工单类型,生成工单的第一词向量矩阵。
15、结合上述第二方面,在一种可能的实现方式中,处理单元,还具体用于:基于去重算法对目标工单数据的工单标签进行处理,生成目标工单标签;基于目标工单标签,生成工单的标签索引信息。
16、结合上述第二方面,在一种可能的实现方式中,处理单元,还用于:获取工单对应的至少一个工单标签,以及每个工单标签对应的概率值;确定概率值满足预设阈值的工单标签为工单的目标工单标签。
17、第三方面,本技术提供了一种工单分类装置,该工单分类装置包括:处理器以及存储器;其中,存储器用于存储计算机执行指令,当工单分类装置运行时,处理器执行存储器存储的计算机执行指令,以使工单分类装置执行如第一方面和第一方面的任一种可能的实现方式中描述的工单分类方法。
18、第四方面,本技术提供了一种计算机可读存储介质,计算机可读存储介质中存储有指令,当计算机可读存储介质中的指令由工单分类装置的处理器执行时,使得工单分类装置能够执行如第一方面和第一方面的任一种可能的实现方式中描述的工单分类方法。
19、第五方面,本技术提供了一种包含指令的计算机程序产品,当计算机程序产品在工单分类装置上运行时,使得工单分类装置执行如第一方面和第一方面的任一种可能的实现方式中所描述的工单分类方法。
20、第六方面,本技术提供了一种芯片,芯片包括处理器和通信接口,通信接口和处理器耦合,处理器用于运行计算机程序或指令,以实现如第一方面和第一方面的任一种可能的实现方式中所描述的工单分类方法。
21、具体的,本技术实施例中提供的芯片还包括存储器,用于存储计算机程序或指令。
22、在本技术中,上述工单分类装置的名字对设备或功能模块本身不构成限定,在实际实现中,这些设备或功能模块可以以其他名称出现。只要各个设备或功能模块的功能和本技术类似,属于本技术权利要求及其等同技术的范围之内。
23、本技术的这些方面或其他方面在以下的描述中会更加简明易懂。
24、本技术提供的技术方案至少带来以下有益效果:工单分类装置获取标签索引信息和工单的第一词向量矩阵。其中,标签索引信息用于指示工单标签与索引值之间的映射关系;第一词向量矩阵是基于工单的工单类型和工单的工单内容转化成的词向量矩阵。工单分类装置对第一词向量矩阵进行降维处理生成第二词向量矩阵。进一步的,工单分类装置将工单的标签索引表和第二词向量矩阵输入标签分类模型,生成工单的分类结果。其中,工单分类结果包括每个工单对应的至少一个工单标签,以及每个工单标签对应的概率值。这样,通过引入标签索引信息和词向量矩阵,该方法能够更准确地捕捉工单内容的语义信息。同时,对词向量矩阵进行降维处理,可以减少计算复杂度,提高分类的效率。进一步的,本技术通过标签分类模型进行自动化分类,可以减少人工处理的工作量,进一步提升分类效率。
- 还没有人留言评论。精彩留言会获得点赞!