基于多源遥感数据的陆地生态系统碳密度估算方法
本发明属于陆地生态系统碳密度估算,具体涉及基于多源遥感数据的陆地生态系统碳密度估算方法。
背景技术:
1、陆地生态系统是地球碳库的基本组成部分,它们对全球碳平衡具有重大影响。在“双碳目标”背景下,生态系统碳固存是碳减排重要途径之一,而碳密度数据则是计算碳储量关键数据。在此背景下,对陆地生态系统碳密度进行精准估算显得尤为重要。
2、传统的碳密度监测方法通常使用野外现场采样数据或森林清查数据作为基础数据。使用森林清查数据作为植被生物量估算的基础数据容易高估植被碳含量,因为实地测量通常超过特定地区或国家的平均水平,增加了碳密度估算的不确定性。以往关于中国陆地生态系统碳密度的研究中,大部分研究仅关注某一种碳库或某一种生态系统,缺少对不同碳库(如地上植被生物量碳密度、地下植被生物量碳密度、0-20cm土壤有机碳密度和0-100cm土壤有机碳密度)的全面准确估算。由于数据来源的多样性和方法的不一致,陆地生态系统碳密度估算存在很大的不确定性。
3、近年来,随着遥感及相关领域技术发展及普及,光学遥感影像的光谱特性被有效用于反映地物特征信息,且遥感数据具有“全天候工作、高分辨率”等特点,使其能够提供长时间、连续的高分辨率信息,这为陆地生态系统碳密度的遥感估算提供了新的思路。基于遥感数据和机器学习模型的方法是大尺度碳密度估测的重要手段,随机森林模型能很好描述碳密度与遥感变量之间的非线性关系。然而,对于低代码或无代码的人来说,难以在短时间内熟练使用机器学习模型并准确设置各项变量及参数,创建“可重复、可共享”的工作流的将有效解决以上问题,并能够有效缩短操作时间,并能随时调试模型参数提高模型精确度,这极大方便了所有科研及工作人员。
4、knime是开源的数据分析平台,使用者根据自己需求建立工作流,工作流可自动执行重复性数据分析任务,无需代码即可使用大型数据集和先进机器学习模型,使用者可轻松协作、共享和使用工作流。这将有效促进不同部门的科研工作者、企业工作人员、社会群体协作效能,对的“双碳目标”实现及建模提供更多基准数据。
技术实现思路
1、本发明解决的技术问题:本发明的目的是提供一种基于多源遥感数据和工作流的陆地生态系统碳密度估算方法。本发明结合遥感数据、野外采样实测数据,使用机器学习模型,实现陆地生态系统不同碳库碳密度的高精度估算。弥补了因使用野外抽样监测数据中“采样点数量有限和年份滞后”等缺点,而且建立的工作流具有“可复现、可重复、可共享”的优点,有效节约人力和时间成本,显著提高工作效率。
2、技术方案:为了解决上述技术问题,本发明采用的技术方案如下:
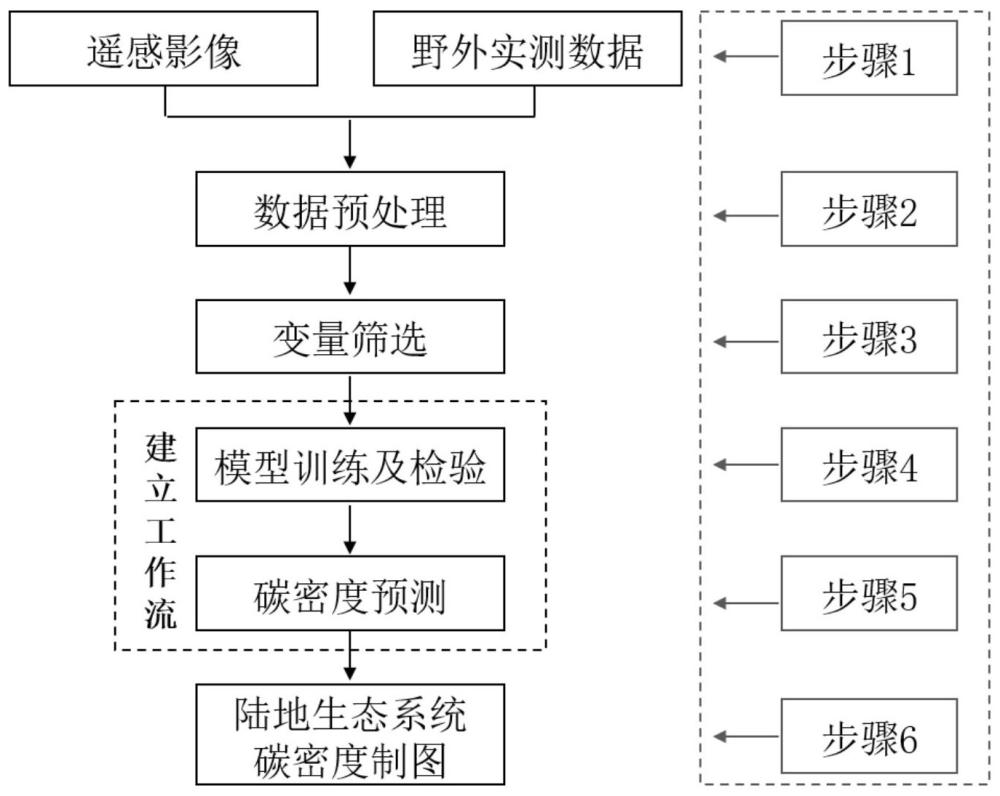
3、一种基于多源遥感数据的陆地生态系统碳密度估算方法,包括以下步骤:
4、步骤1:获取研究区域内的土地覆盖数据以及碳密度抽样野外实测数据,并计算研究区域内的遥感变量数据;
5、步骤2:对遥感变量数据进行预处理;
6、步骤3:根据样点的经纬度信息,提取遥感变量及土地覆盖类型值;
7、步骤4:选取建模数据,利用随机森林算法训练陆地生态系统碳密度估算模型,并通过调节模型参数优化模型;
8、步骤5:选取预测数据,利用随机森林算法预测年份的碳密度,并基于检验样本,对陆地生态系统碳密度估算模型进行精度验证和评价;
9、步骤6:对研究区域的陆地生态系统不同碳库碳密度分别进行制图。
10、作为优选,在步骤1中,获取研究区域内的土地覆盖数据以及碳密度抽样野外实测数据,并计算研究区域内的遥感变量数据,具体内容包括:
11、在开源数据平台下载研究区域内陆地生态系统碳密度野外采样数据集以及土地覆盖数据,筛选碳密度抽样野外实测数据中的有效记录数据,筛选出的样点包括经纬度、碳密度、所属碳库和土地覆盖类型信息;
12、在谷歌地球引擎上利用陆地卫星数据计算研究区在相应年份的归一化植被指数、温度和降水数据并下载到本地。
13、作为优选,在步骤2中,对遥感变量数据进行预处理的具体内容包括:
14、在地理信息系统数据处理与制图软件中对归一化植被指数、温度、降水和土地覆盖数据进行投影、裁剪和拼接。
15、作为优选,在步骤3中,根据样点的经纬度信息,提取遥感变量及土地覆盖类型值的具体内容包括:
16、根据样点经纬度来计算归一化植被指数、温度、降水和土地覆盖值,数据保存为“建模数据.csv”,利用地理信息系统数据处理与制图软件建立渔网并生成点数据,然后导出点数据的id及其经纬度信息,再根据点id计算想要预测年份的归一化植被指数、温度、降水和土地覆盖值,则可以将数据保存为“预测数据.csv”。
17、作为优选,在步骤4中,选取建模数据,利用随机森林算法训练陆地生态系统碳密度估算模型,并通过调节模型参数优化模型,具体内容包括:
18、步骤41:读取建模数据准备随机森林模型训练;
19、步骤42:将随机森林训练模型迭代训练多次;
20、步骤43:最后使用“按组分类”查看完成迭代次数后的模型平均效果。
21、作为优选,在步骤41中,选取建模数据进行随机森林模型训练的具体过程包括:
22、步骤411:写入数据,将“建模数据.csv”利用“写入csv文件”写入数据;
23、步骤412:设置分类变量,利用“数字转字符串”将“土地覆盖类型”和“碳库类型”设置为分类变量。
24、作为优选,在步骤42中,将随机森林训练模型迭代训练多次的具体过程包括:
25、步骤421:随机森林模型迭代次数,利用“计数循环开始”和“循环结束”功能来设置随机森林模型迭代次数;
26、步骤422:设置好迭代次数后,在“分区”中设置数据集中70%作为模型训练样本,其余30%作为模型检验样本;
27、步骤423:在“随机森林学习器”中将“碳密度”设置为因变量,将“归一化植被指数、温度、降水、土地覆盖类型和碳库类型”设置为自变量;
28、步骤424:在“随机森林预测器”中保持默认选项,使用随机森林模型对建模数据样点的碳密度进行预测;
29、步骤425:在“数值得分”中可以查看单次模型运行效果,包括决定系数、平均绝对误差和均方根误差;
30、步骤426:使用“行过滤器”移除其他不需要的行,仅保留决定系数行。
31、作为优选,在步骤5中,选取预测数据,利用训练好的随机森林算法来预测年份的碳密度,具体内容包括:
32、步骤51:建立随机森林训练模型工作流以供预测使用;
33、步骤52:读取预测数据进行随机森林模型预测;
34、步骤53:导出预测结果到本地,并进行制图。
35、作为优选,在步骤51中,利用预测数据和随机森林训练模型进行随机森林预测的具体过程包括:
36、步骤511:写入数据,将“预测数据.csv”利用“写入csv文件”写入数据;
37、步骤512:设置分类变量,利用“数字转字符串”将“土地覆盖类型”和“碳库类型”设置为分类变量;
38、步骤513:在“分区”中设置数据集中70%作为模型训练样本,其余30%作为模型检验样本;
39、步骤514:在“随机森林学习器”中将“碳密度”设置为因变量,将“归一化植被指数、温度、降水、土地覆盖类型和碳库类型”设置为自变量。
40、作为优选,在步骤52中,读取预测数据进行随机森林模型预测的具体过程包括:
41、步骤521:写入数据,将“预测数据.csv”利用“写入csv文件”写入数据;
42、步骤522:设置分类变量,利用“数字转字符串”将“土地覆盖类型”和“碳库类型”设置为分类变量;
43、步骤523:将写入的数据使用“字符串操作”设置预测碳库的分类代码;
44、步骤524:将训练的模型中的“随机森林学习器”分别连接至新的“随机森林预测器”作为预测节点;并根据想要预测的碳库类型,分别将“随机森林学习器”节点分别连接至不同的“随机森林预测器”节点;
45、步骤525:按需考虑是否需要使用“列过滤器”来移除不需要的列,仅需保留id列、经纬度列、碳密度预测结果列;
46、步骤526:当完成所需碳库的结果预测之后,使用“列附加器”将不同碳库碳密度的预测结果进行合并,然后按需考虑是否需要使用“列过滤器”来移除重复和不需要的列和使用“列重命名”来给列标题重命名,并使用“写出csv文件”将结果导出到本地。
47、有益效果:与现有技术相比,本发明具有以下优点:
48、(1)传统陆地生态系统碳密度估算依靠样地调查,耗费人工、效率低下且精度受人为影响较大;而本发明基于多源遥感数据提取遥感变量,利用随机森林算法建立森林碳储量遥感估测模型,节省了人工调查成本、提高了效率,且能实现大范围陆地生态系统的不同碳库的碳密度遥感估测。
49、(2)本发明建立的工作流具有“可重复、可共享、无需代码基础”的特点,本发明展示了工作流建立的过程,本工作流可以适用于任何区域和任何年份,具有很广泛的适用性,为全球碳数据建模提供了重要案例。
50、(3)本发明提供的方法能实现更高的估测精度,以往的类似研究仅仅使用某一种反映植被覆盖指数的数据(如ndvi)来预测某特定生态系统或特定碳库的碳密度,而本方法可以实现使用多源遥感数据对陆地生态系统的不同碳库进行长时间序列预测。
- 还没有人留言评论。精彩留言会获得点赞!