一种基于人脸识别的智能门锁及开锁方法与流程
1.本发明涉及信息安全技术领域,具体地涉及一种基于人脸识别的智能门锁及开锁方法。
背景技术:
2.目前,现有技术中:随着技术发展,智能门禁系统已经走入人们的日常生活中。更加智能、安全、低成本的门禁系统是智能家居的研究热点之一。智慧城市建设不断的推进,智能化产品的安全性和便捷性的研究越来越受重视。通过人工智能识别等方式进行智能门锁的开关以及在运行保障复杂条件下的设备管控和系统维护,越来越受到欢迎。
3.但现有的智能门锁人脸识别技术识别方法,主要是考虑单一的人脸图像,而对人体躯干、步态、声音等综合性信息考虑较少,且由于缺乏对光照、姿态、表情和图像质量变化的鲁棒性,在无约束条件下的人脸识别相对无效。等通过预先假设分布的情况下进行预测,获得低维特征用来描述人脸,但是问题在于整体的方法没有办法包含局部的人脸变化。后续基于局部特征的人脸识别方法逐渐崭露头角,但是手工设计的特征往往缺少鲁棒性。在深度卷积神经网络中引入注意力机制,优化损失函数,提高模型的人脸特征提取能力的应用较少,且只是对欧式距离或三角距离的单独应用。
技术实现要素:
4.为解决上述技术问题,本发明提供一种基于人脸识别的智能门锁及开锁方法,本发明的一种基于人脸识别的智能门锁及开锁方法显著提升了门锁的自动化工作水平,且门锁的安全性和便捷性大大提升,增强了用户体验;一种基于人脸识别的智能门锁,包括信息采集端,信息处理端,智能开锁模块;所述信息采集端获取视频图像以及传感器数据;信息处理端对获取的视频图像及传感器数据进行矩阵向量化;智能开锁模块对信息处理端的信息采用卷积神经网络处理,当满足设定阈值时则开锁,否则继续保持闭锁状态;所述传感器数据包括声音传感器获取的声音信息,声音信息yn(t)由说话声音分量xn(t)和脚步声音分量vn(t)组成,声源信息为s(t),声源反馈参数为gn,n=1,2,t为时间,声音信息满足:yn(t)=s(t)*gn+vn(t)=xn(t)+vn(t);所述矩阵向量化具体为,将获取的时间段t内的视频图像与传感器数据,进行特征提取形成矩阵向量h,将矩阵向量h输入至训练好的卷积神经网络;所述卷积神经网络采用损失函数为q:
5.li=yilog(pi)+(1-yi)(1-log(pi))
6.其中,pi表示第i个视频图像样本中是房主本人人脸及躯干的概率,yi表示为房主本人的人脸及躯干特征参数,将视频图像分成n段,s表示幅度冗余值,由房主人脸及躯干的特征确定,m表示角度冗余值,cosθi表示第i个视频图像样本向量与房主本人特征向量的余弦值。
7.优选地,所述卷积神经网络由三层网络结构组成,第一层是p-net,第二层是r-net,第三层是o-net,所述p-net将输入数据构建5层特征金字塔;所述o-net输出最终的人脸和躯干候选框、人脸和躯干置信度和关键点信息。
8.优选地,所述信息处理端采用csi摄像机通过移动行业处理器接口mipi连接到配备了深度学习库的jetson nano嵌入式系统,通过gpio接口连接。
9.优选地,所述矩阵向量化包括对获取的视频图像数据以及传感器数据进行数字化,具体的将视频图像数据的像素、坐标、采集时间以及传感器数据的说话声音、脚步声音、脚步频率值进行编码形成向量矩阵。
10.优选地,所述当满足设定阈值时则开锁,否则继续保持闭锁状态,即通过卷积网络输出计算结果的置信度,当矩阵向量h与数据服务器存储的矩阵向量相似度满足设定阈值时,则开锁,否则闭锁。
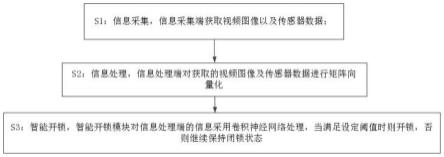
11.本发明还包括一种基于人脸识别的智能门锁开锁方法,其特征在于,包括步骤:s1:信息采集,信息采集端获取视频图像以及传感器数据;s2:信息处理,信息处理端对获取的视频图像及传感器数据进行矩阵向量化;s3:智能开锁,智能开锁模块对信息处理端的信息采用卷积神经网络处理,当满足设定阈值时则开锁,否则继续保持闭锁状态;
12.其中,所述传感器数据包括声音传感器获取的声音信息,声音信息yn(t)由说话声音分量xn(t)和脚步声音分量vn(t)组成,声源信息为s(t),声源反馈参数为gn,n=1,2,t为时间,声音信息满足:yn(t)=s(t)*gn+vn(t)=xn(t)+vn(t);声控系统还包括音质失真控制模块;所述矩阵向量化具体为,将获取的时间段t内的视频图像与传感器数据,进行特征提取形成矩阵向量h,将矩阵向量h输入至训练好的卷积神经网络;所述卷积神经网络采用损失函数为q:
[0013][0014]
li=yilog(pi)+(1-yi)(1-log(pi))
[0015]
其中,pi表示第i个视频图像样本中是房主本人人脸及躯干的概率,yi表示为房主本人的人脸及躯干特征参数,将视频图像分成n段,s表示幅度冗余值,由房主人脸及躯干的特征确定,m表示角度冗余值,cosθi表示第i个视频图像样本向量与房主本人特征向量的余弦值。
[0016]
优选地,所述卷积神经网络由三层网络结构组成,第一层是p-net,第二层是r-net,第三层是o-net,所述p-net将输入数据构建5层特征金字塔;所述o-net输出最终的人脸和躯干候选框、人脸和躯干置信度和关键点信息。
[0017]
优选地,所述信息处理端采用csi摄像机通过移动行业处理器接口mipi连接到配备了深度学习库的jetson nano嵌入式系统,通过gpio接口连接。
[0018]
优选地,所述矩阵向量化包括对获取的视频图像数据以及传感器数据进行数字化,具体的将视频图像数据的像素、坐标、采集时间以及传感器数据的说话声音、脚步声音、脚步频率值进行编码形成向量矩阵。
[0019]
优选地,所述当满足设定阈值时则开锁,否则继续保持闭锁状态,即通过卷积网络输出计算结果的置信度,当矩阵向量h与数据服务器存储的矩阵向量相似度满足设定阈值
时,则开锁,否则闭锁。
[0020]
与现有技术相比,本发明的技术方案具有以下有益效果:
[0021]
解决了传统技术中门锁自动化水平低,本技术创造性的将房主的脚步声、说话声加入到特征向量中,通过卷积神经网络进行判断,大大增强了门锁的安全性、准确性。此外,所述传感器数据包括声音传感器获取的声音信息,声音信息yi(t)由说话声音分量xi(t)和脚步声音分量vi(t)组成。本技术将获取的时间段t内的视频图像与传感器数据,进行特征提取形成矩阵向量h,将矩阵向量h输入至训练好的卷积神经网络;所述卷积神经网络采用损失函数为q;计算损失函数中,通过将参数li与函数的乘积形式,大大增强了训练效果,显著提升了卷积神经网络的判断准确率。
附图说明
[0022]
图1是本发明一种基于人脸识别的智能门锁开锁方法系统图;
具体实施方式
[0023]
本领域技术人员理解,如背景技术所言,传统技术中智能门锁人脸识别技术识别方法,主要是考虑单一的人脸图像,而对人体躯干、步态、声音等综合性信息考虑较少,且由于缺乏对光照、姿态、表情和图像质量变化的鲁棒性,在无约束条件下的人脸识别相对无效。等通过预先假设分布的情况下进行预测,获得低维特征用来描述人脸,但是问题在于整体的方法没有办法包含局部的人脸变化。后续基于局部特征的人脸识别方法逐渐崭露头角,但是手工设计的特征往往缺少鲁棒性。在深度卷积神经网络中引入注意力机制,优化损失函数,提高模型的人脸特征提取能力的应用较少,且只是对欧式距离或三角距离的单独应用。为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
[0024]
实施例一:
[0025]
图1示出了本技术的一种基于人脸识别的智能门锁开锁方法系统图,在一些实施例中,一种基于人脸识别的智能门锁,包括信息采集端,信息处理端,智能开锁模块;所述信息采集端获取视频图像以及传感器数据;信息处理端对获取的视频图像及传感器数据进行矩阵向量化;智能开锁模块对信息处理端的信息采用卷积神经网络处理,当满足设定阈值时则开锁,否则继续保持闭锁状态;所述传感器数据包括声音传感器获取的声音信息,声音信息yn(t)由说话声音分量xn(t)和脚步声音分量vn(t)组成,声源信息为s(t),声源反馈参数为gn,n=1,2,t为时间,声音信息满足:yn(t)=s(t)*gn+vn(t)=xn(t)+vn(t);声控系统还包括音质失真控制模块;所述矩阵向量化具体为,将获取的时间段t内的视频图像与传感器数据,进行特征提取形成矩阵向量h,将矩阵向量h输入至训练好的卷积神经网络;所述卷积神经网络采用损失函数为q:
[0026][0027]
li=yilog(pi)+(1-yi)(1-log(pi))
[0028]
其中,pi表示第i个视频图像样本中是房主本人人脸及躯干的概率,yi表示为房主
本人的人脸及躯干特征参数,将视频图像分成n段,s表示幅度冗余值,由房主人脸及躯干的特征确定,m表示角度冗余值,cosθi表示第i个视频图像样本向量与房主本人特征向量的余弦值。
[0029]
在一些实施例中,所述卷积神经网络由三层网络结构组成,第一层是p-net,第二层是r-net,第三层是o-net,所述p-net将输入数据构建5层特征金字塔;所述o-net输出最终的人脸和躯干候选框、人脸和躯干置信度和关键点信息。
[0030]
在一些实施例中,所述信息处理端采用csi摄像机通过移动行业处理器接口mipi连接到配备了深度学习库的jetson nano嵌入式系统,通过gpio接口连接。
[0031]
在一些实施例中,所述矩阵向量化包括对获取的视频图像数据以及传感器数据进行数字化,具体的将视频图像数据的像素、坐标、采集时间以及传感器数据的说话声音、脚步声音、脚步频率值进行编码形成向量矩阵。
[0032]
在一些实施例中,所述当满足设定阈值时则开锁,否则继续保持闭锁状态,即通过卷积网络输出计算结果的置信度,当矩阵向量h与数据服务器存储的矩阵向量相似度满足设定阈值时,则开锁,否则闭锁。
[0033]
实施例二
[0034]
本发明还包括一种基于人脸识别的智能门锁开锁方法,其特征在于,包括步骤:s1:信息采集,信息采集端获取视频图像以及传感器数据;s2:信息处理,信息处理端对获取的视频图像及传感器数据进行矩阵向量化;s3:智能开锁,智能开锁模块对信息处理端的信息采用卷积神经网络处理,当满足设定阈值时则开锁,否则继续保持闭锁状态;
[0035]
其中,所述传感器数据包括声音传感器获取的声音信息,声音信息yn(t)由说话声音分量xn(t)和脚步声音分量vn(t)组成,声源信息为s(t),声源反馈参数为gn,n=1,2,t为时间,声音信息满足:yn(t)=s(t)*gn+vn(t)=xn(t)+vn(t);声控系统还包括音质失真控制模块;所述矩阵向量化具体为,将获取的时间段t内的视频图像与传感器数据,进行特征提取形成矩阵向量h,将矩阵向量h输入至训练好的卷积神经网络;所述卷积神经网络采用损失函数为q:
[0036][0037]
li=yilog(pi)+(1-yi)(1-log(pi))
[0038]
其中,pi表示第i个视频图像样本中是房主本人人脸及躯干的概率,yi表示为房主本人的人脸及躯干特征参数,将视频图像分成n段,s表示幅度冗余值,由房主人脸及躯干的特征确定,m表示角度冗余值,cosθi表示第i个视频图像样本向量与房主本人特征向量的余弦值。
[0039]
在一些实施例中,所述卷积神经网络由三层网络结构组成,第一层是p-net,第二层是r-net,第三层是o-net,所述p-net将输入数据构建5层特征金字塔;所述o-net输出最终的人脸和躯干候选框、人脸和躯干置信度和关键点信息。
[0040]
在一些实施例中,所述信息处理端采用csi摄像机通过移动行业处理器接口mipi连接到配备了深度学习库的jetson nano嵌入式系统,通过gpio接口连接。
[0041]
在一些实施例中,所述矩阵向量化包括对获取的视频图像数据以及传感器数据进
行数字化,具体的将视频图像数据的像素、坐标、采集时间以及传感器数据的说话声音、脚步声音、脚步频率值进行编码形成向量矩阵,此外还有些实施例采用小波变换、傅里叶变换提取视频图像特征数据形成矩阵特征向量。
[0042]
在一些实施例中,所述当满足设定阈值时则开锁,否则继续保持闭锁状态,即通过卷积网络输出计算结果的置信度,当矩阵向量与数据服务器存储的矩阵向量相似度满足设定阈值时,则开锁,否则闭锁。
[0043]
本发明的一种基于人脸识别的智能门锁及开锁方法,传统技术中门锁自动化水平低,本技术创造性的将房主的脚步声、说话声加入到特征向量中,通过卷积神经网络进行判断,大大增强了门锁的安全性、准确性。此外,所述传感器数据包括声音传感器获取的声音信息,声音信息yi(t)由说话声音分量xi(t)和脚步声音分量vi(t)组成。本技术将获取的时间段t内的视频图像与传感器数据,进行特征提取形成矩阵向量h,将矩阵向量h输入至训练好的卷积神经网络;所述卷积神经网络采用损失函数为q;计算损失函数中,通过将参数li与函数的乘积形式,大大增强了训练效果,显著提升了卷积神经网络的判断准确率。。
[0044]
本领域技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品,因此本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。
[0045]
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1