基于辅助监督学习的行程时间估计方法与流程
本发明属于智能交通技术领域,具体涉及一种基于辅助监督学习的行程时间估计方法。
背景技术
行程时间估计是城市交通领域一个必不可少的重要技术,可以为人们的出行通勤提供帮助,也可以为政府规划决策提供支持。但这并不是一个简单的小问题,而是会受到各种动态因素的影响,如交通动态,路口状况,司机驾驶行为的变化和历史周期性的数据演化等等。这些因素导致行程时间估计存在不确定性和难度。随着支持gps的移动设备的发展和普及,目前已经有大量的轨迹数据在源源不断地产生,并且覆盖城市的各个角落。有了这些海量的历史轨迹数据,我们可以挖掘数据背后的内在规律,通过构建算法模型来学习出行程时间的变化的周期和趋势,从而更加准确地推断当前查询轨迹所需的时间开销。
目前已有的方法大多采用分而治之(divide-and-conquer)的方法,主要是通过将路径分解一系列的路段或者子路径这两类。
(1)基于单一路段的方法:
基于单路段的方法主要通过估计每一条单一路段的轨迹经过时的平均速度,进而根据路段长度计算出经过的平均时间开销,最后将各个路段的时间和累加得到总的时间。但这种方法没有考虑路段之间的路口时间开销。另外,这种估计严重依赖于高质量的速度数据,而这往往在轨迹数据中无法得到。
(2)基于子路径的方法:
基于子路径的方法主要通过将路径分割成一系列的子路径方法,使得路口的时间开销也得到考虑。主要思路都是对历史数据中丰富的公共子路径信息进行拼接和挖掘。尽管这种方法可以克服单一路段方法的许多缺陷,但它仍然是基于启发式设计,而不是直接将行程时间作为算法优化目标。
总而言之,目前已有的方法无法达到令人满意的准确性有两个方面的原因。一个是它们没有把路径看成一个整体,而是拆分成各个子块。在这一拆分过程中,损失了很多有用的信息。并且,它们没有充分利用轨迹数据特有的中间监督标签,也就是每一个中间gps采样点的时间戳信息。另一方面,随着深度学习技术的发展和繁荣,更多的问题可以通过端到端一体式地解决,相较于传统启发式模型要更为高效。并且,深度学习有着强大的表征能力,与手工模型相比,可以捕捉到更多的潜在特征,能够处理行程估计问题中各种复杂的动态性。
技术实现要素:
本发明的目的是针对传统的两类行程时间估计技术的局限性,提出一种基于辅助监督学习的历史轨迹的行程时间估计方法,以克服现有技术的不足。
本发明方法从海量历史轨迹数据中寻找统计规律,通过端到端的深度学习模型对整个行程的时间进行整体的估计。基本步骤包括:特征提取和表示阶段,对轨迹数据进行预处理,分别抽取它的各方面特征;训练和预测阶段,将这些提取的特征用一个统一的双向循环神经网络进行训练和预测;循环神经网络每一步都输出通过当前小区域的时间开销;这些小区域的时间开销的总和即为总路径的时间开销;为了更加有效地进行训练,还引入了双向区间损失函数来约束中间时间开销。
本发明提出的基于辅助监督学习的历史轨迹的行程时间估计方法,分为如下三个阶段:
(一)特征提取和表示阶段,对历史轨迹数据进行预处理,抽取它的各方面特征(包括时间特征和空间特征,驾驶状态特征,短时间和长时间的交通状况特征等)。具体步骤为:
步骤(1),在城市范围内,根据经纬度坐标对网格进行细粒度划分,形成一个个相邻的矩形小区域。将按时间顺序排序,由gps坐标组成的轨迹序列中的每一个坐标点映射到对应的小区域中,形成一个由网格坐标组成的序列。对于相邻轨迹点距离较远,落在不连续的小区域内的情况,可以地图匹配等算法得到中间经过路径,补全这部分不连续的区域信息。
步骤(2),对于每一个网格,挖掘它不同方面的特征。首先,使用嵌入向量技术来挖掘潜在语义信息。嵌入向量技术在自然语言处理和社交网络等领域等到了广泛的使用,主要是利用低维的实数向量来代表每一个词或者事物的语义信息,通过向量空间中的距离关系来衡量实物之间的对应关系。本发明利用嵌入向量技术来表征每一个网格小区域在不同空间以及不同时间段的语义信息。这些信息包含了城市不同的功能区域(例如居民区,商业区或工业区等等)空间区位信息,也包括了早高峰,周末等时间信息。具体地,利用低维向量来表示每一个网格的空间向量vsp,将一天划分成多个时间桶(例如一个小时一个桶),每一条轨迹根据具体落入的时间桶来得到时间向量vtp。对vsp和vtp进行随机初始化,之后在模型训练时跟着模型一起训练。
步骤(3),司机在开车时,在不同的行驶状态时,行驶的速度和驾驶行为都会发生变化。例如,车辆在行驶路径的中间部分时,会更倾向于行驶在大路或者高架上,这时速度会更快。而在刚出发或者快到终点时,由于行驶在小路或者人多的区域,往往速度就会变慢。具体地,使用四维向量vdri来表示当前行驶阶段是出发阶段,中途阶段,还是结束阶段,以及在各个阶段已经行驶的比例。例如,vdri=(1,0,0,0.2)表示司机行驶在开始阶段,占了总行程的20%。
步骤(4),在一个区域内的交通状况,往往随着时间演变会有周期性和规律性的变化。例如,如果一个路段在8点到8点半都很堵,那么8点35分它也可能很堵。也就是说,过去短时间内的交通状况信息,对预测当前的交通状态很有帮助。定义该短时间的交通状况特征为vshort。与此同时,长时间周期性的交通状况变化也能帮助预测当前交通状况,例如工作日和周末的交通状况变化规律。定义该长时间的交通状况特征为vlong。具体来说,
定义:
表示在过去第j个时间区间内,当前小区域gi的交通状况,其中vj表示历史平均速度,nj表示历史轨迹数据数量,leni/vj表示粗略估计的通过时间。将这些交通状况特征按照历史时间顺序输入到一个子循环神经网络中,可以抽取出交通状况特征。
另外,由于历史数据在不同空间区域分布不均衡,有些区域轨迹经过数量较少,可能会对估计的准确性造成影响。为了解决这一数据稀疏问题,将邻接小区域的交通状况信息也考虑进来,即
定义:
表示距离gi距离不超过d的网格集合,收集它们过去短时的交通状况特征,一起输入到神经网络中。其中,x,y表示网格的坐标,gj表示除gi以外的其他网格。
(二)训练阶段,将历史轨迹数据中提取的特征输入到一个统一的双向循环神经网络(bidirectionallstm,参考文献:gravesa,schmidhuberj.framewisephonemeclassificationwithbidirectionallstmandotherneuralnetworkarchitectures[j].neuralnetworks,2005,18(5-6):602-610.)进行训练,并且以双向区间损失函数作为训练的约束;具体步骤为:
步骤(1),构建循环神经网络。定义网络隐层为
ht=φ(xt·wx+ht-1·wh+b)(3)
其中,
也就是说隐状态可以表示为函数:
ht=f(ht-1,xt)(4)
在这基础上,定义遗忘门为:
ft=σ(wf·[ht-1,xt]+bf)(5)
输入门为:
it=σ(wi·[ht-1,xt]+bi)(6)
输出门为:
ot=σ(wo[ht-1,xt]+bo)(7)
记忆单元的更新为:
隐层的更新为:
ht=ot·tanh(ct)(10)
其中,wf、wi、wo、
双向循环神经网络同时使用一个正向的循环神经网络和一个反向的循环神经网络进行计算。其中正向循环神经网络根据序列的顺序依次将之前步骤提取的网格特征输入,而反向循环神经网络则将序列逆序后输入网格特征。这么做的优点在于,可以使得神经网络同时观察到当前网格距离起点和终点的位置距离,从而拥有一个整体的特征。定义它的隐变量为正向和反向网络的拼接
步骤(2),将历史轨迹数据中提取的特征,即空间特征
在每一个经过的小网格输入到双向循环神经网络,以得到经过该网格的通过时间,即wt·hi+b。总的行程的时间开销
定义
步骤(3),定义轨迹经过各个网格序列的真实时间开销向量为t。顺序的真实时间开销向量为tf,逆序的真实时间开销向量为tb。则神经网络估计得到的时间开销向量为:
使用双向区间损失函数对模型进行辅助监督学习,使其不仅学习整条路径的时间开销,同时可以学习各个中间阶段的通行时间。定义双向区间损失函数为:
其中,m表示轨迹是否经过小区域的掩码,[]表示向量每个元素间的操作。
步骤(4),训练的目标是,最小化损失函数l,即:
其中,θ表示模型的训练参数,ε表示时间和空间上的嵌入向量,s是训练集的大小。最后,使用基于时间顺序的反向传播算法对模型进行参数的更新和优化。反向传播算法参考文献:chauviny,rumelhartde.backpropagation:theory,architectures,andapplications[m].psychologypress,2013.
(三)预测阶段,用双向循环神经网络对查询路径中提取的特征进行推断并估计行程时间;具体步骤为:
步骤(1),给定一条没有时间戳标记的真实行程作为查询路径,根据经过的实际路径,得到其映射的网格序列。对于每一个经过的小网格,使用特征提取和表示阶段抽取得到的时空特征vsp和vtp,驾驶状态特征vdri,和历史上短时间和长时间的交通状态特征vshort和vlong,作为该网格的总特征表示v。其中,时空特征的嵌入向量使用经过训练过程的参数更新后的向量信息。短时和长时间的交通状态特征使用经过训练的子循环神经网络进行特征挖掘。
步骤(2),在每一个经过的网格,将抽取的各方面特征输入到已经经过训练的双向循环神经网络中,得到当前的隐变量ht,那么经过当前区域的估计时间为wt·ht+b。而总的时间开销估计值为:
其中,n表示经过的总网格数目,
总的来说,本发明方法有以下几个优点。首先,利用端到端(end-to-end)基于历史数据训练的深度学习方法,直接学习出整条路径的特征并估计出整体的通行时间。我们定义了一个双向区间损失函数,可以在监督整体的路径时间的基础上,同时辅助监督通过中间路段的时间开销。这种引入辅助监督的方法既丰富了路径的样本信息,又可以使得反向传播算法对参数更新时传播信号可以更加准确。其次,提出了一个特征抽取结构,通过提取时空嵌入向量,行驶状态,以及短时间和长时间的交通状况等不同维度的动态特征,能有效地估计出路径的通行时间。最后,在实际环境下经过实验验证,具有比已有方法更好的实验结果。
如表1所示,我们用真实的历史轨迹数据进行实验,包括波尔图和上海两个城市。我们用路段平均时间法,子路径动态规划法,网格全连接网络法,网格卷积网络法等已有方法进行对比。其中,路段平均时间法通过统计每个路段的平均通过时间,直接累加得到结果。子路径动态规划法[yilunwang,yuzheng,andyexiangxue.traveltimeestimationofapathusingsparsetrajecto-ries.inproceedingsofthe20thinternationalconferenceonknowledgediscoveryanddatamining(sigkdd),pages25–34,2014.]利用动态规划找到子路径的最优拼接方法。网格全连接网络法和网格卷积网络法将n×n的整体网格作为输入,分别用全连接网络(multi-layerperceptron)和卷积神经网络(convolutionalneuralnetwork)进行优化和估计。我们使用mae,rmse,mape三个误差度量指标衡量方法的好坏。
其中,y表示真实值,
表1
附图说明
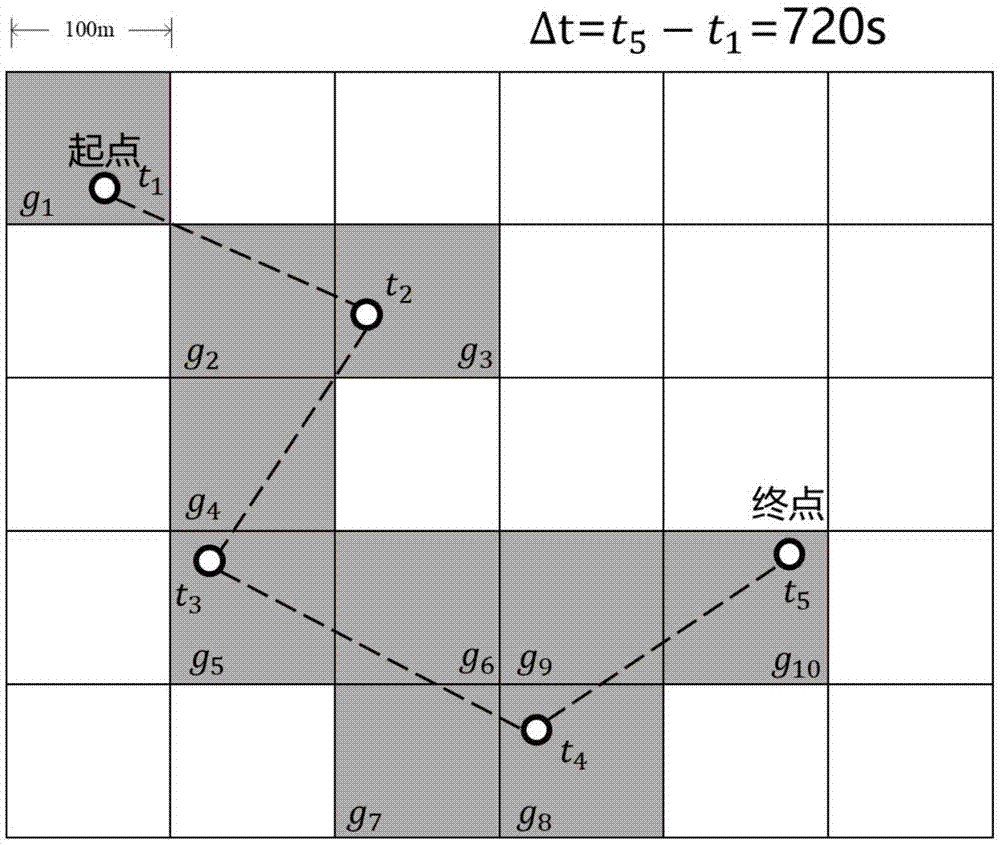
图1表示一个真实轨迹样本,包含每一个中间gps轨迹点的时间戳信息,一共经过720s。
图2表示需要查询的路径样本,仅包含具体经过的路径信息,不包含任何时间戳信息。
具体实施方式
下面结合具体实例来说明本发明的具体实施过程:
如图1中的历史轨迹用于训练,并估计图2中的行程时间。
一、预处理阶段,特征提取和表示阶段,对轨迹数据进行预处理,抽取它的各方面特征。以图1为例,具体步骤为:
(1)在城市范围内,进行细粒度网格划分,分成一个个相邻的小区域。如图1中,将地图划分成5×6个网格。将轨迹序列中的每一个坐标点映射到对应的小区域中,形成一个网格序列,即g={g1,g2,…,g10}。
(2)对于每一个网格,挖掘它不同方面的特征。例如,对于g1,使用随机向量
其次,使用四维向量
最后,使用过去短时间和长时间的交通状况信息来预测当前的交通状况特征
二、训练阶段,具体步骤为:
(1)建立双向循环神经网络(bi-directionallstm)模型。随机初始化模型的各项参数,包括遗忘门,输入门,输出门的矩阵参数和偏置参数。
(2)将历史轨迹数据中提取的特征,即空间特征vsp,时间特征vsp,驾驶状态特征vdri,历史上短时间和长时间的交通状态特征vshort和vlong,拼接成一个统一的特征向量。以网格g1为例
(3)在每一个经过的小网格输入到双向循环神经网络,以得到经过该网格的通过时间,即wt·hi+b。总的行程的时间开销为:
例如,定义w=(0.1,0.3,..,0.7),10个网格隐层变量值为h1=(0.8,0.3,…,0.2),…,h10=(0.7,0.4,..0.5),偏置值b=0.7,则:
(4)定义轨迹经过各个网格序列的真实时间开销向量为t。顺序的真实时间开销向量为tf=(70,120,…,720),逆序的真实时间开销向量为tb=(720,640,…,50)。则神经网络估计得到的时间开销向量为:
使用双向区间损失函数对模型进行辅助监督学习,使其不仅学习整条路径的时间开销,同时可以学习各个中间阶段的通行时间。定义双向区间损失函数为:
其中,m表示轨迹是否经过小区域的掩码,[]表示向量每个元素间的操作。
(5)最小化损失函数l,即:
其中,θ表示模型的训练参数,ε表示时间和空间上的嵌入向量,s是训练集的大小。最后,使用基于时间顺序的反向传播算法对模型进行参数的更新和优化。
三.预测阶段,具体步骤为(以图2为例):
(1)给定一条没有时间戳标记的真实行程作为查询路径g={g1,g2,…,g8},根据经过的实际路径,得到其映射的网格序列。对于每一个经过的小网格g1~g8,使用特征提取和表示阶段抽取得到的时空特征vsp和vtp,驾驶状态特征vdri,和历史上短时间和长时间的交通状态特征vshort和vlong,作为该网格的总特征表示v。其中,时空特征的嵌入向量使用经过训练过程的参数更新后的向量信息。短时和长时间的交通状态特征使用经过训练的子循环神经网络进行特征挖掘。
(2)在每一个经过的网格,将抽取的各方面特征输入到已经经过训练的双向循环神经网络中,得到当前的隐变量ht,那么经过当前区域的估计时间为wt·ht+b。而总的时间开销估计值为;
其中,w和b均由之前训练过程中得到的参数。
- 还没有人留言评论。精彩留言会获得点赞!