基于集成学习的交通参与者事故风险预测方法与流程
本发明涉及一种基于集成学习的交通参与者事故风险预测方法。
背景技术:
交通参与者是影响道路交通安全的关键,但传统的研究和管理应用都受制于信息采集和感知手段的限制,难以对人员属性与交通安全的关联性进行挖掘,从而很难实施具有针对性的交通安全治理。目前我国的交通安全与规范治理工作主要以违法查处为主,积累有大量的车辆及人员的交通违法数据资源。交通违法与交通安全具有显著的相关性,因此对交通违法数据进行数据挖掘,能够提取出必要的交通参与者安全特性信息。
在数据挖掘方法中,集成学习(ensemblelearning)具有优异的性能,这种方法将几种机器学习技术组合成一个预测模型的元算法(meta-algorithm),以减小方差(bagging),偏差(boosting),或者改进预测(stacking),通过联合几个模型来帮助提高机器学习结果。与单一模型相比,这种方法可以很好地提升模型的预测性能。
本发明以集成学习算法构建交通参与者的交通事故风险预测模型,主要以交通违法数据进行模型拟合,通过优化抽样方法,减轻不对称数据集对模型性能的影响,在优化模型性能时兼顾模型准确性与误判率,以提升人员风险预测准确性。
技术实现要素:
本发明的目的是提供一种基于集成学习的交通参与者事故风险预测方法,采用优化抽样的集成学习算法,对存在交通违法记录的交通参与者的交通安全风险进行预测评价,填补当前在交通安全中参与者因素定量分析方法的缺失,进一步提高交通安全治理工作的主动性和针对性。
本发明通过判定规则划分高危人员数据集和一般人员数据集,采用优化的抽样方法,基于集成学习算法进行分类器训练与校正,将性能最优的集成分类器拟合为交通参与者交通事故风险预测模型,能够输出人员交通安全属性以及风险概率。
本发明的技术解决方案是:
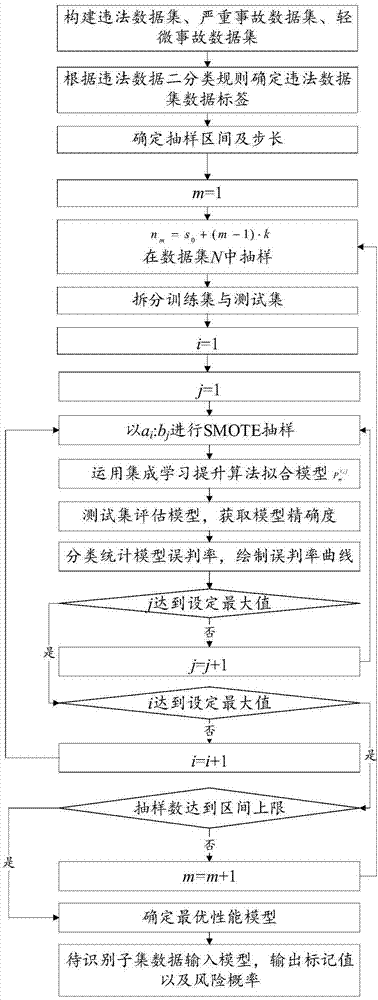
一种基于集成学习的交通参与者事故风险预测方法,包括以下步骤,
s1、基于原始的交通违法数据与事故数据,构建违法数据集、严重事故数据集、轻微事故数据集;
s2、将违法数据集二分类,即高危人员、一般人员,根据分类规则确定数据标记值label,据此将违法数据集分为高危人员数据子集d、一般人员数据子集n以及待识别子集u;
s3、根据数据集n样本量设定抽样区间s以及循环步长k,区间上边界s一般不超过总样本量25%;
s4、样本量nm=s0+(m-1)·k,s0为抽样区间下限值,m为循环次数,初值为1;从数据集n中随机抽取样本量为n的样本nm;
s5、将数据集d与nm合集gm拆分为训练集和测试集;
s6、对训练集进行smote抽样,设置高危人员数据子集d扩样比例ai;其中,当i=1时,ai=1,当i>1时,ai=ai-1+1,i初值为1,i设有设定的取值上限;
s7、对于高危人员扩样比例ai,设置一般人员nm数据子集缩样比例bj;其中,当j=1时,bj=1,当j>1时,bj=bj-1+1,j初值为1,j设有设定的取值上限;对于smote抽样比例ai:bj,进行训练集内两类标签样本的扩样、缩样处理,作为分类器的训练样本集;
s8、运用集成学习算法进行高危人员分类器的训练,确定模型参数,实现交通参与者交通事故风险预测模型
s9、以测试集数据进行模型
s10、将一般人员数据子集n中的抽样样本nm补集nm’内数据根据违法次数分类,并按类别输入模型
s11、j是否达到取值上限;若是,判断i是否达到取值上限,若是,则进入s12,否则i=i+1,转入s6;否则,j=j+1,转到s7;
s12、检测nm是否达到抽样区间上限值,若是则进入s13,否则m=m+1,返回s4;
s13、由s9、s10的模型精确度、误判率分析具有最优性能的模型
s14、将步骤s2中待识别子集数据输入模型,确定对应数据标记值以及风险概率。
进一步地,步骤s8中所述的集成学习算法包括随机森林算法、adaboost算法、xgboost算法、gbdt算法;
进一步地,步骤s2中所述的基于分类规则赋予对应数据标记值label的方法具体为:
高危人员:一类为存在违法记录且存在负主要责任或全部责任的严重交通事故记录的交通参与者;另一类为存在违法记录,仅存在轻微事故记录,且事故记录不低于2条的交通参与者;
一般人员:存在违法记录但无事故记录的交通参与者;
不满足上述判别条件的数据构成待识别子集。
进一步地,步骤s1中原始的交通违法数据与事故数据包含相关人员证件信息;对违法记录进行汇集、分类处理操作后获得违法数据集;违法数据集为人员的违法记录全样本数据,违法数据集信息包含人员证件号码、违法次数、违法种类、扣分罚款情况、事故相关违法行为发生情况、违法发生时段。
进一步地,步骤s1中事故相关违法行为发生情况通过对应分析方式获得,并提取交通事故影响程度较高的违法类型,作为违法数据集的数据属性。
进一步地,步骤s1中所述违法发生时段是将时间连续型变量转化为离散变量,根据违法时间特征进行分类。
本发明的有益效果是:
一、本发明采用集成学习算法对交通违法数据进行挖掘,实现基于交通参与者违法记录的安全风险预测,模型能够输出人员交通安全风险概率与属性。
二、本发明采用的集成学习算法,相较于决策树、神经网络等传统分类方法,在预测性能上具有显著的优势,保证了对人员交通事故风险预测的准确度。
三、本发明在抽样环节进行了优化提升,对随机抽样与smote抽样都进行了改进,能够一定程度上缓解不均衡数据集影响模型精确度的问题,对提升模型性能具有显著作用。
附图说明
图1是本发明实施例基于集成学习的交通参与者事故风险预测方法的流程示意图。
图2是实施例中数据集的说明示意图。
图3是实施例中重要度前20位的属性变量的说明示意图。
图4是实施例中模型精确度与误判率曲线。
具体实施方式
下面结合附图详细说明本发明的优选实施例。
实施例
一种基于集成学习的交通参与者事故风险预测方法,如图1,具体的方法流程为:
s1、基于原始的交通违法数据与事故数据,构建违法数据集、严重事故数据集、轻微事故数据集;
实施例中,步骤s1中原始的交通违法数据与事故数据包含相关人员证件信息;对原始违法记录进行汇集、分类等预处理操作后获得违法数据集;违法数据集为人员的违法记录全样本数据,数据集信息包含人员证件号码、违法次数、违法种类、扣分罚款情况、事故相关违法行为发生情况、违法发生时段。
s1中事故相关违法行为发生情况通过对应分析方式获得,并提取交通事故影响程度较高的违法类型,作为违法数据集的数据属性。
s1中违法发生时段是将时间连续型变量转化为离散变量,根据违法时间特征进行分类。
s2、将违法数据集二分类,即高危人员、一般人员,根据分类规则确定数据标记值label,据此将违法数据集分为高危人员数据子集d、一般人员数据子集n以及待识别子集u;
分类规则具体为:高危人员指(1)存在违法记录且存在负主要责任或全部责任的严重交通事故记录的人员;(2)存在违法记录,仅存在轻微事故记录,且事故记录不低于2条的人员;一般人员指存在违法记录但无事故记录的人员;不满足上述判别条件的数据构成待识别子集。
s3、根据数据集n样本量设定抽样区间s以及循环步长k,区间上边界s一般不超过总样本量25%。
s4、样本量nm=s0+(m-1)·k,s0为抽样区间下限值,m为循环次数,初值为1;从数据集n中随机抽取样本量为nm的样本nm。
s5、将数据集d与nm合集gm拆分为训练集和测试集。
s6、对训练集进行smote抽样,设置高危人员数据子集d扩样比例ai;其中,当i=1时,ai=1,当i>1时,ai=ai-1+1,i初值为1,i设有设定的取值上限,
i取值上限通常为4;
s7、对于高危人员扩样比例ai,设置一般人员nm数据子集缩样比例bj;其中,当j=1时,bj=1,当j>1时,bj=bj-1+1,j初值为1,j设有设定的取值上限,j取值上限通常为4;对于smote抽样比例ai:bj,进行训练集内两类标签样本的扩样、缩样处理,作为分类器的训练样本集;
s8、运用集成学习算法进行高危人员分类器的训练,确定模型参数,实现交通参与者交通事故风险预测模型
s9、以测试集数据进行模型
s10、将一般人员数据子集n中的抽样样本nm补集nm’内数据根据违法次数分类,并按类别输入模型
s11、j是否达到取值上限;若是,判断i是否达到取值上限,若是,则进入s12,否则i=i+1,转入s6;否则,j=j+1,转到s7;
s12、检测nm是否达到抽样区间上限值,若是则进入s13,否则m=m+1,返回s4;
s13、由s9、s10的模型精确度、误判率分析具有最优性能的模型
s14、将步骤s2中待识别子集数据输入模型,确定对应数据标记值以及风险概率。
具体示例
本实施例以机动车驾驶人为分析对象。
s1、通过与数据库对接获取区域内2年的交通违法记录以及事故记录。
将发生死亡或受伤严重或发生肇事逃逸的交通事故作为严重事故,其他事故作为轻微事故,据此对原始的事故记录进行分类,并将事故类型与驾驶人证件信息作为严重事故数据集与轻微事故数据集的属性特征,获取两数据集样本数据。
进一步地,对违法原始数据进行预处理,对驾驶人的违法信息进行汇集统计,包括累计违法次数、违法种类、累计扣分分值、平均扣分分值(分/次)、单次最大扣分分值、累计罚款金额、平均罚款金额(元/次)。
采用对应分析法对交通事故数据与违法原始数据进行降维处理,根据违法与事故在类型上的相关性对违法种类进行分类,并提取其中相关性最高的五类作为事故风险违法行为字段的数据属性,如表1所示。
表1.事故相关违法类型划分情况
根据实施例所在区域路网的交通流运行以及交通违法事件发生规律特征,将时间进行聚合,并划分分析时段,将连续型变量转化为标称型变量;在另一个实施例中,通过聚类等其他统计方式进行时段划分。
驾驶人特征数据则根据驾驶人证件号码中提取驾驶人年龄、性别、所属省市编码;根据上述各环节提取的信息生成违法数据集,如表2所示。
表2.违法数据集部分数据
s2、对违法数据集内全样本i进行高危驾驶人与一般驾驶人二分类。如图4,将存在违法记录且存在负主要责任或全部责任的严重交通事故记录的驾驶人作为高危驾驶人的一种情况,符合条件的数据划为数据集d1;将存在违法记录,仅存在轻微事故记录,且事故记录不低于2条的驾驶人作为高危驾驶人的另一种情况,符合条件的数据划为数据集d2;高危驾驶人数据集d=d1+d2。存在违法记录但无事故记录的驾驶人对应数据合成一般驾驶人数据集n。
据此对违法数据集中满足规则的数据确定高危或一般的数据标记值label,另外无法适用于此分类规则的数据子集u=i-n-d,则为待识别数据子集。
s3、根据数据集n样本量设定抽样区间s以及循环步长k,区间上边界s一般不超过总样本量25%。
本实施例中,数据集样本量超过84000,抽样区间s=[200,4000],循环步长k为200。
s4、样本量nm=s0+(m-1)·k,s0为抽样区间下限值,m为循环次数,初值为1;从数据集n中随机抽取样本量为nm的样本nm。
本实施例中,初始抽样数为200。
s5、将数据集d与nm合集gm拆分为训练集和测试集。
本实施例中,训练集与测试集的拆分比例为9:1。
s6、对训练集进行smote抽样,设置高危驾驶人数据子集d扩样比例ai,其中a1=1,ai=ai-1+1,i最大值为4。
s7、对于高危驾驶人扩样比例ai,设置一般驾驶人nm数据子集缩样比例bj,其中b1=1,bj=bj-1+1,j最大值为4;对于smote抽样比例ai:bj,进行训练集内两类标签样本的扩样、缩样处理,作为分类器的训练样本集。
s8、运用随机森林算法进行高危驾驶人分类器的训练,确定模型参数,实现驾驶人交通事故风险预测模型
s9、以测试集数据进行模型
s10、将一般驾驶人数据子集n中的抽样样本nm补集nm’内数据根据违法次数分类,并分别将违法1次、2次、3次、4次、5次、6次及以上的类别数据输入模型
s11、j是否达到设定最大值;若是,判断i是否达到设定最大值,若是,则进入s12,否则i=i+1,转入s6;否则,j=j+1,转到s7。
s12、检测nm是否达到区间上限s,若是则进入s13,否则m=m+1,返回s4。
s13、由s9、s10的模型精确度、误判率分析具有最优性能的模型
本实施例中,采用随机森林算法,训练集高危与一般驾驶人扩样缩样比例从1:1开始,直至4:4结束;综合误判率、精确度及指标稳定性进行对比分析,确定最优性能模型为
s14、将步骤s2中待识别子集数据输入模型,确定对应数据标记值以及风险概率。部分判断结果如表3所示。
表3.运用本发明方法的高危驾驶人识别结果
- 还没有人留言评论。精彩留言会获得点赞!