一种基于卡口数据的路段交通状态判别方法与流程
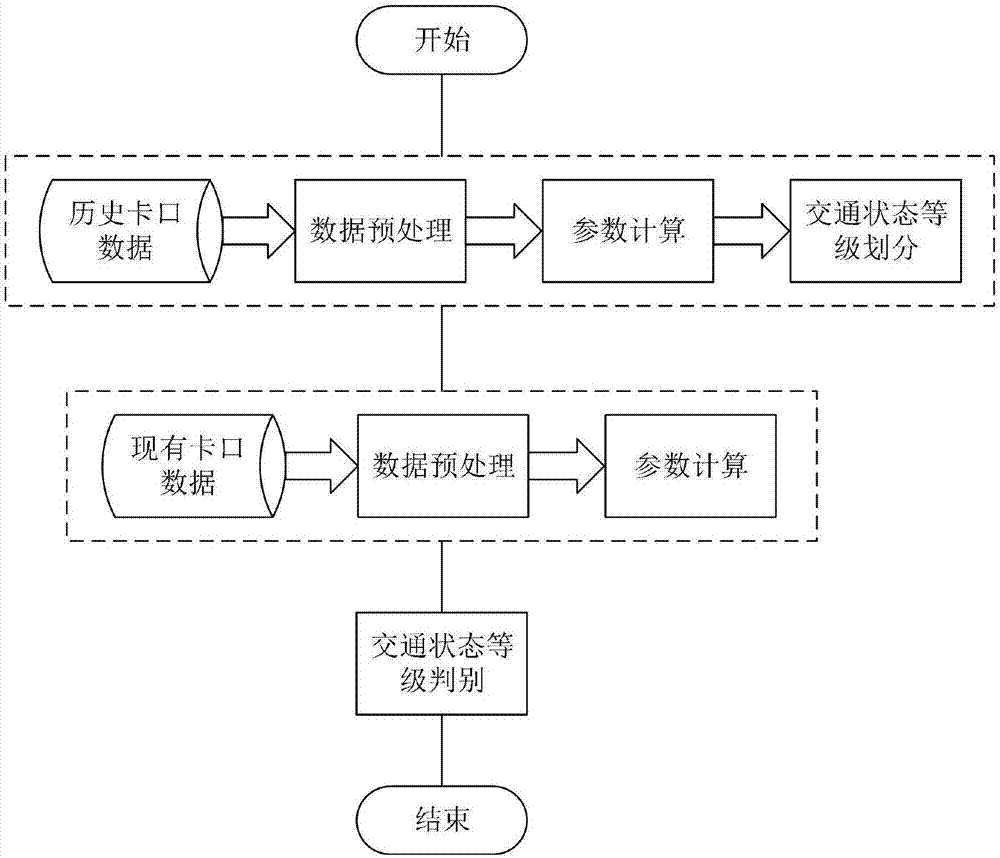
本发明涉及智能交通领域,具体是一种基于卡口的路段交通状态判别方法。
背景技术:
路段的交通状态能够反映道路通行状况,合适的路段交通状态判别方法能够实时、准确的获取路段的通行状态信息以确保道路安全畅通。交通管理人员也可通过道路交通状态信息实施相应管理和控制措施,提高道路通行效率,减少拥堵发生。随着城市化进程的快速发展,机动车保有量日益增加,故对于城市道路交通状态判别并缓解道路拥堵的任务显得越来越重要。
城市道路交通状态评价主要分为宏观和微观两个层次。宏观层次主要针对城市路网的整体交通状态进行评价分析,微观层次主要针对城市中的主干路和快速路进行交通状态的评价分析。本文着重描述关于微观层次,即对路段进行交通状态的划分和判断。
目前关于使用卡口数据对路段交通状态判别的方法较少,故本文提出一种针对卡口数据的路段交通状态等级划分及判别方法,使用路段历史卡口数据对道路交通状态等级划分方法,并对现有数据的交通状态进行判别,针对性和适应性较强。
技术实现要素:
本专利要解决的技术问题是提供一种针对卡口数据来对交通状态进行判断的方法,以便于根据卡口数据能够准确判断更具实际意义的交通状态。
为了解决上述问题,本专利提供的技术方案包括一种相对的路段交通状态等级划分方法所述方法包括:
步骤一,交通状态类别划分
1、数据预处理
提取待检测路段所连接的两卡口的历史数据,优选的历史数据可以是工作日连续多天数据,设有s天的历史数据。将数据以一天为周期进行处理,剔除异常数据和重复数据。对数据进行降维处理,保留其中的卡口编号、车牌号码、行驶方向、过车时间信息,删除其余无效信息。将降维后的数据按照车牌号码分类并按时间顺序排列,即给每辆车分配一个编号并按编号由小到大排列,对编号相同的数据按照时间由小到大顺序排列。由于部分车辆可能会在待检测路段掉头或卡口检测器自身存在缺陷,致使部分车辆数据显示此车辆在短时间内连续经过同一卡口,故需剔除车辆编号相同且卡口编号也相同的相邻数据。由于部分车辆可能在通过上行方向卡口后再待检测路段某地点停泊,致使车辆经过待检测路段耗时过大,影响后续参数计算,故需要剔除此部分车辆数据,具体方法如下:
(1)计算车辆编号i的每相邻两条数据之间的时间差并写入集合ti={δt1,δt2,…,δtn}。其中δtn=tn+1-tn,式中δtn表示车辆编号为i的第(n+1)条数据与其第n条数据过车时间之差,tn表示车辆编号为i的第n条数据的过车时间。
(2)设置时间差阈值δts,其值大小可以根据路段正常行驶时间进行确定,或根据经验值确定。遍历时间差集合中的所有元素,若某元素大于时间差阈值δts,则剔除该元素及该元素所对应的两条数据。
2、路段基本参数计算
设时间周期为t,将一天划分为c个时段。对一天的数据,计算其每个时间周期内的流量qj和平均速度vj及其平均值,具体计算方法如下:
(1)在每个时间周期t所划分的时间段内,遍历车辆编号相同的数据,若某车辆依次经过路段所连接两卡口,且经过上行方向卡口的时间在此时间段内,则令此时段路段流量值增1。由此可得第i(i∈1,2,…,s)天每个时段的流量的集合qi={qi1,qi2,…,qic},其中qc表示第i天第c个时段的路段流量。则流量平均值的集合可写为q={q1,q2,…,qc},其中
(2)若数据满足步骤一2(1)中的判断条件,即某两条相邻数据车辆编号相同,依次经过待检测路段所连接的两卡口,且经过上行方向卡口的时间在所求时间段内。将符合条件的每一天的每个时段的速度值写入集合得vj={vj1,vj2,…,vjl},其中j∈(1,2,…,c);l表示满足判断条件的速度值的个数。则第i(i∈1,2,…,s)天每个时段的速度的集合vi={vi1,vi2,…,vic},其中
3、计算各时段的路段畅通率和路段负荷裕度
按上述步骤求得s天数据的每个时段的路段流量和平均速度后,计算每个时间周期t内的路段负荷裕度mi和路段畅通率oi,具体计算方法如下:
(1)路段负荷裕度计算公式为:
式中mi表示第i个时段的路段负荷裕度;qi(qi∈q)表示s天历史数据计算所得的第i个时段的路段流量平均值;;qm为一个能够反应路段最大交通量的值,可取待检测路段的最大设计交通量或待检测路段的历史数据最大交通量。由此可得各时段的路段负荷裕度集合m={m1,m2,…,mc}。
(2)路段畅通率计算公式为:
式中oi表示第i个时段的路段畅通率;vi(vi∈v)表示s天历史数据计算所得的第i个时段的路段速度平均值;vl表示待检测路段的设计最大通行速度。由此可得各时段的路段畅通率集合o={o1,o2,…,oc}。
4、交通状态等级划分
由上述步骤计算所得的各时段路段负荷裕度和路段畅通率构成二维空间数据集,并在二维坐标轴下构成点集。则此数据集使用k-means聚类算法,计算可得到k个聚类中心点,每个聚类中心点即代表此路段的一个交通状态。计算步骤如下:
(1)根据路段交通状态复杂程度或由经验值设置路段交通状态等级数量k,即最终可得k个聚类中心点。
(2)距离度量采用欧式距离进行计算,计算公式如下:
式中i,j∈(1,2,…,c);其中mi,mj∈m;oi,oj∈o。
(3)随机选取k个点作为初始簇的质心,计算各点到质心的欧式距离,并将各点划分到与其距离最近的簇。
(4)重新计算每个簇的质心点,将新的质心点作为簇的质心点。
(5)重新计算每个点到新的质心点的欧式距离,并将各点分配给距离最近的簇。计算每个簇的质心点并更新,若质心点改变,则继续重复此计算步骤。若质心点不变则计算结束,输出k个质心点即为聚类中心点。将k个聚类中心点写入集合k={k1,k2,…,kk},其中kh=(mh,oh),表示第h(h∈1,2,…,k)个聚类中心点的坐标由此点的路段负荷裕度mh和路段畅通率oh组成。
步骤二,数据提取
1、与步骤一1计算方法类似,提取需判断其交通状态的时段s的卡口数据,保留其卡口编号、车牌号码、行驶方向、过车时间信息,删除其余无效信息。给每辆车分配一个编号,即车牌号码相同的数据分配一个相同的编号并将数据按照编号有小到大顺序排列,再将编号相同的数据按照时间由小到大的顺序排列。
2、与步骤一2中计算方法类似,遍历所有数据,若有相邻两条数据车辆编号相同,按时间顺序依次经过带检测路段所连接梁卡口,且其过车时间差值δt小于时间差阈值δts,则路段流量增加1,由此方法计算可得所提取的时段s内的路段流量qs。并且计算满足上述条件的每相邻两条数据之间的速度值
3、计算需判断其交通状态时段的路段负荷裕度,首先将路段流量qs转化为时段t内的路段流量,然后即可求得其路段负荷裕度,计算公式如下:
式中s为所提取的需检测其路段交通状态的数据时间段;t为交通状态划分时所选的时间周期;qs为所提取的时段s内的路段流量;qm表示所检测路段的设计最大通行流量。
4、计算所提取的时段s内数据的路段畅通率,计算公式为:
式中va表示所提取的时段s内的数据计算所得的路段平均速度;vl为一个能够反应路段最大通行速度的值,可取待检测路段的设计最大通行速度或待检测路段的历史数据计算所得的最大速度值。
步骤三、交通状态等级判断
1、计算步骤二所得的路段负荷裕度m和路段畅通率o与步骤一所得的k个聚类中心的欧式距离,计算公式如下:
式中h∈(1,2,…,k),mh和oh分别表示第h个聚类中心点的路段负荷裕度和路段畅通率。将计算所得的欧式距离写入集合d={d1,d2,…,dk}。
2、计算其对于每个聚类中心点的隶属度,计算公式如下:
式中pi表示所提取的时段s内的数据属于第i个路段交通状态等级的隶属程度;di表示(m,o)与第i个聚类中心点的欧式距离。将计算所得的隶属度pi写入集合p={p1,p2,…,pk},找出集合中的最大值pm,则所检测数据路段交通状态等级为第m级,即与时段s内的数据计算所得点(m,o)距离最小的聚类中心所代表的交通状态等级即为所检测时段的路段交通状态。
本文采用相对一种相对的路段交通状态等级划分方法,针对卡口数据进行处理和分析,并采用路段畅通率和路段负荷裕度两个参数反映路段的交通状态信息。最终计算得出当前交通状态对路段的每种交通状态的隶属程度,能够更加准确的表达路段交通状态信息,更具有参考意义。
附图说明
图1为基于卡口数据的路段交通状态判别方法流程图;
图2为聚类分析结果示意图。
具体实施方式
为了能够更加清晰准确的说明本发明对于路段交通状态的判断方法,下面结合具体例子对本发明的计算方法等进行介绍。下面所描述的例子并不代表本发明所有例子,故基于本发明的理论未做出创新性成果前提下的例子都属于本发明的保护范围。
本例采用蚌埠市卡口数据对本发明进行说明,欲判断工农路下游路段交通状态。首先需提取记录东海大道路段的历史卡口数据,对历史数据进行一系列分析计算,并使用聚类算法对历史数据计算所得的参数进行运算,得出每个交通状态的参数,即聚类中心点。然后根据需要判断其交通状态的时段数据进行计算得出其判别参数,根据判别参数距每个聚类中心的距离对其进行交通状态进行判别。
步骤一,交通状态类别划分
1、数据预处理
蚌埠市工农路与涂山路交叉口处卡口的卡口编号为“340300100538”,工农路与荆山路交叉口处卡口的卡口编号为“340300100671”,欲判断上述两卡口之间路段的交通状态可以提取两卡口的2016年6月1日到2016年6月7日共七天的历史数据。首先剔除数据中的异常数据和重复数据,由于所提取的卡口数据包含多种信息,故为了简化计算方便数据处理需要对数据进行降维处理。即保留其中的卡口编号、车牌号码、行驶方向、过车时间信息,删除其余无效信息。然后对数据进行排序,将车牌号码相同的数据赋予一个车辆编号并按照车辆编号由小到大的顺序排列。再将车辆编号相同的数据按照过车时间由小到大的顺序排列即可完成排序工作。
由于上述两卡口之间的路段长度约为778m,限速值为50km/h,道路为次干路,设计车速约为30—50km/h,故取时间阈值为
2、路段基本参数计算
本例取时间周期t=5min,故一天可以被划分为288个时段,需要计算出每个时段内的路段流量qj和路段平均速度vj。
(1)对完成步骤一1后得到的数据进行遍历,若某两条相邻数据车辆编号相同,依次经过卡口编号为“340300100534”的卡口和卡口编号为“340300100035”的卡口,且经过第一个卡口的过车时间在所求时段内,则所求时段内的路段流量值增加1,最终可求得7天的历史数据中每天的每个时段的路段流量值qc。然后对1天所划分的288个时段中每个时段的路段流量求其平均值,即求每个时段7天的路段流量平均值qj,写入集合q,即为所求。
(2)对完成步骤一1后得到的数据进行遍历,若某两条相邻数据车辆编号相同,依次经过卡口编号为“340300100534”的卡口和卡口编号为“340300100035”的卡口,且经过第一个卡口的过车时间在所求时段内,则计算这两条数据之间的过车时间差值,由路段长度为778m可求得一个过车速度值。对每个时段的过车速度值求其平均值即可得到每天每个时段的路段速度平均值vij,写入集合vi。最终求出每个时段在七天内的路段速度平均值,写入集合v,即为所求。
3、计算各时段的路段畅通率和路段负荷裕度
得到各时段的平均路段流量和平均路段速度之后即可计算每个时段内的路段负荷裕度mi和路段畅通率oi。
(1)路段负荷裕度表示在某个时间段内路段流量接近满负荷的程度大小,在一定程度上反应了路段拥堵程度,故可以用路段负荷裕度作为路段交通状态等价划分和评价的一个参数,使用下述公式计算:
其中qm为反应路段交通量最大值的参数,本例取每5分钟的最大交通量为184。qi取遍每个时段的平均路段流量即可计算处每个时段的路段负荷裕度。
(2)路段畅通率表示路段实际通行速度占理论或实际最大通行速度的比重,也可以在一定程度上反应路段的拥堵程度,故可以用路段畅通率作为路段交通状态等价划分和评价的一个参数,使用下述公式计算:
其中vl为反应路段最大通行速度的参数,本例取历史数据计算所得的路段最大通行速度为17m/s。vi取遍每个时段的平均路段速度,带入公式计算即可得到每个时段的路段畅通率。
4、交通状态等级划分
由上述计算可得288个时段中各时段的路段负荷裕度和路段畅通率,将这两个参数组合在一起构成二位空间数据集,故每个时段的路段负荷裕度和路段畅通率可以构成一个二维坐标轴下的点。然后使用k-means聚类算法对数据集进行聚类分析,即可得到k个聚类中心点,则每个聚类中心点代表一个路段交通状态,故而可将路段的交通状态划分为k个等级。计算步骤如下:
(1)设置路段交通状态等级数量,本例将路段交通状态划分为4个等级,分别表示畅通,基本畅通,拥堵,严重拥堵四个交通状态,即k=4。
(2)设置距离度量方法,本例中的采用欧式距离对数据集中任意两点之间的距离进行度量,欧式距离计算公式如下:
其中mi和mj分别表示i点的路段负荷裕度和j点的路段负荷裕度。oi和oj表示i点的路段畅通率和j点的路段畅通率。
(3)从数据集中随机选取4个点作为初始簇的质心,计算各个点到质心的欧式距离,然后将各点分配到距离其最近的簇。
(4)得到初始的4个簇后,重新计算每个簇的质心点,使得质心点到其所在的簇的各个点的欧式距离之和最小。
(5)重新计算数据集中的每个点到新的质心点之间的欧氏距离,并将各点重新分配给距其最近的簇,最后计算每个簇的新的质心点。若质心点发生改变,则重复此计算步骤。若质心点没有改变,则分别输出4个质心点的路段负荷裕度和路段畅通率,代表此路段的4个交通状态。如图2所示为聚类分析之后得到结果,横坐标为路段负荷裕度,纵坐标为路段畅通率,其中菱形代表畅通状态,圆形表示基本畅通状态,三角形表示拥堵状态,十字形表示严重拥堵状态。
步骤二,数据提取
经上述计算之后便可对现在的路段交通状态进行判别,为了简化计算本例选取上述路段的2016年6月8日10:00到10:05的数据,判断此时段路段的交通状态,即所提取的数据的时段s=5min。
1、首先对数据进行降维处理,保留其中的卡口编号、车牌号码、行驶方向、过车时间信息,删除其余无效信息。然后对数据进行排序,将车牌号码相同的数据赋予一个车辆编号并按照车辆编号由小到大的顺序排列。再将车辆编号相同的数据按照过车时间由小到大的顺序排列。
2、遍历上述排序之后的数据,若有两条相邻数据车辆编号相同,且依次经过卡口编号为“340300100534”的卡口和卡口编号为“340300100035”的卡口,且两条数据的过车时间差值小于时间差阈值δts,则计算这两条数据之间的过车时间差值,则路段流量值增加1,由此便可求得5分钟内的路段流量qs,本例中qs=54。同时也可求得满足上述条件的相邻两条数据之间的速度值ui,最终将所得的速度值求其平均值即为5分钟内路段的平均速度va,本例中求得va=7.66m/s。
3、计算此5分钟内的路段负荷裕度,由于所选取的需判断其交通状态的时段s=5min,与计算历史数据时所选的时间周期t相等,故无需进行时段的转化。有路段负荷裕度计算公式得:
4、计算此5分钟内的路段畅通率,带入路段畅通率计算公式得:
步骤三、交通状态等级判断
1、由步骤二计算所得的路段负荷裕度m和路段畅通率o可构成二位空间中的点(m,o),计算此点与4个聚类中心点之间的欧式距离,计算公式如下:
其中mh和oh分别表示第h个聚类中心点的路段负荷裕度和路段畅通率。将计算所得的各个欧式距离写入集合d={d1,d2,…,dk}={0.200,0.162,0.352,0.238}。
2、求所求的5分钟的交通状态对所划分的4中交通状态的隶属程度,计算公式如下:
其中式中pi表示所提取的5分钟时段内的数据属于第i个路段交通状态等级的隶属程度;di表示(m,o)与第i个聚类中心点的欧式距离。将计算所得的隶属度pi写入集合p={p1,p2,…,pk}={0.274,0.339,0.156,0.231},由于本例中的隶属程度表示所求的5分钟的数据属于4中交通状态的程度的大小,且集合p中的最大值pm=p2=0.339,故所检测数据路段交通状态等级为第2级,为基本畅通状态。
- 还没有人留言评论。精彩留言会获得点赞!