一种基于车牌相似度的车牌纠错方法与流程
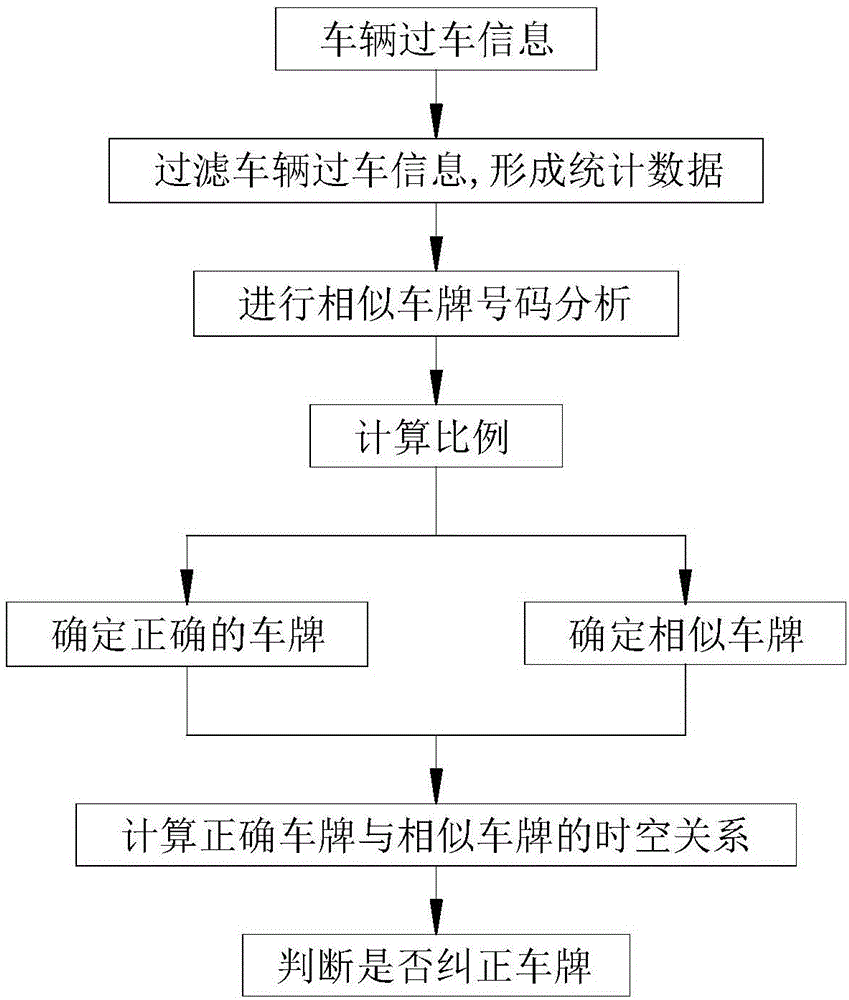
本发明属于平安城市、智慧城市项目智能交通
技术领域:
,具体一种基于车牌相似度的车牌纠错方法。
背景技术:
:众所周知,车辆的车牌号码是车辆的“唯一身份”标识。车牌识别技术可以在车辆不作任何改动的情况下实现汽车身份的自动登记及验证,这项技术已经应用于公路收费、停车管理、称重系统、交通诱导、交通执法、公路稽查、车辆调度、车辆检测等各种场合中。而在目前平安城市、智慧城市的建设中,车牌识别更成为了建设的重中之重。传统的车牌识别是通过通过车牌提取、图像预处理、特征提取、车牌字符识别等技术,从而起到识别车辆牌号和颜色等信息的目的。然而,车牌识别的识别率至今也不敢说有百分百完美识别,其原因就在于其识别率受多种因素影响:比如卡口相机的拍摄角度、行车速度、外界环境光、遮挡、车牌污损等,从而造成车牌号码识别错误的状况,显然现今车牌识别系统仍有较多的提升空间。技术实现要素:本发明的目的是克服上述现有技术的不足,提供一种基于车牌相似度的车牌纠错方法;本发明旨在尽可能的降低车牌识别错误现象,并进一步的起到纠正识别错误的过车信息的目的,从而提高过车数据的准确度,更可结合目前车牌识别系统从而有效的提升目前车牌识别的识别率,最终提高用户的使用及体验。为实现上述目的,本发明采用了以下技术方案:一种基于车牌相似度的车牌纠错方法,其特征在于包括以下步骤:1)、从数据源处获取各车辆的过车信息,滤除不符合车牌命名规则的车牌,将剩下的每个车牌号码所对应的车辆过车信息加以记录,形成统计数据;统计数据内所记录的车辆过车信息至少包括该车辆的车牌号码、过车时间以及过车卡口经纬度;2)、通过以下相似字符规则表,进行相似车牌号码分析:相似字符1-j2-z4-a5-s7-t8-b在进行相似车牌号码分析时,将两个需对比的车牌号码的各位数一一比对,并设定比对阈值;当两个需比对的车牌号码的位数错误不超过该对比阈值时,将该两个号码作为相似车牌号码,反之则不作为相似车牌号码;当相似车牌号码分析结束后,将分析所得的相似车牌号码共同存储到同一组相似车牌集合中,作为车牌纠正数据分析的数据基础;循环获取上述相似车牌号码并逐条存储;3)、在步骤2)形成相似车牌集合后,统计同一组相似车牌集合内各个车牌号码的对应的数量,并进行各个车牌号码所对应数量的比例比对;当同一组相似车牌集合内,某一条车牌号码的数量大于其他车牌号码数量时,以该车牌号码为识别正确的车牌,其他车牌号码为识别错误的车牌;当同一组相似车牌集合内,各条车牌号码的数量均等,则不加以判断;之后执行步骤4);4)、以步骤3)中所获得的识别正确的车牌号码为基础,并调取步骤1)中的车辆过车信息;首先通过提取车辆过车信息的过车时间点,从而计算上述正确车牌与同一组相似车牌集合内各个相似车牌的过车时间差δt;再通过提取过车卡口经纬度,计算得出上述正确车牌与同一组相似车牌集合内各个相似车牌的所在过车卡口之间的距离δs;最后,根据上述过车时间差δt以及过车卡口之间的距离δs,计算满足上述过车时间差下的车辆从其中一个卡口至另一个卡口所需速度v;5)、设定车辆最大行驶速度阈值vmax,当v≤vmax时,可认定步骤4)中所比对的两车牌号码属于同一车辆,即可将对应相似车牌纠正为步骤3)中的正确车牌;当v>vmax时,可认定步骤4)中所比对的两车牌号码不属于同一车辆,不予纠正。优选的,所述步骤1)中,统计数据以json对象的形式进行存储。优选的,所述步骤1)中,车辆过车信息还包括车辆号码所对应车辆的过车卡口名称以及过车卡口编号。优选的,所述步骤2)中,对比阈值为2,也即当两个需比对的车牌号码的位数错误不超过2个时,才将该两个号码作为相似车牌进行存储。本发明的有益效果在于:1)、本发明可在基于目前各种车牌识别算法的结论基础上,进一步的提升车牌识别的准确率。具体操作时,在传统车牌识别系统初步识别车牌号码后,通过本发明来创建相似车牌模型库,即可进行实时而准确的的分析纠正车牌操作,最终极大的降低传统车牌识别系统的误差率,甚至可使其识别准确率逼近百分百。由于本发明完全是基于现有车牌识别算法之外而独立存在,并可依附于现有车牌识别算法,因此即使前段车牌识别技术算法产生识别错误,也能依靠本发明的在线纠正而确保其识别结果的准确性,也即即使降低前段基于视频图像识别技术算法的研发成本也不会影响最终过车数据的准确性,使用成效显著。通过上述方法,本发明通过对整个数据集按照车牌号进行聚类分析,即按照车牌号分组,车牌号相同或相似的放在一组,再以先比例判断再空间关系判断的双重筛选方式,最终达到车牌在线纠正的目的,从而可极大地降低现有车牌识别技术的研发投入,避免了巨大的重复性的计算工序下的车牌识别误差性。本发明为车辆技战法分析的数据源提供了更加准确的数据,更能依附于现有任意车牌识别分析技术并提高其分析结果的精确性,大数据可视化结果可得到有效提升,用户体验感可得到充分保证。附图说明图1为本发明的流程示意框图。具体实施方式为便于理解,此处结合图1,对本发明的具体流程及工作方式作以下进一步描述:本发明的工作流程参照图1所示,主要包括以下步骤:s1、从数据源中下载车辆过车信息,过滤不符合车牌命名规则的车牌,将剩下的每个车牌号码所对应的车辆过车信息加以记录,形成统计数据;统计数据内所记录的车辆过车信息应当包括该车辆的车牌号码、过车时间、过车卡口经纬度、过车卡口名称以及过车卡口编号。s2、以车牌号码分析相似车牌,将相似车牌记录在一个列表或者数组中,也即同一组相似车牌集合中,作为一类车牌进行统计分析。s3、分析相似车牌后的结果,通过统计车牌数量,进行比例分析;对比例分析中比例较大的车牌作为识别正确的车牌,而比例较小的作为识别错误的车牌。s4、以正确车牌的过车信息为依据,计算每个正确车牌与每个相似车牌之间的过车时间差,再根据两个车牌过车卡口的经纬度计算过车卡口之间的距离。s5、根据两个车牌过车时间差以及过车卡口之间的距离计算其速度。s6、根据时空关系设定其车辆最大行驶速度阈值,当s5步骤中计算得出的速度小于或等于车辆最大行驶速度阈值时,认定该相似车牌应当是识别错误,予以纠正。反之,则认定其为其他车牌。具体而言,s1步骤中,根据过车数据先过滤不符合车牌命名规则的数据,将过滤后的车牌,按照一定规则进行存储,如以json对象的形式进行存储,记录过车数据的车牌号码、车辆过车时间、车辆过车卡口名称、车辆过车卡口编号、车辆过车卡口经纬度等信息。所述的不符合车牌命名规则,比如说目前安徽省车牌命名规则为:合肥市:皖a、芜湖市:皖b、蚌埠市:皖c、淮南市:皖d、马鞍山市:皖e、淮北市:皖f、铜陵市:皖g、安庆市:皖h、黄山市:皖j、阜阳市:皖k、宿州市:皖l、滁州市:皖m、六安市:皖n、宣城市:皖p、巢湖市:皖q、池州市:皖r、亳州市:皖s。此时,如若所提取出的车辆过车信息中,其车牌前两位为皖z,显然z不是上述车牌命名规则内的字母,因此需要加以滤除,以此类推。对上述不符合既定规则的数据加以滤除后,将过滤后的每个车牌号码所对应的车辆过车信息加以记录,形成统计数据。在s2步骤中,需对上述过滤后的车牌进行相似度分析,两个车牌之间最多只允许两个字符错误,也即其对比阈值为2。由于字符不包含汉字,因此即使第一位的汉字不相同,其他的位数满足上述对比阈值也会记为相似车牌。举例而言,如其中一个车牌号码为皖a15751,而另一个车牌号码为浙aj575j中由于1和j不同,并满足字符的错误位数不超过两位的要求,因此为相似车牌。而如另一个车牌号码为皖aj5t5j时,则因为字符的错误位数超过了两位而达到了三位,则不是相似车牌。以下表规定相似字符:相似字符1-j2-z4-a5-s7-t8-b上表作为相似字符表,其为现有进行车牌相似度计算时所必然需要用到的常规表格,也是业内公认的易于被机器判定错误的相似字符。举例而言,1和j易于被系统所误判,2与z,4与a,5与s,7与t,8与b均同样。当车牌相似分析结束后,将相似车牌存储到一组相似车牌集合中,作为车牌纠正数据分析数据基础,循环获取此数据。同一组相似车牌集合所存储的数据中,记载着每个相似车牌的所有过车记录,如每个相似车牌的过车总条数、过车数据的车牌号码、车辆过车时间、车辆过车卡口名称、车辆过车卡口编号、车辆过车卡口经纬度等信息。s3步骤需进行比例分析,也即在对相似车牌进行集中放置后,也即将整组相似车牌集合视作为桶,而将所有相似车牌作为木签而丢入同一个桶内。此时,桶内是装有所有相似车牌的。这时,就需要统计所有相似车牌的数量,当其中a车牌明显数量极多时,则可将桶内其他的相似车牌的号码全部置换为该a车牌。举例而言,当同一组相似车牌集合记录了十份车牌,其中皖a82431数量为五个,而皖abz431为三条,浙abz431为两条,则因为皖a82431比例最多,因此统一将集合内的所有车牌全部修正为皖a82431。而若同一组相似车牌集合记录了十份车牌,其中皖a82431数量为五个,而皖abz431为五条,则因为两者比例一致,不作判断,将此组集合过滤,继续执行下一组相似车牌集合。在s4-s6步骤中,以s3步骤中获取的相对的正确车牌作参考值,而将其他的相似车牌作为疑似识别错误的车牌。首先通过提取车辆过车信息的过车时间点,从而计算上述正确车牌与同一组相似车牌集合内各个相似车牌也即疑似识别错误的车牌的过车时间差δt;再通过提取过车卡口经纬度,计算得出上述正确车牌与同一组相似车牌集合内各个疑似识别错误的车牌的所在过车卡口之间的距离δs;最后,根据上述过车时间差δt以及过车卡口之间的距离δs,计算满足上述过车时间差下的车辆从其中一个卡口至另一个卡口所需速度v。同时,根据现实中的交通规则,结合大数据统计,从而设定车辆最大行驶速度阈值vmax。当v≤vmax时,可认定所比对的两车牌号码属于同一车辆,即可将对应相似车牌纠正为正确车牌;当v>vmax时,可认定所比对的两车牌号码不属于同一车辆,不予纠正。举例而言,以合肥市区普通路段为例,其车辆交通规则中的行驶速度基本为40-80km/h,而最多不会超过120km/h。此时,根据现实中的交通规则,结合大数据统计,从而将车辆最大行驶速度阈值vmax设定为120km/h,若计算的速度值大于120km/h,则显然在正常的物理规则上不可能存在市区普通路段跑120km/h的车辆,则判定该两个对比的车辆并不是同一车辆,车牌号码也不是同一车牌号码,其疑似识别错误车牌确实是判断错误,可将计算结果终止,进行下一条相似车牌的纠正。反之,若计算的速度值小于或等于120km/h,符合了空间物理规则,因为确实有可能同一车辆以速度值小于或等于120km/h从a点跑到b点,则判定此疑似识别错误车牌为初始识别错误,此时将其车牌号码纠正为s3步骤中获取的正确车牌,从而达到相似车牌纠正目的。综上所述,本发明可极大地降低现有车牌识别技术的研发投入,避免了巨大的重复性的计算工序下的车牌识别误差性,为车辆技战法分析的数据源提供了更加准确的数据,更能依附于现有任意车牌识别分析技术并提高其分析结果的精确性,大数据可视化结果可得到有效提升,用户体验感更好,使用成效显著。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1