基于KPCA-FOA-LSSVM的滑坡灾害预报方法与流程
本发明属于地质灾害监测技术领域,涉及一种基于kpca-foa-lssvm的滑坡灾害预报方法。
背景技术:
滑坡是一种常见的自然灾害现象,它的出现能够使农田与房舍被摧毁、破坏道路与水利水电设施,从而导致停电、停水、停工等后果,严重时还可能威胁到人类的生命安全。因此,如何采取及时而准确的滑坡灾害预报方法成为人们所关注的热点。
针对滑坡发生的随机性、高频率、影响范围广等特点,国内外学者对其进行了深入的研究,但使用的方法各有利弊。例如灰色模型,无需大量训练样本且计算工作量小,但由于其内在机理复杂,难以分析,导致准确率不够稳定;神经网络模型具有较好的自主学习与容错能力,但其收敛速度较慢,时间过长容易陷入局部极值;朴素贝叶斯判别模型,对于多分类问题处理效果好,但在分析较为复杂的样本时误判率会上升;支持向量机(svm)模型,具有良好的泛化能力,在训练样本时易于寻求全局最优解,但缺点是其训练机理为一个有约束的二次规划问题,在样本容量大时,可能导致训练时间过长,效率低下。而最小二乘支持向量机(lssvm)的出现,改变了标准svm的约束条件与风险函数,在继承支持向量机优点的同时,还能够很好地解决数据量少、过学习以及高维数等实际问题,提升了训练效率与准确性,在预测预报领域中体现出较大优势。
鉴于此,本发明提出一种基于kpca-foa-lssvm的滑坡灾害预报方法,首先运用核主成分分析法(kernelprincipalcomponentsanalysis,kpca)筛选出研究区滑坡发生主要影响因素,将标准化处理后的数据输入于最小二乘支持向量机(leastsquaresupportvectormachines,lssvm)滑坡预测模型中进行运算,然后利用果蝇优化算法(fruitflyoptimizationalgorithm,foa)参数优化,更新网络参数,最后输出滑坡发生概率对应发生等级完成滑坡预报。
技术实现要素:
本发明的目的是提供一种基于kpca-foa-lssvm的滑坡灾害预报方法,解决现有灾害预报方法采用的算法过学习、效率低、精确度不高的问题。
本发明所采用的技术方案是,基于kpca-foa-lssvm的滑坡灾害预报方法,具体过程包括如下步骤:
步骤1.建立滑坡体实时监测预警系统,获取监测区滑坡的实时数据,将其标准化处理后,运用核主成分分析法筛选出滑坡发生主要影响因素作为输入变量;
步骤2.构建基于最小二乘支持向量机滑坡灾害预报模型;
步骤3.运用果蝇算法进行参数寻优,更新网络参数;
步骤4.根据步骤3优化的结果,重构滑坡灾害预报模型,输出滑坡发生概率对应的发生等级,实现滑坡灾害的实时监测。
本发明的其他特点还在于,
步骤1中获取监测区滑坡的实时数据,将其标准化处理后,运用核主成分分析法筛选出滑坡发生主要影响因素作为输入变量的具体过程如下:
步骤1.1分析不同的监测区存在不同的滑坡灾害影响因素,根据地质环境背景与历史灾害发生记载情况,确定初始影响因素为:降雨量、土壤含水率、裂缝位移值、孔隙水压力、次声频率、坡向、坡度、高程、平面曲率、地层振动指数、归一化植被系数和岩组工12个影响因素;将滑坡体监测预警系统采集的实时数据作为原始数据集;
步骤1.2将步骤1.1获取的原始数据标准化处理,如公式1所示:
其中,x为标准化后的值,xoriginal为输入的实际值,xmin和xmax分别为所有输入值中的最小值和所有输入值中的最大值;
步骤1.3采用核主成分分析法筛选出滑坡发生的主要影响因素,具体过程如下:
设训练样本集为x={x1,x2,…xn},其中xi∈rp,yi=rp(rp为输入空间,p为数据维数,i=1,…n,n为训练样本总数),输入空间非线性映射
其中,c为协方差矩阵,n为训练样本数,
对协方差矩阵c进行特征分解,如式3所示:
λνi=cλ(3)
其中,λ≥0,且特征向量如式4所示:
由于特征向量ν是由非线性映射空间组成,因此,式3与式5等价:
将式2、式4代入式5中,且令
kαn=nλiαn(6)
其中,核矩阵的特征向量为α1,α2…αn,特征值为nλi;
选取前m(m<n)个特征值对应的归一化特征向量α1,α2…αm,其中
其中,j=1,2…,n;r=1,2,…,m;gr(xj)为对应于
令所有投影值g(xj)=(g1(xj),g2(xj)…gm(xj))作为样本特征值,利用核函数
根据μj贡献率选取主要成分tj,如公式9所示:
其中,i为主元成分个数,μi为主成分贡献率,λi为第i个特征值,
式9中取累计方差贡献率μj≥85%作为主要滑坡灾害影响因子数据,因此,筛选出的主要灾害影响因素为:x1=降雨量,x2=土壤含水率,x3=裂缝位移量,x4=孔隙水压力,x5=次声频率,x6=岩组,x7=归一化植被系数。
步骤2中构建基于最小二乘支持向量机的具体过程如下:
步骤2.1将步骤1中筛选出的7个主要影响因素作为模型输入部分,设其中共有k个样本,将样本设置为8:1的分配比例,分别为训练样本和测试样本;且将模型输出设置为一个5维向量,其输出量为:y1=成灾概率0~20%,y2=成灾概率20~40%,y3=成灾概率40~60%,y4=成灾概率60~80%,y5=成灾概率80~100%,且各分量的值分别为1或-1;
步骤2.2构建基于最小二乘支持向量机的滑坡灾害预报模型:
对于步骤2.1中给定的样本作非线性映射φ:rn→f,设定训练样本集(xi,yi),i=1,…,k,k为样本总数;xi∈rn,yi∈r,rn为输入空间,n为数据维数;
因此,被估计函数表达式如式10所示:
y=f(x)=wtφ(x)+b(10)
其中,w和b均为结构风险化最小化模型参数,且w代表空间f的权向量,b∈r代表为偏差量;f(x)为被估计函数;
在确定决策参数w、b时,求解问题如式11所示:
其中,ξk∈r为误差变量,γ为可调超参数;
由式11定义拉格朗日函数形式如式12所示:
其中,αk∈r为拉格朗日乘子;
对式12中的各变量求偏导并整理为线性方程组,得到式13:
其中,il=[1,1,…,1];ωij=k(xi,xj)=φ(xi)tφ(xj),k(xi,xj)为核函数;α=[α1,α2…αl],i,j=1,2,…l;
在此,核函数选择rbf高斯径向基核函数,其表达式如式14所示:
由式13中得出最小二乘支持向量机的函数估计如式15所示:
其中,不为零的元素αi所对应的样本(xi,yi)为支持向量;
由式13和式15得到第m等级的分类功能如式16所示:
其中,如果分类结果属于第m类(m=1,2,3,4,5),则ymi=1,否则ymi=-1;fm(x)为分类出的第m个等级;
如果对应的各类的分类函数,即公式16的输出结果是1,则属于该等级;如果输出结果是-1,则不属于该等级。
步骤3中运用果蝇算法进行参数寻优,更新网络参数的具体过程如下:
步骤3.1初始化果蝇算法参数,包括种群规模、迭代次数以及果蝇初始位置,针对最小二乘支持向量机模型中需要优化的两个参数:可调超参数γ和核参数σ,选取样本中随机的两个数,令初始坐标分别为
步骤3.2赋予每只果蝇随机距离和随机方向,定义坐标为
步骤3.3确定需要优化的参数范围
步骤3.4将步骤1.3中已经归一化理过的训练样本作为训练样本,令分类准确率作为适应度函数如式17所示:
smelli=fitness(ci,σi)=accuracy(ci,σi)(17)
其中,smelli代表果蝇个体位置的味道浓度;
寻找fitness的最大值对应分类精确值最大的果蝇个体,进入迭代寻优,判断最高分类精确值是否由于前一代,若高于,则保留精确最大值以及对应的坐标值,并更新初始坐标
本发明的有益效果是,基于kpca-foa-lssvm的滑坡灾害预报方法,解决现有灾害预报方法采用的算法过学习、效率低、精确度不高的问题。相比于现有方法具有以下优势:
(1)建立滑坡体监测预警系统,实时采集数据,保证时效性;通过kpca方法筛选滑坡发生主要影响因素,削弱次要因素,并且避免了特征向量线性不可分问题,防止维数灾难。
(2)利用lssvm模型对灾害影响因素样本特征学习,构造最优决策函数,简化计算方法,提升预报效率;
(3)利用果蝇算法进行全局优化,保证网络整体最优,提升预报精确度。
附图说明
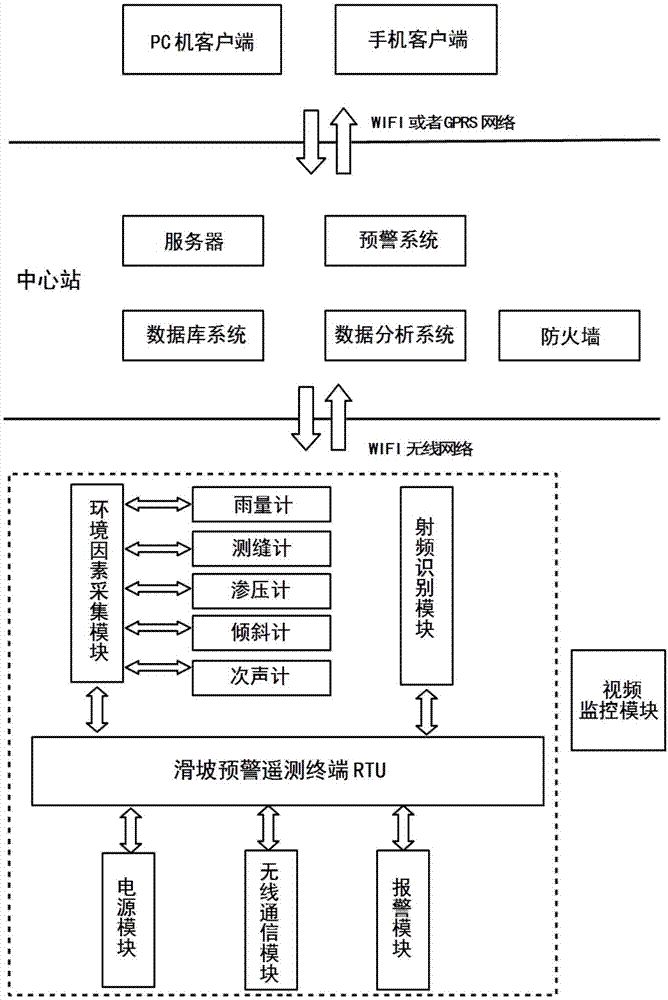
图1是本发明的基于kpca-foa-lssvm的滑坡灾害预报方法所使用的滑坡灾害实时监测预警系统结构示意图;
图2是本发明的基于kpca-foa-lssvm的滑坡灾害预报方法的流程图;
图3是最小二乘支持向量机体系图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明的滑坡灾害实时监测装置如图1所示,包括设置在监测区域的环境因子采集模块,环境因子采集模块将采集的数据传输给滑坡预警遥测终端(rtu),滑坡预警遥测终端设置在监测区的坡体上,滑坡遥测终端的内部设置有电源模块、无线通信模块和报警模块,滑坡遥测终端的外部安装有门禁锁装置,门禁锁为非接触式ic一卡通,采用射频识别技术使得管理员通过一卡通出入滑坡遥测终端;滑坡预警遥测终端通过内部的无线通信模块将环境因素采集模块采集的数据传送到中心站,中心站将收集的数据导入相应预报模型中进行处理并判断预警结果,通过无线通信的方式上传至客户端。
环境因子采集模块包括设置在监测区域坡体上的雨量计、测缝计、渗压计、倾斜计和次声计。雨量计用于获取监测坡体区域内一段时间的累计降雨量;测缝计用于测量坡体的伸缩缝或裂缝变化的位移量;渗压计用于实时监测地质区域内土体所承受的压力值;倾斜计用于实时测量坡体发生倾斜角度的变化量;次声计用于获取坡体固体颗粒之间碰撞产生次声波的变化量。
中心站包括服务器、预警系统、数据库系统、数据分析系统和防火墙,数据库系统用于储存滑坡预警遥测终端传送的实时数据,数据库系统将存储的数据传送到数据分析系统,数据分析系统将数据进行判断分析后发送到服务器进行计算,预警系统的作用是将预警信息上报至客户端,防火墙的是实现数据保密与完整性的重要方式,对访问控制数据的安全性管理提供保证。
电源模块采用锂电池和太阳能光伏发电板供电。当光照充足时,太阳能光伏发电板为整个系统供电;当光照不足或光伏发电板提供的直流电压小于12v时,选取备用的12v锂电池为整个系统供电。电源模块为滑坡预警遥测终端提供电源能力,保证其能够实时监测。
无线通信模块采用无线wifi网络,负责将滑坡预警遥测终端的监测的实时数据上传到中心站,和接收中心站下发的命令进行无线传输。
报警模块采用爆闪灯,当中心站根据得到的滑坡实时数据处理后的结果,若结果表示为警情,中心站自动下发报警信号给滑坡预警遥测终端的报警模块和客户端,现场爆闪灯闪烁进行报警提示。
滑坡灾害实时监测装置还包括设置在坡体现场的视频监控模块,负责监控坡体现场实时的状况以及安全防盗,视频监控模块通过无线wifi将视频数据上传至中心站。
客户端是pc机客户端或者手机客户端,管理者通过在pcj机或手机上登录其帐号,能够观测滑坡预警遥测终端采集到的数据量以及中心站处理发出的预警结果。同时,管理者能够通过pc机客户端或手机客户端下达指令控制滑坡预警遥测终端的开启与关闭。
本发明的基于kpca-foa-lssvm的滑坡灾害预报方法,如图2所示,具体过程包括如下步骤:
步骤1.建立滑坡体实时监测预警系统,获取监测区滑坡的实时数据,将其标准化处理后,运用核主成分分析法筛选出滑坡发生主要影响因素作为输入变量;
步骤2.构建基于最小二乘支持向量机滑坡灾害预报模型;
步骤3.运用果蝇算法进行参数寻优,更新网络参数;
步骤4.根据步骤3优化的结果,重构滑坡灾害预报模型,输出滑坡发生概率对应的发生等级,实现滑坡灾害的实时监测。
步骤1中获取监测区滑坡的实时数据,将其标准化处理后,运用核主成分分析法筛选出滑坡发生主要影响因素作为输入变量的具体过程如下:
步骤1.1分析不同的监测区存在不同的滑坡灾害影响因素,根据地质环境背景与历史灾害发生记载情况,确定初始影响因素为:降雨量、土壤含水率、裂缝位移值、孔隙水压力、次声频率、坡向、坡度、高程、平面曲率、地层振动指数、归一化植被系数和岩组工12个影响因素;将滑坡体监测预警系统采集的实时数据作为原始数据集;
步骤1.2将步骤1.1获取的原始数据标准化处理,如公式1所示:
其中,x为标准化后的值,xoriginal为输入的实际值,xmin和xmax分别为所有输入值中的最小值和所有输入值中的最大值;
步骤1.3采用核主成分分析法筛选出滑坡发生的主要影响因素,具体过程如下:
设训练样本集为x={x1,x2,…xn},其中xi∈rp,yi=rp(rp为输入空间,p为数据维数,i=1,…n,n为训练样本总数),输入空间非线性映射
其中,c为协方差矩阵,n为训练样本数,
对协方差矩阵c进行特征分解,如式3所示:
λνi=cλ(3)
其中,λ≥0,且特征向量如式4所示:
由于特征向量ν是由非线性映射空间组成,因此,式3与式5等价:
将式2、式4代入式5中,且令
kαn=nλiαn(6)
其中,核矩阵的特征向量为α1,α2…αn,特征值为nλi;
选取前m(m<n)个特征值对应的归一化特征向量α1,α2…αm,其中
其中,j=1,2…,n;r=1,2,…,m;gr(xj)为对应于
令所有投影值g(xj)=(g1(xj),g2(xj)…gm(xj))作为样本特征值,利用核函数
根据μj贡献率选取主要成分tj,如公式9所示:
其中,i为主元成分个数,μi为主成分贡献率,λi为第i个特征值,
式9中取累计方差贡献率μj≥85%作为主要滑坡灾害影响因子数据,因此,筛选出的主要灾害影响因素为:x1=降雨量,x2=土壤含水率,x3=裂缝位移量,x4=孔隙水压力,x5=次声频率,x6=岩组,x7=归一化植被系数。主要影响因素输入模式如表1所示。
如图3所示,步骤2中构建基于最小二乘支持向量机的具体过程如下:
步骤2.1将步骤1中筛选出的7个主要影响因素作为模型输入部分,设其中共有k个样本,将样本设置为8:1的分配比例,分别为训练样本和测试样本;且将模型输出设置为一个5维向量,其输出量为:y1=成灾概率0~20%,y2=成灾概率20~40%,y3=成灾概率40~60%,y4=成灾概率60~80%,y5=成灾概率80~100%,且各分量的值分别为1或-1;成灾概率与对应编码如表2所示:
步骤2.2构建基于最小二乘支持向量机的滑坡灾害预报模型:
表1主要影响输入模式
表2成灾概率及其编码
对于步骤2.1中给定的样本作非线性映射φ:rn→f,设定训练样本集(xi,yi),i=1,…,k,k为样本总数;xi∈rn,yi∈r,rn为输入空间,n为数据维数;
因此,被估计函数表达式如式10所示:
y=f(x)=wtφ(x)+b(10)
其中,w和b均为结构风险化最小化模型参数,且w代表空间f的权向量,b∈r代表为偏差量;f(x)为被估计函数;
在确定决策参数w、b时,求解问题如式11所示:
其中,ξk∈r为误差变量,γ为可调超参数;
由式11定义拉格朗日函数形式如式12所示:
其中,αk∈r为拉格朗日乘子;
对式12中的各变量求偏导并整理为线性方程组,得到式13:
其中,il=[1,1,…,1];ωij=k(xi,xj)=φ(xi)tφ(xj),k(xi,xj)为核函数;α=[α1,α2…αl],i,j=1,2,…l;
在此,核函数选择rbf高斯径向基核函数,这种核函数能够较好处理线性不可分情形,而且需要确定的参数少,无论在大样本还是小样本中均具有较好的性能,其表达式如式14所示:
由式13中得出最小二乘支持向量机的函数估计如式15所示:
其中,不为零的元素αi所对应的样本(xi,yi)为支持向量;
由式13和式15得到第m等级的分类功能如式16所示:
其中,如果分类结果属于第m类(m=1,2,3,4,5),则ymi=1,否则ymi=-1;fm(x)为分类出的第m个等级;
如果对应的各类的分类函数,即公式16的输出结果是1,则属于该等级;如果输出结果是-1,则不属于该等级。
步骤3中运用果蝇算法进行参数寻优,更新网络参数的具体过程如下:
步骤3.1初始化果蝇算法参数,包括种群规模、迭代次数以及果蝇初始位置,针对最小二乘支持向量机模型中需要优化的两个参数:可调超参数γ和核参数σ,选取样本中随机的两个数,令初始坐标分别为
步骤3.2赋予每只果蝇随机距离和随机方向,定义坐标为
步骤3.3确定需要优化的参数范围
步骤3.4将步骤1.3中已经归一化理过的训练样本作为训练样本,令分类准确率作为适应度函数如式17所示:
smelli=fitness(ci,σi)=accuracy(ci,σi)(17)
其中,smelli代表果蝇个体位置的味道浓度;
寻找fitness的最大值对应分类精确值最大的果蝇个体,进入迭代寻优,判断最高分类精确值是否由于前一代,若高于,则保留精确最大值以及对应的坐标值,并更新初始坐标
步骤4中将相对应的滑坡发生概率分为五个等级,分级情况如表3所示:
表3预警等级划分
- 还没有人留言评论。精彩留言会获得点赞!