一种多因素的短时交通流预测方法与流程
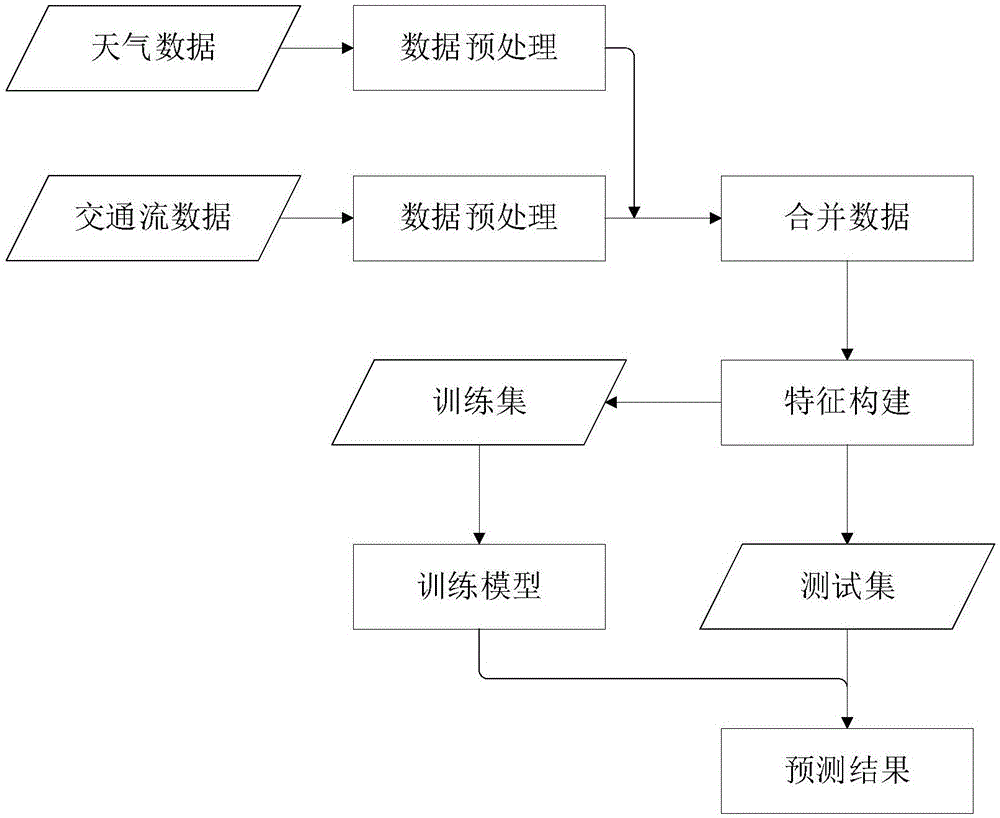
本发明涉及智能交通系统的技术领域,特别涉及一种多因素的短时交通流预测方法。
背景技术:
随着经济的不断发展,交通压力日渐增大,交通事故频发,交通环境日益恶化。如何提高道路通行能力,缓解交通拥堵,是学术界及工业界关注的焦点。智能交通系统(its,intelligenttransportsystem)将“人-路-车”紧密结合,建立起一个准确、实时、高效的交通管理系统。在its中,交通控制和实时交通流诱导尤为重要。而实现交通控制与诱导的关键就是实时准确的短时交通流预测。
短时交通流预测起步阶段是使用古典统计方法预测单点交通状况;随后求和自回归移动平均(arima,autoregressiveintegratedmovingaverage)等参数模型在一段时间内成为研究人员关注的焦点;由于交通流数据呈现出的随机性以及非线性,研究人员尝试使用非参数模型进行预测,如卡尔曼滤波法、最近邻算法、支持向量回归等,并取得一定的预测效果;但随着交通系统越来越复杂,数据规模逐渐膨胀,这些浅层模型已经逐渐不能满足预测需求。
这促使我们思考如何充分挖掘交通流数据的隐含信息,深度信念网络、堆叠自编码器等深度网络结构相继应用于短时交通流预测领域。有研究人员利用长短时记忆网络(lstm,longshorttermmemorynetworks)学习时序数据之间的关联关系,并获取长时依赖关系,但现有的方法没有充分考虑其他因素对预测结果的影响。本发明提出一种多因素的短时交通流预测方法,创新性地使用两个lstm模块分别提取交通流的时序特征与周期性特征;并构建天气、时间等特征,筛选出其中重要度高的特征;使用全连接层(fc,fullyconnectedlayer)将交通流的时序特征、周期性特征与筛选出来的多种特征进行融合,从而达到提高预测准确性的目的。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出了一种多因素的短时交通流预测方法,该方法创新性地使用两个lstm模块分别提取交通流的时序特征与周期性特征,同时与天气特征、时间特征等融合,可克服现有方法不能充分利用已有数据的缺点,从而提高交通流预测的准确性。
为实现上述目的,本发明所提供的技术方案为:一种多因素的短时交通流预测方法,包括以下步骤:
1)计算特定检测器与气象站之间的距离,筛选出距离最近的气象站,将该气象站的天气数据作为检测器的天气数据;
2)分别对检测器的历史交通流数据与历史天气数据进行预处理,再根据时间合并;其中,所述检测器的历史交通流数据为特定观测点在一段时间间隔内经过的车辆数;
3)构建多种特征,基于lightgbm进行特征筛选;
4)利用长短时记忆网络lstm对交通流数据的时序特征与周期性特征进行建模;
5)使用神经网络中的全连接网络将交通流的时序特征、周期性特征与步骤3)筛选出来的多种特征进行融合;
6)训练模型并对短时交通流进行预测。
在步骤1)中,需要根据经纬度计算检测器与不同气象站在地球表面的两点间距,选取距离检测器最近的气象站数据作为检测器天气数据,具体计算公式为:
式中,d为检测器与气象站的距离,r为地球半径,
在步骤2)中,分别对检测器的历史交通流数据与历史天气数据进行预处理,再根据时间合并的具体过程如下:
2.1)填充交通流数据缺失值,按照周一至周日将各天的交通流数据归为七类,计算每一类中一天所有时刻的平均值,用该平均值填充缺失值;
2.2)填充天气数据缺失值,使用近邻时刻天气数据填充缺失值;
2.3)对填充后的历史交通流数据进行归一化处理,提取最大交通流fmax与最小交通流fmin,使用最大最小归一化方法对历史交通流数据进行归一化处理,使得历史交通流数据映射到[0,1]的区间,归一化后的交通流数据xt定义如以下公式所示:
式中,ft为t时刻的真实交通流;
2.4)对填充后的历史天气数据初步筛选出温度、可见度、云层情况、风速、风向、降雨量和天气类型特征共七个特征;其中,对温度、风速、降雨量这些连续型特征按照步骤2.3)相同方法进行数据归一化处理,对可见度、云层情况、风向、天气类型这些离散型特征使用独热编码处理;
2.5)根据时间将历史交通流数据与历史天气数据进行合并。
在步骤3)中,构建多种特征,基于lightgbm进行特征筛选,具体过程如下:
3.1)根据历史交通流数据产生时间生成以下特征:
一小时内的第几分钟、一天内的第几小时、一周内的星期几、一月内的第几天、一年内的第几月、是否是节假日、是否是节假日前一天、是否是周末、是否是高峰期;
3.2)获取检测器前一天同一时刻与前一周同一时刻的交通流数据;
3.3)从历史天气数据中提取特征,包括是否是恶劣天气、是否是高温天气;
3.4)利用lightgbm计算所有特征的重要度,剔除重要度低的特征。
在步骤4)中,利用长短时记忆网络lstm对交通流数据的时序特征与周期性特征进行建模,具体过程如下:
4.1)利用lstm对交通流数据的时序特征进行建模,根据预设值t设定lstm的时间步,同时将交通流的长序列数据以滑动窗口的方式处理成适用于lstm的输入格式,即预测t时刻交通流时,选取t-t,t-(t-1),...,t-1时刻的交通流作为lstm输入;
4.2)利用lstm对交通流数据的周期性特征进行建模,根据预设值n设定lstm的时间步,同时将交通流的长序列数据以滑动窗口的方式处理成适用于lstm的输入格式,即预测t时刻交通流时,选取t-nm,t-(n-1)m,...,t-m时刻的交通流作为lstm输入,m为一周的数据点个数。
在步骤6)中,将预处理后的数据按照时间顺序分为两组,时间靠前的一组为训练集数据,时间靠后的一组为测试集数据;在训练集上进行训练,根据损失函数,计算模型所输出的预测值与交通流真实值的损失值,不断对模型进行迭代优化,得到最优模型;在测试集上,利用最优模型进行预测,验证模型有效性;将预测结果反归一化,得到预测值pt,公式为:
pt=yt(fmax-fmin)+fmin
式中,fmax和fmin分别为最大和最小交通流,yt为模型预测结果;
使用平均绝对百分比误差mape来验证模型的有效性,具体计算公式为:
式中,n为预测总数,pt为预测交通流,ft真实交通流。
本发明与现有技术相比,具有如下优点与有益效果:
本发明方法能够充分挖掘交通流数据的时序特征以及周期性特征,创新性地使用两个长短时记忆神经网络(lstm,longshorttermmemorynetworks)模块分别提取交通流的时序特征与周期性特征;并构建天气、时间等特征,筛选出其中重要度高的特征;使用全连接层将交通流的时序特征、周期性特征与筛选出来的多种特征进行融合,预测准确性高,鲁棒性好。
附图说明
图1是本发明方法流程框图。
图2是交通流数据填充示意图。
图3是本发明模型示意图。
具体实施方式
下面结合具体实施例和附图对本发明作进一步说明,应指出的是,所描述的实施例仅旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,本实施例所提供的多因素的短时交通流预测方法,包括以下步骤:
步骤一,计算特定检测器与气象站之间的距离,筛选出距离最近的气象站,将该气象站的天气数据作为检测器的天气数据。本实施例检测器数据来源于pems(pems,performancemeasurementsystem),pems是美国加州交通局开发的一个智能交通监控系统。pems从超过44,000个检测器采集实时数据,这些检测器覆盖了加利福利亚州绝大多数高速路网。pems检测器每隔30s采集一次交通流数据,并以不同时间长度进行聚集来为使用者提供服务,所述实施例数据采用五分钟间隔。所述实施例气象站数据来源于国家海洋和大气管理局(noaa,nationaloceanicandatmosphericadministration),noaa是隶属于美国商务部的科技部门,主要关注地球的大气和海洋变化,提供全球天气数据。其中,noaa在加利福利亚州共有138个气象站历史天气数据,计算分别计算检测器与不同气象站之间的距离,获取距离最近的气象站。具体计算公式为:
式中,d为检测器与气象站的距离,r为地球半径,
步骤二,分别对检测器的历史交通流数据与历史天气数据进行预处理,再根据时间合并,具体如下:
填充交通流数据缺失值,按照周一至周日分别将各天的交通流数据归为七类,计算每一类中一天所有时刻的平均值,用该平均值填充交通流数据中的缺失值。图2是交通流数据填充示意图,其中,加粗部分表示填充后的交通流;
填充天气数据缺失值,使用近邻时刻天气数据填充缺失值;
对填充后的历史交通流数据进行归一化处理,提取最大交通流fmax与最小交通流fmin,使用最大最小归一化方法对历史交通流数据进行归一化处理,使得历史交通流数据映射到[0,1]的区间,归一化后的交通流数据xt定义如以下公式所示:
式中,ft为t时刻的真实交通流。
对填充后的历史天气数据初步筛选出温度、可见度、云层情况、风速、风向、降雨量、天气类型等特征。可见度从1至10分为10个级别,1级可见度最低,10级最高。云层情况分为十一类,分别为:clr:00、few:01、few:02、sct:03、sct:04、bkn:05、bkn:06、bkn:07、ovc:08、vv:09、x:10,各代码的含义为clr(clearsky)、few(fewclouds)、sct(scatteredclouds)、bkn(brokenclouds)、ovc(overcast)、vv(obscuredsky)、x(partiallyobscuredsky)。对温度、风速、降雨量等连续型特征按照上述相同方法进行数据归一化处理,对可见度、云层情况、风向、天气类型等离散型特征使用独热编码处理。
步骤三,根据步骤二合并后的数据构建多种特征,利用lightgbm计算出不同特征的重要度,剔除重要度低的特征。
根据交通流数据产生时间生成以下特征:
一小时内的第几分钟、一天内的第几小时、一周内的星期几、一月内的第几天、一年内的第几月、是否是节假日、是否是节假日前一天、是否是周末、是否是高峰期。其中,高峰期的判断基于历史平均交通流,实施例中为8:00-10:00以及16:00-18:00。
交通流数据随时间变化具有周期性,获取检测器前一天同一时刻的交通流数据,和前一周同一时刻的交通流数据;
结合可见度、云层情况、天气类型判断是否是恶劣天气,为温度设置一定阈值,超过该阈值则为高温天气。
利用lightgbm计算所有特征的重要度,剔除重要度低的特征。lightgbm是微软开发的一款快速、分布式、高性能的基于决策树的梯度boosting框架,lightgbm在训练的过程中,每次从所有叶子节点找到分割增益最大的叶子节点,该叶子节点所代表的特征具有较高的重要性。计算使用某一特征进行分割的增益总和即为该特征的重要性表征。
步骤四,利用长短时记忆网络lstm对交通流数据的时序特征与周期性特征进行建模。
lstm对序列的每一个元素都执行相同的任务,输出依赖于先前的计算。考虑到交通流数据的时序关联,t-1时刻的状态连接至t时刻,对t+1时刻进行预测时,同时考虑t时刻之前所有数据的隐含信息。lstm从输入到输出的计算过程如公式所示:
遗忘门:ft=σ(wf·[ht-1,xt]+bf)
输入门:it=σ(wi·[ht-1,xt]+bi)
输出门:ot=σ(wo·[ht-1,xt]+bo)
输入单元状态:c′t=tanh(wc·[ht-1,xt]+bc)
输出单元状态:
输出:
其中,ht-1是t-1时刻输出,xt是t时刻输入,wi、wf、wo、wo是隐藏层上一时刻到当前时刻的权重矩阵,bi、bf、bo、bc分别是输入门、遗忘门、输出门和单元状态的偏置参数,σ为sigmoid函数,tanh为双曲正切函数,运算符
对交通流数据的时序特征进行建模,在实施例中,lstm的时间步设置为48,时间间隔为5分钟,则48/(60/5)=4小时,即使用前4小时内数据进行预测。将交通流的长序列数据以滑动窗口的方式处理成适用于lstm的输入格式,即,预测t时刻交通流时,选取t-48,t-47,…,t-1时刻的交通流作为lstm输入;
对交通流数据的周期性特征进行建模,在实施例中,lstm的时间步设置为12,即使用前3个月内当前时刻数据进行预测。将交通流的长序列数据以滑动窗口的方式处理成适用于lstm的输入格式,即预测t时刻交通流时,选取t-12*2016,t-11*2016,…,t-2016时刻的交通流作为lstm输入,时间间隔为5分钟,一周数据量为7*24*(60/5)=2016。
步骤五,使用神经网络中的全连接网络将交通流的时序特征、周期性特征与步骤三筛选出来的多种特征进行融合。图3是本发明模型示意图,在实施例中,最底层为经过预处理、合并后的数据源,往上分别为时序特征lstm模块,周期性特征lstm模块,多因素特征模块,再将输出结果连接至全连接网络进行预测。
步骤六,将预处理后的数据按照时间顺序分为两组,时间靠前的一组为训练集数据,时间靠后的一组为测试集数据。在训练集上进行训练,根据损失函数,计算模型所输出的预测值与交通流真实值的损失值,不断对模型进行迭代优化,得到最优模型。在测试集上,利用最优模型进行预测,验证模型有效性。将预测结果反归一化,得到预测值pt,公式为:
pt=yt(fmax-fmin)+fmin
其中,fmax和fmin分别为最大和最小交通流,yt为模型预测结果。
使用平均绝对百分比误差(mape,meanabsolutepercentageerror)来验证模型的有效性,具体计算公式为:
其中,n为预测总数,pt为预测交通流,ft真实交通流。
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!