一种基于麦克风阵列的机动车鸣笛声监测方法与流程
本发明属于声信号检测技术领域,特别是一种基于麦克风阵列的机动车鸣笛声监测方法。
背景技术:
随着机动车保有量逐年增加,在给人们创造了巨大便利的同时,也加剧了城市道路交通噪声污染。据统计,交通噪声约占城市噪声的70%,而机动车鸣笛是交通噪声的主要来源。
近年来,国家紧抓违法鸣笛行为,基于麦克风阵列的违法鸣笛声的检测、定位是研究热点,然而重点禁鸣区域通常是违法鸣笛行为集中的十字路口、学校路段、医院附近、机关周边路段,这些区域一般较为嘈杂,声音种类复杂,包含汽车发动机、人员通行、交谈、嬉戏吵闹等声音,这些背景噪声均会影响到鸣笛声检测准确度,降低系统可靠性。近年来已有学者提出基于麦克风阵列的机动车鸣笛声定位方法(沈松,应明,刘浪,等.用于实时定位鸣笛的机动车的方法及系统:中国,201610971895.2[p].2016-10-28;张焕强,黄时春,蒋伟康.基于传声器阵列的汽车鸣笛声定位算法及实现[j].噪声与振动控制,2018,38(3):10-14.),但是这些研究未考虑背景噪声对机动车鸣笛声检测的不利影响,不适用于低信噪比环境。由此可知,在嘈杂的禁鸣区域内,如何降低背景噪声带来的影响、准确检测机动车鸣笛声十分必要。
由此可知,现有技术存在方法不全面、功能单一等缺陷。
技术实现要素:
本发明所要解决的技术问题在于提供一种计算量小、有效降低禁鸣区域嘈杂背景噪声带来的影响、提升机动车鸣笛声的声学检测准确性的基于麦克风阵列的机动车鸣笛声监测方法。
实现本发明目的的技术解决方案为:一种基于麦克风阵列的机动车鸣笛声监测方法,包括以下步骤:
步骤1、基于麦克风阵列采集多通道交通音频信号,并对其进行预处理;
步骤2、利用步骤1预处理后的多通道交通音频信号进行自适应声源方向估计,并根据声源方向估计结果进行声源筛选,筛选出若干潜在机动车鸣笛声帧;
步骤3、对步骤2获得的所有潜在机动车鸣笛声帧进行自适应增强;
步骤4、对步骤3增强后的潜在机动车鸣笛声帧进行合并,获得潜在机动车鸣笛声片段,之后提取该片段的特征参数,构建潜在机动车鸣笛声片段特征集,并结合机器学习中的识别算法完成机动车鸣笛声的声学监测。
本发明与现有技术相比,其显著优点为:1)本发明中采用多元麦克风阵列采集连续交通音频信号,采集的数据中包含了丰富的时间和空间信息,可实现在大时空尺度上对机动车鸣笛声的监测;2)本发明通过机动车鸣笛声自适应增强方法,有效提高机动车鸣笛声的信噪比,进而提高机动车鸣笛声的声学检测准确性;3)本发明通过提取小波包的特征,能够有效区分机动车鸣笛声与大量交通干扰信号;4)本发明的方法计算过程便捷,易于实施,灵活性高。
下面结合附图对本发明作进一步详细描述。
附图说明
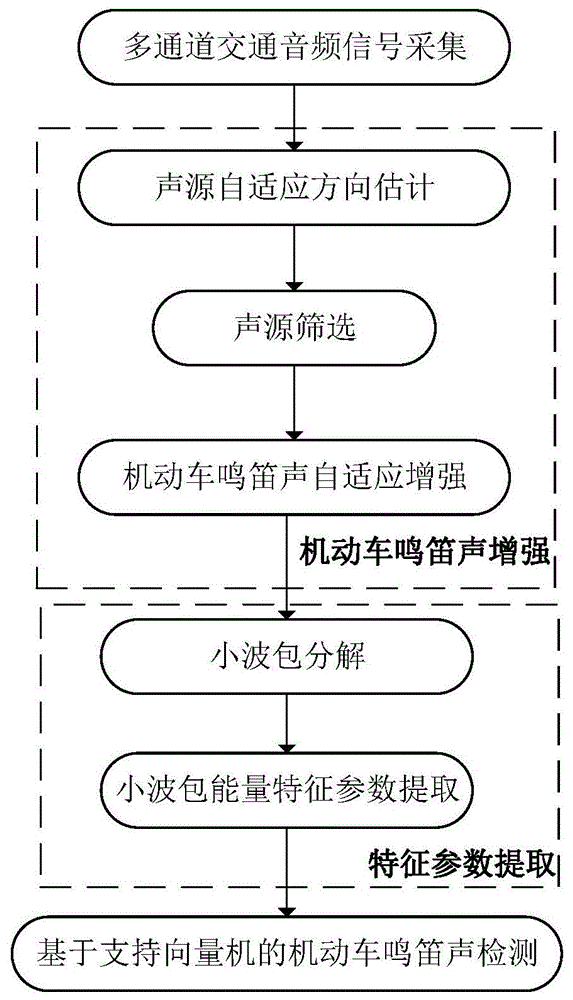
图1为本发明基于麦克风平面阵列的机动车鸣笛声增强方法的流程图。
图2为本发明实施例中四元平面麦克风阵列示意图。
图3为本发明实施例中采集的单通道交通音频信号示意图。
具体实施方式
结合图1,本发明一种基于麦克风阵列的机动车鸣笛声监测方法,包括以下步骤:
步骤1、利用麦克风阵列采集多通道交通音频信号,并对其进行预处理;
步骤2、利用步骤1预处理后的多通道交通音频信号进行自适应声源方向估计,并根据声源方向估计结果进行声源筛选,筛选出若干潜在机动车鸣笛声帧;
步骤3、对步骤2获得的所有潜在机动车鸣笛声帧进行自适应增强;
步骤4、对步骤3增强后的潜在机动车鸣笛声帧进行合并,获得潜在机动车鸣笛声片段,之后提取该片段的特征参数,构建潜在机动车鸣笛声片段特征集,并结合机器学习中的识别算法完成机动车鸣笛声的声学监测。
进一步地,步骤1中麦克风阵列采用平面麦克风阵列,其包括m个阵元,对m元平面麦克风阵列通道以一定的顺序依次编号为1,2,3….,m。
进一步地,步骤1对多通道交通音频信号进行预处理,具体为:
步骤1-1、对多通道交通音频信号进行预加重处理,以补偿高频信号的过大衰减,同时抑制低频噪声;
步骤1-2、对预加重处理后的多通道交通音频信号进行分帧,帧长为lf,其中某一数据帧对应的m个通道信号分别为x1(n)、x2(n)、x3(n)、...、xm(n),n=1,2,3,......,lf。
进一步地,步骤2中利用步骤1预处理后的多通道交通音频信号进行自适应声源方向估计,并根据声源方向估计结果进行声源筛选,筛选出潜在机动车鸣笛声数据帧,具体为:
步骤2-1、将m元平面麦克风阵列中的某一个通道作为主通道,其余通道作为辅助通道;利用块自适应方法获取每个辅助通道接收信号相对于主通道的时延;具体为:
假设通道1为主通道;
步骤2-1-1、针对每个数据帧的m通道信号,构造辅助通道c的快拍xkc:
xkc=[xc(k),xc(k+1),......,xc(k+l-1)]t
式中,2≤c≤m,k表示第k个快拍,且k=1,2,......,lf-l+1,l表示滤波器长度,t表示矢量转置;
步骤2-1-2、求取自相关矩阵rxx,所用公式为:
式中,k=lf-l+1为快拍数量;
步骤2-1-3、求取互相关矩阵rxd,所用公式为:
式中,
步骤2-1-4、求取权矢量wc1,所用公式为:
步骤2-1-5、对步骤2-1-4获得的权矢量wc1进行峰值检测,将最大峰值的横坐标记为zc,则辅助通道c接收信号相对于主通道的时延τc1为:
τc1=zc-d;
步骤2-2、判断步骤2-1-4获得的每一数据帧对应的所有权矢量wc1的主瓣与峰值旁瓣比,若均大于设定阈值,则认为当前数据帧为潜在机动车鸣笛声帧。
进一步地,步骤3中对步骤2获得的所有潜在机动车鸣笛声帧进行自适应增强,具体为:
采用广义旁瓣对消器对潜在机动车鸣笛声帧进行自适应增强,包括以下步骤:
步骤3-1、对辅助通道信号进行时延补偿,并基于时延补偿后的辅助通道信号获取和、差两个通道信号;具体为:
和通道信号为将主通道信号与时延补偿后的辅助通道信号相加并求平均,噪声信号因非同相叠加得到一定抑制,输出信号中包含期望信号和残留噪声,并将其作为参考信号d(n):
式中,τ*1为辅助通道“*”相对于主通道的时延;
差通道信号为将主通道信号与时延补偿后的辅助通道信号分别相减并构成(m-1)维向量,输出信号中潜在机动车鸣笛声信号被消除,将其作为噪声参考信号x(n):
x(n)=[x1(n)-x2(n-τ21),x1(n)-x3(n-τ31),...,x1(n)-xm(n-τm1)]t
式中,上标t表示转置;
步骤3-2、将步骤3-1的和、差通道信号分别作为维纳滤波器的主通道、辅助通道信号,通过块自适应算法调整维纳滤波器权矢量对差通道信号进行最优估计,获得维纳滤波器最优的估计权矢量
步骤3-3、根据步骤3-1的和、差通道信号以及步骤3-2的维纳滤波器最优的估计权矢量
进一步地,步骤3-2具体为:
步骤3-2-1、利用差通道信号x(n)构造若干数据块,假设每个数据块由i个快拍数据构成,每个数据块表示为:
x=[x(pi+1),x(pi+2),......,x(pi+i)]
式中,p表示第p个数据块;
利用第p个数据块估计差通道信号的协方差矩阵
式中,上标h表示共轭转置;
步骤3-2-2、求取和通道信号与差通道信号的互相关向量
步骤3-2-3、根据维纳-霍夫方程求取维纳滤波器最优的估计权矢量
进一步地,步骤4具体为:
步骤4-1、将连续的潜在机动车鸣笛声数据帧合并为一个潜在机动车鸣笛声片段,由此获得若干个潜在机动车鸣笛声片段;
步骤4-2、针对合并后的每一个潜在机动车鸣笛声片段,进行j层小波包分解,共获得n个小波包频带,其中n=2j,每个小波包内包括p个小波包系数;将第i′个小波包中的系数表示为wp(i′,k′),其中i′=1,2,......,n和k′=1,2,......,p,由此第i′个小波包频带内能量eni,表示为:
因此每一个潜在机动车鸣笛声片段的小波包能量特征参数表示为:
en=[en1,en2,......,enn]t;
步骤4-3、采用支持向量机识别算法完成机动车鸣笛声的声学检测,具体为:
步骤4-3-1、对于合并后的潜在机动车鸣笛声片段,将其中若干已知检测结果的机动车鸣笛声片段以及现有常见的交通干扰信号片段作为训练集,将其余的潜在机动车鸣笛声片段作为测试集;
步骤4-3-2、将训练集中所有信号片段小波包能量特征输入支持向量机分类器,构造二分类模型;
步骤4-3-3、将测试集中每个潜在机动车鸣笛声片段的小波包能量特征输入步骤4-3-2构造的分类模型中即获取该潜在机动车鸣笛声片段声学检测结果,所述潜在机动车鸣笛声片段的声学检测结果即该片段是否为机动车鸣笛声。
下面结合实施例对本发明作进一步详细的描述。
实施例
结合图1,本发明基于麦克风阵列的机动车鸣笛声监测方法仿真实验步骤如下:
步骤1,基于麦克风阵列采集多通道交通音频信号,并对其进行预处理。
本实施例中麦克风阵列采用四元矩形麦克风平面阵列,如图2所示,四个麦克风位于矩形的四个角上,对四元平面麦克风阵列以一定的顺序依次编号为1~4。麦克风阵列采样率为fs=32000hz。预处理过程首先通过一阶数字滤波器对数据进行预加重,然后对预加重后的各通道交通音频信号进行分帧,分帧时,鉴于声源的动态性能,一般要求各帧声源方向角不变。根据主城区对机动车速度限制,假设机动车时速为60km/h,并假设当声源移动距离为0.5m时,声源方向角的变换可以忽略不计,因此数据帧长度lf=1024;如图3所示,为单通道交通音频信号,包含机动车鸣笛声与其它交通噪声;
步骤2,利用步骤1预处理后的多通道交通音频信号进行自适应声源方向估计,并根据声源方向估计结果进行声源筛选,筛选出若干潜在机动车鸣笛声帧;具体步骤如下:
1)麦克风阵列接收的四个通道信号的某一数据帧可以表示为x1(n)、x2(n)、x3(n)、x4(n),n=1,2,3,......,lf。将四元平面麦克风阵列中的通道1为主通道,其余通道作为辅助通道,构造辅助通道c(c=2,3,4)的快拍xkc:
xkc=[xc(k),xc(k+1),......,xc(k+l-1)]t
式中,k表示第k个快拍,且k=1,2,......,lf-l+1,l表示滤波器长度,上标t表示矢量转置。本实施例中上取值为101。
求取自相关矩阵rxx:
式中,k=lf-l+1为快拍数量;
求取互相关矩阵rxa,所用公式为:
式中
求取权矢量wc1,所用公式为:
对权矢量wc1进行峰值检测,将最大峰值的横坐标记为zc,则辅助通道c接收信号相对于主通道的时延点数τc1为:
τc1=zc-d;
2)根据声源方向估计结果进行声源筛选,利用获得的权矢量wc1,若权矢量的主瓣与峰值旁瓣比均大于2,则认为当前数据帧为潜在鸣笛声帧;
步骤3、采用广义旁瓣对消器对步骤2获得的所有潜在机动车鸣笛声帧进行自适应增强,具体步骤如下:
1)对辅助通道信号进行时延补偿,并基于时延补偿后的辅助通道信号获取和、差两个通道信号。
和通道信号为将主通道信号与时延补偿后的辅助通道信号相加并求平均,噪声信号因非同相叠加得到一定抑制,输出信号中包含期望信号和残留噪声,将其作为参考信号d(n):
差通道信号为将主通道信号与时延补偿后的辅助通道信号分别相减并构成3维向量,输出信号中潜在机动车鸣笛声信号被消除,仅保留噪声信号,将其作为噪声参考信号x(n):
x(n)=[x1(n)-x2(n-τ21),x1(n)-x3(n-τ31),x1(n)-x4(n-τ41)]t式中,上标t表示转置;
2)和、差通道信号分别作为维纳滤波器的主通道与辅助通道信号,通过块自适应算法调整维纳滤波器权矢量对差通道信号进行最优估计,获得维纳滤波器最优的估计权矢量
通过快拍数据估计差通道信号的协方差矩阵
式中,p表示第p个数据块,每个数据块含i个快拍。本实施例中i=101。
求取和通道信号与差通道信号的互相关向量
根据维纳-霍夫方程求取维纳滤波器最优的估计权矢量
3)经维纳滤波器的噪声相消后输出的较为纯净的潜在机动车鸣笛声信号可表示为:
步骤4、对步骤3已增强的潜在机动车鸣笛声数据帧进行合并,获得潜在机动车鸣笛声片段,之后提取该片段的特征参数,构建潜在机动车鸣笛声片段特征集,并结合机器学习中的识别算法完成机动车鸣笛声的声学检测,具体为:
1)将连续的潜在机动车鸣笛声数据帧合并为一个潜在机动车鸣笛声片段,由此获得若干个潜在机动车鸣笛声片段;
2)针对每个潜在机动车鸣笛声片段,进行j层小波包分解,共得到n个小波包频带,其中n=2j。其中每个小波包内含p个小波包系数。将第i′个小波包中的系数表示为wp(i′,k′),其中i′=1,2,......,n和k′=1,2,......,p。因此将第i′个小波包频带内能量eni,表示为
本实施例中,根据现有的机动车鸣笛声数据以及机动车喇叭标准,通过统计分析,j=6,故n=64。因此机动车鸣笛声的小波包能量特征参数可以表示为:
en=[en1,en2,......,enn]t
故矢量维度为64×1。
3)采用本发明的方法,在主城区内的十字路口布设四元平面麦克风阵列,采集多组交通音频信号,每组数据包含四通道数据,该组数据中,对已增强机动车鸣笛声合并,共包含1250段潜在的段机动车鸣笛声,其中412个机动车鸣笛声片段,838个非鸣笛声片段,构成1250×64维特征矩阵。本实施例中采用libsvm工具箱,选用径向基核函数,并采用自动寻优方式设置惩罚因子c和核参数g。并对测试集的检测结果采用平均分类正确率ca、查准率precision、查全率recall、f1度量等评价指标进行评估,定义分别如下:
式中,nt表示测试样本总个数,nc表示分类正确的测试样本总个数,tp(truepositive)和fp(falsepositive)分别表示测试集中该类所有正例被正确和错误分类的数目,而fn(falsenegative)则指测试集中该类所有负例被错误分类的数目。
本实施例进行了100次机动车鸣笛声分类实验,每次实验采用无放回方式从每类机动车鸣笛声中随机抽取60%样本(实验中每个片段对应特征向量称为一个样本)作为总体训练集,余下每类40%样本共同组成总体测试集,并对测试集的分类结果进行性能评估。实验显示增强后100次实验获得的平均分类正确率为93.4%,增强前后机动车鸣笛声检测平均查准率、查全率以及f1度量结果如下表1所示,由表中结果可知,增强前机动车鸣笛声分类平均查准率、查全率以及f1度量在80%以上,而增强后机动车鸣笛声分类平均查准率、查全率以及f1度量在86%以上。综合总体分类性能,可证明本发明方法性能良好,适用于噪声环境下机动车鸣笛声监测问题。
表1100次机动车鸣笛声分类实验平均查准率、查全率以及f1度量
本发明面向禁鸣区机动车鸣笛声监测任务,基于平面麦克风阵列获取的多通道交通音频信号实现机动车鸣笛声自适应增强。本发明的方法可以有效改善噪声环境中机动车鸣笛声信噪比,提升机动车鸣笛声的声学检测准确性。
- 还没有人留言评论。精彩留言会获得点赞!