一种基于机器学习的车辆异常轨迹实时识别方法与流程
本发明涉及车辆轨迹异常识别领域,尤其是一种基于机器学习的车辆异常轨迹实时识别方法。
背景技术:
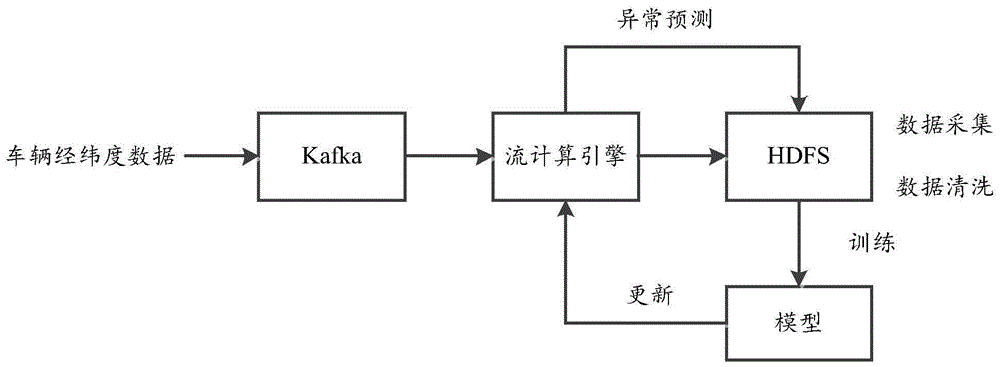
:随着中国社会经济的发展,中国市场上的车辆(汽车、电动车、摩托车)的保有量越来越大,车辆丢失问题也成为一个比较棘手的社会治安管理问题。目前车主的车辆失窃一般采用事后报警、事后追查历史轨迹和监控的方法,然而很多盗窃团伙有比较庞大和成熟的销赃网络,销赃速度特别快,一旦车辆丢失,报警后车辆追回的概率比较低,同时进行追赃所花费的人力成本和社会资源比较高。现有采取机器学习模型的车辆轨迹异常识别技术功能点都聚焦于机器学习算法的优化,比如车辆轨迹数据的数据清洗、停留点提取、兴趣区域挖掘、可视化兴趣区域、移动模式挖掘等方面。但其存在以下缺点:一、训练好的模型采用定制化训练,训练后使用时无法根据反馈数据进行更新,无法对模型进行修正,模型逐渐失去准确度;二、车辆海量信息下,系统的吞吐量和性能无法满足。因此,需要一种车辆异常轨迹识别方法可以克服以上问题。技术实现要素:本发明的目的在于:本发明提供了一种基于机器学习的车辆异常轨迹实时识别方法,解决现有车辆异常轨迹识别模型无法更新导致识别准确度低的问题。本发明采用的技术方案如下:一种基于机器学习的车辆异常轨迹实时识别方法,包括如下步骤:对采集的数据进行清洗获取完整、无重复、无异常值的训练数据;利用基于无监督的孤立森林方法和训练数据进行模型训练,获取异常检测模型;将异常检测模型放进流计算引擎中进行实时预测,并将预测结果发送至车主;根据车主的反馈信息自动更新和修正模型,并将更新后的模型放进流计算引擎中进行实时预测和将预测结果发送至车主。优选地,所述采集的数据包括车辆的经度数据、车辆的纬度数据和unix时间;所述数据的保存系统采用hadoop分布式文件系统即hdfs;所述数据的清洗工具采用hive。优选地,所述模型训练包括如下步骤:步骤a:利用训练数据进行异常值检测模型训练,得到异常检测模型;步骤b:对异常检测模型进行模型准确率评估,判断其模型准确率是否达标,若达标,则通过处理获得异常检测模型pmml文件;若未达标,则跳至步骤a继续训练。优选地,所述将完成训练模型放进流计算引擎中进行实时预测包括如下步骤:步骤aa:按时间段或者连续触发次数设置告警策略和告警级别,得到告警策略组;步骤bb:使用异常检测模型实时预测车辆数据后输出概率值,将概率值和告警策略组匹配获取告警信息;步骤cc:将告警信息发送给车主,发送方式包括微信触达、短信和彩信。优选地,所述根据车主的反馈信息自动更新和修正模型包括如下步骤:步骤aaa:基于车辆的历史数据和最新数据,自动对异常值检测模型进行定期训练得到新模型;步骤bbb:自动检测新模型的准确率是否达标,若达标,则跳至步骤ccc更新模型,若不达标,则不更新模型;步骤ccc:自动对检测达标的模型进行替换部署。优选地,所述步骤aaa中自动对异常值检测模型进行定期训练包括如下步骤:组建模型的训练数据集,所述训练数据集包括hdfs上的所有历史训练数据集和最新获取的数据;设置定时训练脚本;根据定时训练脚本定时将训练数据集放入模型中进行训练,完成定时训练;其中本次的训练数据集作为下次的历史训练数据集。综上所述,由于采用了上述技术方案,本发明的有益效果是:1.本发明采用大数据流计算和机器学习相结合的方式,通过周期性采集车辆的经纬度、时间等数据信息,使用无监督的孤立森林等异常检测算法,在流计算引擎中对车辆轨迹进行实时预测分析,给出车辆异常行为的概率值,根据车辆用户给出的反馈数据,周期性调整模型,实现动态更新模型,解决现有车辆异常轨迹识别模型无法更新导致识别准确度低的问题,周期性地自动更新机器学习预测模型,提高模型的识别准确率;2.本发明基于机器学习模型实时检测车辆轨迹异常的概率值,根据设置的告警策略判断车辆失窃的可能性,能提前预测车辆失窃;3.本发明基于无监督的孤立森林(isolationforest)等异常值检测方法进行模型训练,孤立森林算法直接找出异常数据,不用对正常的数据构建模型,相比于传统的异常数据检测方法,模型的准确性和稳定性更高,在海量数据上检测效率更高;4.本发明使用流式引擎这种大数据框架可扩展性强,吞吐量大,处理数据实时高效,不间断。附图说明为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。图1为本发明的方法框图;图2为本发明的方法流程图;图3为本发明的具体实施效果示意图;图4为本发明的模型更新流程图;具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。需要说明的是,术语“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。技术问题:解决现有车辆异常轨迹识别模型无法更新导致识别准确度低的问题;技术手段:一种基于机器学习的车辆异常轨迹实时识别方法,包括如下步骤:对采集的数据进行清洗获取完整、无重复、无异常值的训练数据;利用基于无监督的孤立森林方法和训练数据进行模型训练,获取异常检测模型;将异常检测模型放进流计算引擎中进行实时预测,并将预测结果发送至车主;根据车主的反馈信息自动更新和修正模型,并将更新后的模型放进流计算引擎中进行实时预测和将预测结果发送至车主。采集的数据包括车辆的经度数据、车辆的纬度数据和unix时间;所述数据的保存系统采用hadoop分布式文件系统即hdfs;所述数据的清洗工具采用hive。模型训练包括如下步骤:步骤a:利用训练数据进行异常值检测模型训练,得到异常检测模型;步骤b:对异常检测模型进行模型准确率评估,判断其模型准确率是否达标,若达标,则通过处理获得异常检测模型pmml文件;若未达标,则跳至步骤a继续训练。将完成训练模型放进流计算引擎中进行实时预测包括如下步骤:步骤aa:按时间段或者连续触发次数设置告警策略和告警级别,得到告警策略组;步骤bb:使用异常检测模型实时预测车辆数据后输出概率值,将概率值和告警策略组匹配获取告警信息;步骤cc:将告警信息发送给车主,发送方式包括微信触达、短信和彩信。优选地,所述根据车主的反馈信息自动更新和修正模型包括如下步骤:步骤aaa:基于车辆的历史数据和最新数据,自动对异常值检测模型进行定期训练得到新模型;步骤bbb:自动检测新模型的准确率是否达标,若达标,则跳至步骤ccc更新模型,若不达标,则不更新模型;步骤ccc:自动对检测达标的模型进行替换部署。步骤aaa中自动对异常值检测模型进行定期训练包括如下步骤:组建模型的训练数据集,所述训练数据集包括hdfs上的所有历史训练数据集和最新获取的数据;设置定时训练脚本;根据定时训练脚本定时将训练数据集放入模型中进行训练,完成定时训练;其中本次的训练数据集作为下次的历史训练数据集。技术效果:本发明采用大数据流计算和机器学习相结合的方式,通过周期性采集车辆的经纬度、时间等数据信息,使用无监督的孤立森林等异常检测算法,在流计算引擎中对车辆轨迹进行实时预测分析,给出车辆异常行为的概率值,根据车辆用户给出的反馈数据,周期性调整模型,实现动态更新模型,解决现有车辆异常轨迹识别模型无法更新导致识别准确度低的问题,周期性地自动更新机器学习预测模型,提高模型的识别准确率;本发明基于机器学习模型实时检测车辆轨迹异常的概率值,根据设置的告警策略判断车辆失窃的可能性,能提前预测车辆失窃;基于无监督的孤立森林(isolationforest)等异常值检测方法进行模型训练,孤立森林算法直接找出异常数据,不用对正常的数据构建模型,相比于传统的异常数据检测方法,模型的准确性和稳定性更高,在海量数据上检测效率更高;使用流式引擎这种大数据框架可扩展性强,吞吐量大,处理数据实时高效、不间断。以下结合实施例对本发明的特征和性能作进一步的详细描述。实施例1专业术语解释:pmml,全称预测模型标记语言(predictivemodelmarkuplanguage),利用xml描述和存储数据挖掘模型,pmml是一种事实标准语言,用于呈现数据挖掘模型。hadoop是一个由apache基金会所开发的分布式系统基础架构。hdfs,hadoop实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs。hdfs有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(highthroughput)来访问应用程序的数据,适合那些有着超大数据集(largedataset)的应用程序。hive,基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为mapreduce任务进行运行。spark,apachespark是专为大规模数据处理而设计的快速通用的计算引擎,包括sql、ml、graphx、streaming等四种功能。flink,新型流式计算框架。kafka,由apache软件基金会开发的一个开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,官网:http://kafka.apache.org/。一种基于机器学习的车辆异常轨迹实时识别方法,包括如下步骤:对采集的数据进行清洗获取完整、无重复、无异常值的训练数据;利用基于无监督的孤立森林方法和训练数据进行模型训练,获取异常检测模型;将异常检测模型放进流计算引擎中进行实时预测,并将预测结果发送至车主;根据车主的反馈信息自动更新和修正模型,并将更新后的模型放进流计算引擎中进行实时预测和将预测结果发送至车主。具体如下:步骤一、数据采集和数据清洗:为了使用机器学习算法对车辆异常轨迹进行模型训练,使用传统关系型数据库(mysql、oracle等)保存海量车辆信息不适用的,因为关系型数据库由于加锁机制,在数据量达到百万级别后就需要分库分表,可扩展性差。因此本申请基于hadoop大数据框架处理海量数据信息,使用hdfs保存数据,使用hive对数据进行数据清洗。数据名类型范围说明经度double0~180车辆的经度数据纬度double0~90车辆的纬度信息时间bigint1~2^64unix时间,即1970年1月1号以来的秒数数据清洗方式:经度信息、纬度信息、时间信息有任意一个缺失则去掉该条记录;去掉不在数据范围内的记录即异常值;去掉数据类型不准确的记录;使用distinct去掉重复数据记录;步骤二、模型训练:基于无监督的孤立森林(isolationforest)方法进行模型训练;孤立森林算法直接找出异常数据,不用对正常的数据构建模型,相比于传统的异常数据检测方法,模型的准确性和稳定性更高,在海量数据上检测效率更高。概率值越接近1越可能是异常值,越接近0越可能是正常值。当大部分数据的概率值是0.5时,则表示数据无异常值。模型训练应该满足以下条件:训练数据的数据量足够大、时间周期足够长;训练数据已进行数据清洗,没有缺失数据,没有异常数据,数据已经去重;模型训练的准确率和召回率应该高于期望的阈值(例如90%);模型训练工具使用大数据机器学习工具spark-ml或flink-ml;模型训练成功后保存成pmml文件,放入流计算引擎中进行异常预测。pmml文件名使用“业务名-版本号-更新时间”来设定,保存为pmml文件的目的是保存成通用的模型格式,方便在流计算引擎(flink、storm、sparkstreaming)中进行加载、预测。步骤三、异常预测:将训练好的模型放入流计算引擎中进行实时预测,输出异常概率值(0~1)。异常概率值越高,说明车辆目前处于异常轨迹的可能性越高。设置多种形式的告警策略:异常阈值:此处设置为0.85;异常次数:此处设置为5。告警策略一:不区分时间段,只要连续五次都高于异常预测阈值,就进行告警;告警策略二:区分时间段,例如在午夜(凌晨0——5点),只要连续五次都高于异常预测阈值,就进行告警;自定义告警策略:满足其他组合条件进行告警。将输出的概率值匹配告警策略获取告警信息,将告警信息(包含车辆违章位置)通过短信或者微信触发等方式通知车辆用户,并要求用户反馈是否误报。如果用户回复误报,则记录为误报,如果用户回复正常,则记录为正常;如果用户不回复,视为正常。步骤四、模型更新:根据车主的反馈信息自动更新和修正模型,并将更新后的模型放进流计算引擎中进行实时预测和将预测结果发送至车主。实际应用时,通过判断车辆在不同时间点(上下班、周末、节假日等)的运动轨迹来总结车辆的运动规律;通过判断车辆偏移轨迹的频次和时间点,结合总结的车辆运动规律来实时判断车辆丢失的概率;车主作为使用方,会收到告警信息,信息中会对告警给出简单解释,例如:车辆突然偏移常规路线很远;车辆在异常时间点(例如:深夜)出现在非常规区域;如图3所示,蓝色实线为车辆正常轨迹,红色虚线为车辆异常轨迹,能快速识别车辆轨迹是否异常;识别过程中会根据告警信息的反馈更新模型,提高模型的识别准确率;本发明采用大数据流计算和机器学习相结合的方式,通过周期性采集车辆的经纬度、时间等数据信息,使用无监督的孤立森林等异常检测算法,在流计算引擎中对车辆轨迹进行实时预测分析,给出车辆异常行为的概率值,根据车辆用户给出的反馈数据,周期性调整模型,实现动态更新模型,解决现有车辆异常轨迹识别模型无法更新导致识别准确度低的问题,周期性地自动更新机器学习预测模型,提高模型的识别准确率。实施例2本发明实施例一的基础上,细化模型更新,如图4所示,具体如下:步骤四、模型更新:根据车主的反馈信息自动更新和修正模型包括如下步骤:步骤aaa:基于车辆的历史数据和最新数据,自动对异常值检测模型进行定期训练得到新模型;步骤bbb:自动检测新模型的准确率是否达标,若达标,则跳至步骤ccc更新模型,若不达标,则不更新模型;步骤ccc:自动对检测达标的模型进行替换部署。步骤aaa中自动对异常值检测模型进行定期训练包括如下步骤:组建模型的训练数据集,所述训练数据集包括hdfs上的所有历史训练数据集和最新获取的数据;设置定时训练脚本;根据定时训练脚本定时将训练数据集放入模型中进行训练,完成定时训练;其中本次的训练数据集作为下次的历史训练数据集。模型需要定期进行更新和修正,才能持续保证模型的准确性和有效性,更新周期可以自定义,更新周期可以为天、周、月、年。更新周期越长,使用的系统资源越少,但模型的准确性会越来越低;模型更新的周期越短,使用的系统资源越多,但模型的准确性得到保证。模型设置为自动训练、自动检测、自动部署。基于最新数据、已有历史数据和用户反馈数据定期进行模型训练,模型训练后使用准确率p(precision)指标自动检测模型是否符合达标,准确率指的是模型识别的整体准确率,即预测为异常的车辆中有多大比率是预测准确的。模型选取策略:单次训练的模型准确率p>=90%,模型达标;连续两次训练的模型准确率[80%,90%),模型达标;单次训练的模型准确率p<80%,模型不达标。具体阈值可以根据业务的安全等级进行调整,安全系数要求高的就将两个阈值调整的高一点,安全系数要求低的将两个阈值调整的低一点。如果模型不达标则不更新,仍然使用旧模型,如果模型达标则使用新模型。自动更新时,在流式计算引擎中设置两条预测链路,两条链路互为备份;当一条预测链路a在使用时,另一条预测链路b用于更新;当模型更新生效后,链路b用于预测,链路a用于更新,如此循环往复。通过车辆用户给出的反馈数据,周期性调整模型,实现动态更新模型,避免现有预测数据错误情况下继续使用错误模型导致模型识别率越来越低的缺点,周期性地自动更新机器学习预测模型,根据反馈数据更新,提高模型的有效性和识别准确率。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1