一种基于深度强化学习算法的单交叉口信号控制方法
本发明涉及交通信号控制的,特别是涉及一种基于深度强化学习算法的单交叉口信号控制方法。
背景技术:
1、交通信号是在道路交叉口上无法实现交通分离的地方,用来在时间上给交通流分配通行权的交通指挥措施。
2、现在的单交叉口信号的控制,大多使用贪婪算法或改进的贪婪算法进行学习过程中的动作探索,而贪婪算法如申请号为201210389864.8的发明专利中公开的一种基于贪婪算法的同或/或电路的分解方法。
3、实验表明,使用贪婪算法或改进的贪婪算法对不同状态下的不同动作选择探索效率较低,影响了算法的学习效率,并且有的解决单交叉口信号控制问题的技术中所使用的输入信息和奖励多为车道内的队列长度和车辆密度等数据,这些信息在实际应用场景中难以准确获得,导致实用性较差,因此亟需一种基于深度强化学习算法的单交叉口信号控制方法。
技术实现思路
1、为解决上述技术问题,本发明提供一种通过采集由车道离散化的单元格中的车辆存在性特征,奖励函数使用的通信能力也由该特征计算得到,提高了交通状态特征和奖励函数的准确性,并且在网络结构中加入噪声网络,提高算法的动作探索能力,从而提高了算法的收敛速度的一种基于深度强化学习算法的单交叉口信号控制方法。
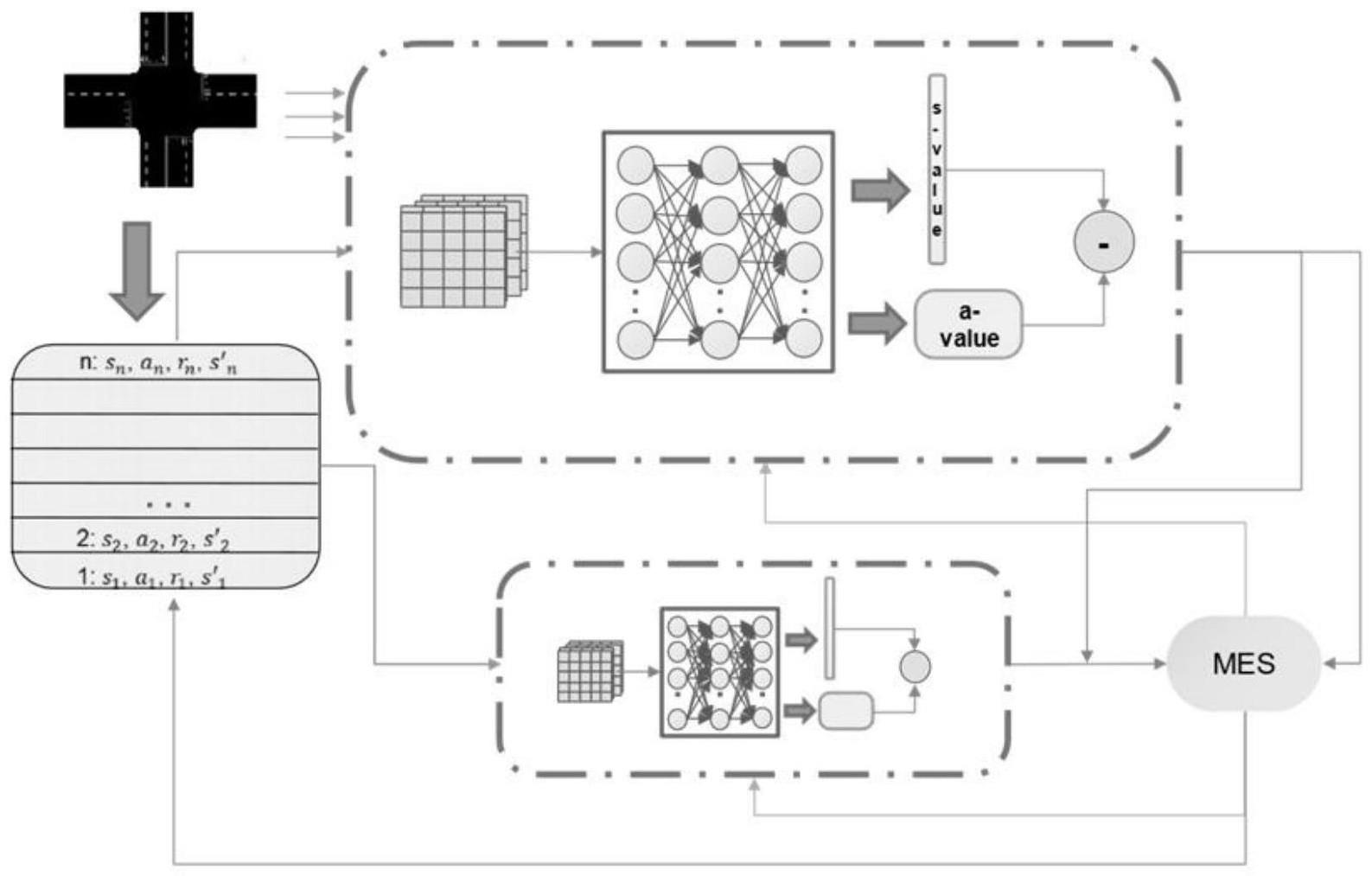
2、本发明的一种基于深度强化学习算法的单交叉口信号控制方法,网络结构主要分为三个部分:主网络、目标网路和经验池;
3、s1、通过算法使用主网络进行动作的选择,使用目标网络进行q值计算,达到避免算法过估计的目的,通过经验池对训练过程中产生的训练样本进行储存;
4、s2、将每条道路的驶入车道离散化为单元格,在每个单元格中进行车辆存在性检测,用(0,1)表示单元格内的车辆存在性特征,通过对每个单元格特征的拼接、处理得到一个高维的向量作为环境状态特征,另外为了方便对算法的决策进行奖励或处罚,通过环境内的车辆存在性特征计算得到累计队列长度,定义前一时间步的累计队列长度和当前时间步的累计队列长度之差为通行能力,将通行能力作为算法的奖励函数;
5、s3、采用dueling网络机制,将全连接神经网络提取的抽象特征结果输出到两个分支,即状态价值和动作价值,并使用噪声网络对价值函数进行扰动,以达到动作探索的目的;
6、s4、随后将两条分支聚合得到最终的优势函数,即每个动作对应的q值。
7、优选的,所述主网络与目标网络结构相同,由3层神经元数量为128的全连接神经网络进行状态特征的处理和连接。
8、优选的,所述s2中两个噪声网络的神经元数量均为64,状态价值的输出为1,动作价值的输出与动作空间大小相同,这里为4。
9、优选的,所述s1中的方法为基于深度q学习算法(dqn)的改进算法,算法流程包括如下步骤:
10、s1、把网络参数赋值给目标网络,初始化经验池,初始化交通环境,获得初始交通状态特征;
11、s2、将状态特征输入q网络,计算出每个动作对应的q值,选择最佳动作;
12、s3、执行上一步中的最佳动作,得到新的交通状态和奖励,将状态、动作、奖励和新的状态作为一条经验存入经验池;
13、s4、从经验池中采样,计算当前网络的目标值,并使用梯度下降方法更新网络参数;
14、s5、如果满足目标网络更新频率,则更新目标网络参数;如果没有达到训练总回合数,则将新的状态更新为当前状态,输入q网络中继续迭代,否则结束流程。
15、优选的,使用噪声网络对价值函数进行扰动,即在dueling网络输出状态价值和动作价值时,在神经网络的连接权重中加入参数化的噪声,这样算法对动作的扰动能力更大,提高在训练阶段算法对不同策略的探索能力,有效提高算法的学习效率。
16、优选的,本文算法使用了优先级经验回放的方法进行样本的重复学习。
17、优选的,在经验池中的经验样本更新时,对每一条经验样本进行一次重要性权重的更新,由每个样本的优先值计算它的被采样概率,根据这个概率赋予该样本对应的重要性权重,由于样本的优先值来自它的时间差误差,该方法的本质是使得更有学习价值的经验被采样的概率更大,进而提高算法的学习能力
18、与现有技术相比本发明的有益效果为:
19、1、控制器采集的交通状态特征为由车道离散化的单元格中的车辆存在性特征,奖励函数使用的通信能力也由该特征计算得到,提高了交通状态特征和奖励函数的准确性;
20、2、在网络结构中加入噪声网络,相较于贪婪算法和改进的贪婪算法,噪声网络可以在算法的动作选择中提供更大的扰动,提高算法的动作探索能力,从而提高了算法的收敛速度,另外,由于噪声网络是在神经网络连接权重中加入参数化的噪声,因此噪声的大小可以调节,即算法的探索能力可以控制;
21、3、在算法训练过程中使用优先经验回放方法,根据经验样本的时间差误差赋予它们重要性权重,采样时根据重要性权重进行采样,即越重要的样本被采样的概率越大,算法学习这些样本的次数越多,相较于使用均匀采样的经验回放方法,该方法提高了经验利用率,进而提高了算法的学习能力。
技术特征:
1.一种基于深度强化学习算法的单交叉口信号控制方法,其特征在于,网络结构主要分为三个部分:主网络、目标网路和经验池;
2.如权利要求1所述的一种基于深度强化学习算法的单交叉口信号控制方法,其特征在于,所述主网络与目标网络结构相同,由3层神经元数量为128的全连接神经网络进行状态特征的处理和连接。
3.如权利要求1所述的一种基于深度强化学习算法的单交叉口信号控制方法,其特征在于,所述s3中两个噪声网络的神经元数量均为64,状态价值的输出为1,动作价值的输出与动作空间大小相同,这里为4。
4.如权利要求1所述的一种基于深度强化学习算法的单交叉口信号控制方法,其特征在于,所述s1中的方法为基于深度q学习算法(dqn)的改进算法,算法流程包括如下步骤:
5.如权利要求1所述的一种基于深度强化学习算法的单交叉口信号控制方法,其特征在于,使用噪声网络对价值函数进行扰动,即在dueling网络输出状态价值和动作价值时,在神经网络的连接权重中加入参数化的噪声,这样算法对动作的扰动能力更大,提高在训练阶段算法对不同策略的探索能力,有效提高算法的学习效率。
6.如权利要求4所述的一种基于深度强化学习算法的单交叉口信号控制方法,其特征在于,本文算法使用了优先级经验回放的方法进行样本的重复学习。
技术总结
本发明涉及交通信号控制的技术领域,特别是涉及一种基于深度强化学习算法的单交叉口信号控制方法,其通过采集由车道离散化的单元格中的车辆存在性特征,奖励函数使用的通信能力也由该特征计算得到,提高了交通状态特征和奖励函数的准确性,并且在网络结构中加入噪声网络,提高算法的动作探索能力,从而提高了算法的收敛速度;网络结构主要分为三个部分:主网络、目标网路和经验池。
技术研发人员:黄贻望,吴谦
受保护的技术使用者:铜仁学院
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!