一种基于多智能体深度强化学习的公交优先交通信号协同控制方法
本发明属于智能交通控制,具体涉及一种基于多智能体深度强化学习的公交优先交通信号协同控制方法。
背景技术:
1、城市交通拥堵是一个严重的全球性问题,不仅浪费了大量的时间和资源,还对环境造成了负面影响。现有的交通信号控制方法通常是基于预定的定时计划或传感器数据,缺乏灵活性以适应实时交通情况。特别是,公共交通工具,如公交车,通常受到交通拥堵的严重影响,导致不准时和不可预测的公共交通服务。
2、传统的交通信号控制方法往往难以有效地应对多变的路况和需求,通常无法有效协调多个交叉路口的信号灯,以确保公共交通工具的顺畅流动。特别是如果需要进一步考虑公交车的到达准点率问题,这导致了其他车辆的交通拥堵、排放增加和乘客不满。因此,迫切需要一种新的方法,能够在多个交叉路口之间实现协同控制,以提高公共交通工具的运行效率和准时性,同时减少交通拥堵。
3、目前主要探索采用建立绿灯延长与红灯早断策略下的相位快速补偿机制来优化公交车辆通行效率,这一策略旨在根据公交车到达交叉口时间将交通信号灯调整为绿灯,使得公交车辆能够在交叉口快速通过,从而减少在交叉口的停车等候时间,减少公交车的总旅行时间。然而,公共交通优先级得到过多的关注,导致其他交通参与者的通行需求被忽视,造成一般交通的延迟和不便,增加了其他私人车辆在交叉口的等待时间,并增加了停车次数,加剧了车辆对环境的污染。
技术实现思路
1、目的:鉴于以上技术问题中的至少一项,本发明提供一种基于多智能体深度强化学习的公交优先交通信号协同控制方法,实现公交车优先策略的同时优化优化交通信号控制,最大化车辆通行效率,减少拥堵和提高道路通畅度。
2、本发明采用的技术方案为:
3、第一方面,本发明提供一种公交优先交通信号协同控制方法,包括:
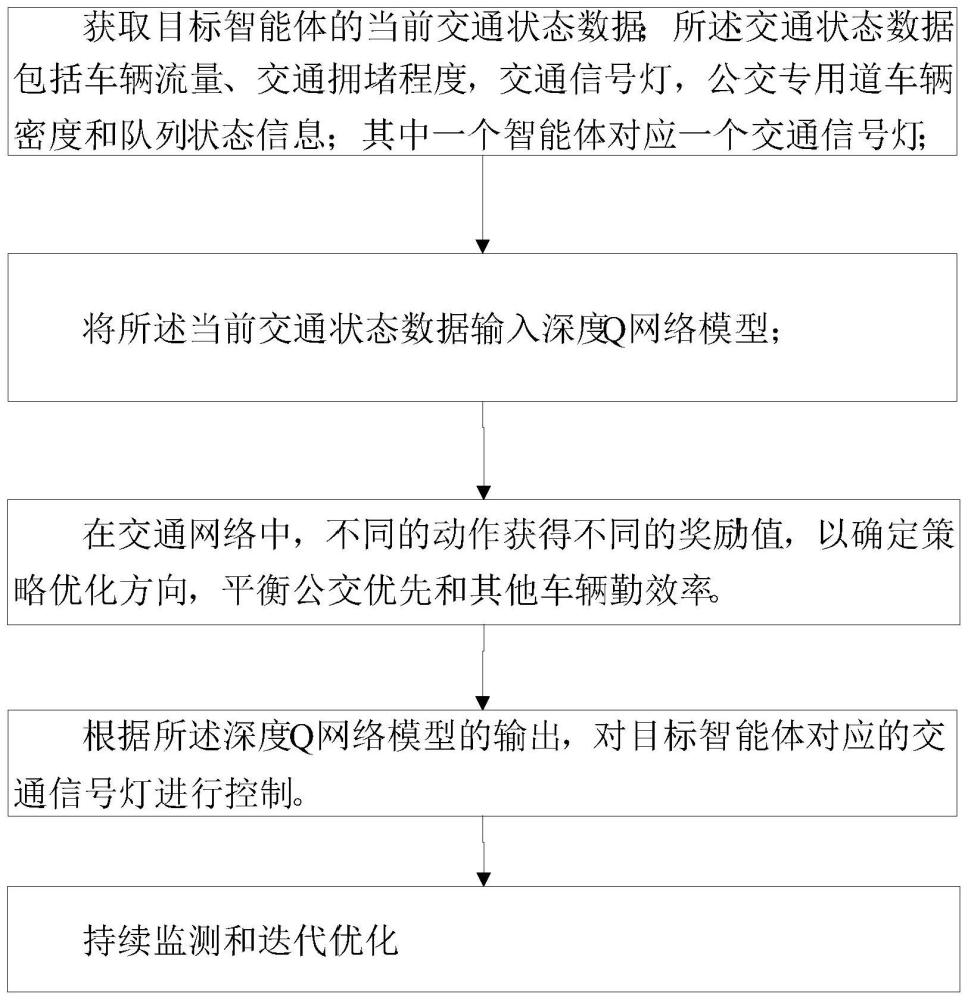
4、获取目标智能体的当前交通状态数据;所述交通状态数据包括车辆流量、交通拥堵程度和交通信号灯状态信息;其中一个智能体对应一个交通信号灯;
5、将所述当前交通状态数据输入深度q网络模型;
6、根据所述深度q网络模型的输出,对目标智能体对应的交通信号灯进行控制;
7、其中所述深度q网络模型的获取方法包括:
8、获取历史时间段目标子区域内所有智能体的交互数据(当前交通状态s,动作a,奖励r,新交通状态s′),放入经验回放缓冲区中;具体包括:在每个时间步,智能体获取当前交通状态s;将当前交通状态s输入深度q网络模型中,所述模型为每个可能的动作计算一个q值,并基于∈-greedy策略,根据计算出的q值选择动作a;获取执行所述动作a后得到的立即奖励r以及新交通状态s′;
9、从经验回放缓冲区中随机抽取批量样本,利用梯度下降方法训练更新深度q网络模型的网络参数,直至达到预设要求;
10、根据更新后的网络参数,分别对各智能体中的深度q网络模型的网络参数进行更新。
11、在一些实施例中,每个智能体的交通状态数据包括:信号灯的当前相位、标志位、车道密度、车道队列以及公交车专用车道的车辆密度和公交车专用车道的车道队列。
12、进一步地,交通状态s表示为:
13、s=[current_phase,min_green,lane_density,lane_queue,bus_lane_density,bus_lane_queue]
14、其中current_phase表示交通信号灯的当前相位,采用one-hot独热编码表示;标志位min_green指示当前相位的持续时间是否已达到预设的最小持续时间;若未达到最小持续时间,任何切换相位的动作都将被视为无效;bus_lane_density:公交车专用车道的车辆密度;bus_lane_queue:公交车专用车道的队列长度与车道总长度的比值;
15、车道密度lane_density表示交通信号灯所在路口的驶入车道的占用率;lane_density[i]=车辆数量number_of_vehicles/总容量total_capacity
16、其中i用于区分交通信号灯所在路口中的不同驶入车道;
17、车道队列lane_queue表示的是驶入车道的队列长度queue_length与车道总长度total_apacity的比值:
18、lane_queue[i]=queue_length/tatal_apacity
19、当存在多条驶入车道时,i用于区分不同的驶入车道。
20、在一些实施例中,所述奖励函数reward为:
21、reward=-(β·bt+st)
22、其中bt表示公交车的准点误差,st表示当前交通状态中所有车辆的累计延误时间;β为权重参数。
23、进一步地,所述奖励函数的计算方法包括:
24、(1)根据公交车实时位置与时刻表时间差计算公交车的准点误差bt;
25、bt=ert+lrt
26、其中,ert和lrt表示公交车进站、出站的奖励值;
27、若公交车提前到站,将损失乘以一个较小的值0.01以降低对提前到站行为的惩罚;
28、
29、
30、
31、其中,δti=taai-tsai
32、其中,n表示路网中公交车的总停靠次数,taai、tadi表示公交车自发车至进、出i站台的时间间隔,tsai、tsdi表示时刻表规定的公交车自发车至进、出i站台的时间间隔;
33、(2)根据交通信号灯周边每个路口车队长度和等待时间计算当前交通状态中所有车辆的累计延误时间st;
34、
35、其中n是车辆的总数,di,t是第i辆车从时间0到时间t的累计延误时间,车辆的延误时间被定义为该车停车等待的时间;
36、(3)根据公交车的准点误差bt和当前交通状态中所有车辆的累计延误时间st,进行加权计算奖励函数reward。
37、在一些实施例中,所述深度q网络模型,包括:
38、q′(s,a)=q(s,a)+α[r+γmaxa′q(s′,a′)-q(s,a)]
39、其中:q′(s,a):更新后的q值;
40、q(s,a):当前状态s下采取动作a的原始q值;;
41、α:学习率,决定新信息覆盖旧信息的程度;
42、r:执行动作a后获得的立即奖励;
43、γ:折扣因子,用于平衡立即奖励和未来奖励的重要性;
44、maxa′q(s′,a′):在新交通状态s′下所有可能动作的最大q值。
45、在一些实施例中,利用梯度下降方法训练更新深度q网络模型的参数的过程中,采用的损失函数loss为:
46、
47、其中:q(s,a)表示当前的q值,qtarget(s,a)表示目标q值。
48、第二方面,本发明提供了一种公交优先交通信号协同控制系统,包括处理器及存储介质;
49、所述存储介质用于存储指令;
50、所述处理器用于根据所述指令进行操作以执行根据第一方面所述的方法。
51、第三方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的方法。
52、第四方面,本发明提供了一种设备,包括,
53、存储器;
54、处理器;
55、以及
56、计算机程序;
57、其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现上述第一方面所述的方法。
58、有益效果:本发明提供的基于多智能体深度强化学习的公交优先交通信号协同控制方法,具有以下优点:提升公交车辆的准点率。不同于传统的单一交叉口的控制方法,本发明采用多智能体深度强化学习方法,实现了对多个交叉口信号灯相位的整合和协同控制。这种方法的应用不仅局限于单一的交叉口,而是涵盖了整个道路网络,显著提升了整个交通系统的通行效率。
59、此外,该系统通过其先进的学习机制和智能决策过程,能够适应复杂且不断变化的交通环境,确保交通流的顺畅和公交车辆的准时到达。在提高公共交通效率的同时,也减少了道路拥堵,进而为城市交通管理提供了一个更加高效、可持续的解决方案。
- 还没有人留言评论。精彩留言会获得点赞!