具有集成高带宽存储器的堆叠裸片神经网络的制作方法
具有集成高带宽存储器的堆叠裸片神经网络
背景技术:
1.人工神经网络是受生物神经网络(例如,大脑)启发的计算系统。人工神经网络(以下简称“神经网络”)包括相互连接的人工神经元集合,这些人工神经元对它们的生物对应物进行松散建模。神经网络通过重复考虑示例来“学习”执行任务。例如,我们知道,对于某些品种的水果,人类观察者可以学会在视觉上区分成熟和未成熟样本。虽然我们可以猜测成熟度与样本水果图像中明显的质地、大小和颜色的某个函数相关,但我们可能无法准确地知道专家分拣员所依赖的视觉信息。神经网络可以导出图像数据的“成熟度”函数。然后,该函数可以用于从未分类水果的图像中“推断”样本成熟度。
[0002]“有监督学习”是训练神经网络的一种方法。在水果分类示例中,神经网络被提供有由人类品尝者手动标记为描绘“成熟”或“未成熟”水果的图像。未经训练的神经网络从默认分类函数或“模型”开始,该默认分类函数或“模型”可能与优化后的默认分类函数或“模型”几乎没有相似之处。因此,应用于未经训练的神经网络的图像会在推断的成熟度与标记的成熟度之间产生很大误差。使用称为“后向传播”的学习过程,神经网络响应于训练数据集而以减少误差的方式调节由其组成神经元应用的权重。因此,预测模型通过训练变得更加可靠。
[0003]
神经网络的任务是解决比水果分类复杂得多的问题。例如,神经网络正在适用于自动驾驶汽车、自然语言处理和很多生物医学应用,如诊断图像分析和药物设计。负责解决这些困难类别问题的神经网络可能非常复杂。因此,训练需要大量训练数据,并且无数神经元需要快速访问以存储在训练过程中计算的值,以及在训练中确定并且用于推理的值。因此,复杂的神经网络需要快速、高效地访问大量高性能存储器。
附图说明
[0004]
本公开在附图中以示例而非限制的方式示出。对于具有数字名称的元素,第一数字表示在其中引入该元素的图,并且类似的引用指代图内与图之间的类似元素。
[0005]
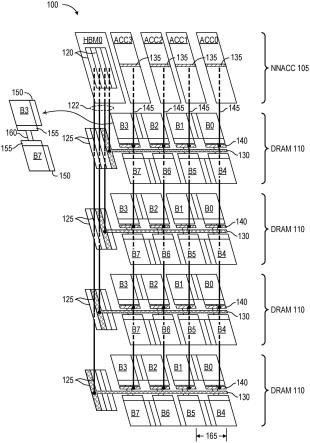
图1描绘了信息处理设备100,它是一种三维(3-d)专用集成电路(asic),其中处理器裸片(在这种情况下是神经网络加速器裸片105)使用例如硅通孔(tsv)或cu-cu连接结合到四个动态随机存取存储器(dram)裸片110的堆叠并且与该堆叠电互连,使得堆叠充当单个ic器件。
[0006]
图2是图1的设备100的实施例的平面图,其中加速器裸片105包括八个具有四个瓦片的集合(例如,集合acc[7:4]和acc[3:0]),这里示出了其中的四个集合,并且每个底层dram裸片包括八个集合200并且每个集合有八个存储体b[7:0]。
[0007]
图3是图1和图2的加速器裸片105的一部分的框图,该一部分包括外部接口hbm0和加速器瓦片acc0和acc3。
[0008]
图4a是根据实施例的3-d asic 400的框图,其包括加速器裸片405以及一对dram裸片dd0和dd1。
[0009]
图4b再现了图4a的框图400,但是直接通道块dca和dcb以及相关信号线使用粗线
突出显示以说明内部访问模式下的信号流,在内部访问模式下,加速器裸片405上的加速器瓦片(未示出)直接访问dram裸片dd0和dd1。
[0010]
图5描绘了根据另一实施例的3-d asic 500。asic 500类似于图1的设备100,相同地标识的元素相同或相似。
[0011]
图6a描绘了计算机系统600,其中具有主机处理器610的片上系统(soc)605可以访问先前详述的类型的3-d处理设备100。
[0012]
图6b描绘了实施例中的系统600,其中soc 605经由中介层640与设备100通信,中介层640具有蚀刻在硅中的精细间隔的迹线645。
[0013]
图7a描绘了地址域700,地址域700可以由主机处理器发出以加载加速器裸片105中的寄存器以控制模式。
[0014]
图7b描绘了地址域705,其可以由主机处理器使用用于孔径式模式选择。
[0015]
图7c描绘了两个地址域,即,可以由主机处理器发出以在hbm模式下访问dram页的外部模式地址域710、以及可以由内部存储器控制器使用用于类似访问的内部模式地址域715。
[0016]
图8示出了用于人工神经网络的专用集成电路(asic)800,其架构使处理元件与存储器(例如,堆叠的存储器裸片)之间的连接距离最小化,并且从而提高了效率和性能。
[0017]
图9示出了被互连以支持并发的前向和后向传播的四个加速器瓦片820。
[0018]
图10包括在单个加速器瓦片820上实例化的神经网络的功能表示1000和阵列1005。
[0019]
图11a描绘了处理元件1100,它是适合用作图10的每个处理元件1020的电路系统的示例。
[0020]
图11b描绘了图11a的处理元件1100,其具有为支持后向传播而提供的电路元件,使用粗线宽突出显示。
[0021]
图13示出了在通过图12的加速器瓦片1200的后向传播期间的信息流。
具体实施方式
[0022]
图1描绘了信息处理设备100,它是一种三维(3-d)专用集成电路(asic),其中处理器裸片(在这种情况下是神经网络加速器裸片105)使用例如硅通孔(tsv)或cu-cu连接结合到四个动态随机存取存储器(dram)裸片110的堆叠并且与该堆叠电互连,使得堆叠充当单个ic器件。加速器裸片105包括划分为四个hbm子接口120的高带宽存储器(hbm)接口hbm0。每个子接口120包括提供到水平存储器裸片数据端口125的连接122的通路域(包含tsv的区域),水平存储器裸片数据端口125通过水平(裸片内)连接130延伸到dram裸片110中的一个dram裸片上的八个存储体b[7:0]。水平存储器裸片数据端口125和相应连接130在每个dram裸片110上被加阴影,以突出显示用于对相应dram裸片110上的八个存储体b[7:0]的集合进行裸片内访问的信号路径,每个存储体是数据存储元件的独立可寻址阵列。接口hbm0允许主机处理器(未示出)存储训练数据并且从dram裸片110中检索推理模型和输出数据。加速器裸片105还包括四个处理瓦片,即,神经网络加速器瓦片acc[3:0],每个神经网络加速器瓦片包括到每个底层dram裸片110上的竖直(裸片间)存储器裸片数据端口140的通路域135。瓦片acc[3:0]和底层存储体b[7:0]被布局以建立相对较短的裸片间连接145。因此,存
储体堆叠(例如,四个存储体对b[4,0])形成加速器瓦片130服务中的高带宽存储器的竖直集合。因此,设备100支持针对外部访问而优化的dram特定hbm存储器通道和为支持用于训练和推理的访问而优化的特定于加速器的存储器通道。
[0023]
hbm dram支持存储体分组,这是一种通过交错来自属于不同存储体组的存储体的突发而使外部接口上的数据速率与一个存储体的数据速率相比加倍的方法。在该实施例中,dram裸片110被修改以支持到加速器瓦片acc[3:0]的相对直接的裸片间连接。每个dram裸片110中的八个存储体b[7:0]表示连接到水平存储器裸片数据端口125的存储体的一个集合。在该实施例中,存储体分组是通过将来自b[3:0]的突发与来自对面存储体b[7:4]的突发进行交错来实现的。如图1的左侧所示,对于一对dram存储体b[7,3],每个存储体包括行解码器150和列解码器155。链路160以dram核心频率传送读取和写入数据。存储体的每个集合包括四个裸片间数据端口140,在加速器瓦片acc[3:0]中的一个加速器瓦片紧下方的每对存储体有一个裸片间数据端口140。在最右边的实例中,例如,竖直的裸片间连接145将加速器瓦片acc0连接到裸片间数据端口140,裸片间数据端口140用于为裸片堆叠中的四个底层dram裸片110中的每个中的存储体对b[4,0]提供服务。因此,瓦片acc0可以快速、节能地访问八个底层存储体。在其他实施例中,竖直可访问的存储体的数目不等于存储体的集合中的存储体的数目。
[0024]
裸片内(水平)和裸片间(竖直)连接可以包括有源组件(例如,缓冲器),并且裸片内信号路径可以包括裸片间分段,反之亦然。如本文中使用的,如果到存储体的连接具有沿dram裸片的平面延伸的距离大于裸片上的dram存储体的最短中心到中心间距的裸片内分段(即,大于存储体间距165),则该连接是“裸片内”连接。如果到存储体的连接使用长度小于存储体间距165的一个或多个裸片内分段(如果有的话)、从一个裸片延伸到另一裸片中的最近的dram存储体,则该连接是“裸片间”连接。
[0025]
图2是图1的设备100的实施例的平面图,其中加速器裸片105包括八个集合并且每个集合有四个瓦片(例如,集合acc[7:4]和acc[3:0]),这里示出了其中的四个集合,并且每个底层dram裸片包括八个集合200并且每个集合有八个存储体b[7:0]。省略了一半的加速器瓦片,以示出最上面的dram裸片110中的八个存储体集合200中的四个;标记为hbm1的虚线边界示出了加速器裸片的被遮蔽部分的hbm界面的位置。子接口120的通路域和底层端口125位于加速器和dram裸片的中,并且由堆叠中的裸片位置隔开,使得每对子接口120仅与底层dram裸片中的一个通信。子接口(伪通道)连接通过最上面的dram裸片的阴影而突出显示;其余三个dram裸片被遮蔽。
[0026]
在该实施例中,加速器裸片105与四个dram裸片110的堆叠结合并且电互连,每个dram裸片支持用于外部主机(未示出)的两个存储器通道。每个外部通道包括两个伪通道,这两个伪通道共享命令和地址基础设施并且经由相应子接口120传送数据。在这个示例中,接口hbm0的子接口120的阴影对中的每个表示伪通道端口,并且该对表示通道端口。每个伪通道进而经由从相应子接口120延伸的一对裸片内连接130提供对存储体sb的两个集合的访问。子接口120中的两个被加阴影以匹配最上面的dram裸片中的对应裸片内连接130以突出显示沿四个伪通道中的两个的数据流。其余三个外部通道中的每个同样经由三个底层但遮蔽的dram裸片中的一个被提供服务。在其他实施例中,设备100包括更多或更少的dram裸片。
[0027]
加速器瓦片acc#可以被描述为相对于彼此并且参考推断方向上的信号流在“上游”或“下游”。例如,瓦片acc0位于瓦片acc1(即,右侧的下一瓦片)上游。对于推理或“前向传播”,信息沿实线箭头移动通过瓦片链,以从最终的下游瓦片acc7出现。对于训练或“后向传播”,信息沿虚线箭头从最终的下游瓦片acc7向最终的上游瓦片acc0移动。在这种情况下,“瓦片”是布置成矩形阵列的处理元件的集合。加速器瓦片可以被放置和互连以实现高效的瓦片间通信。瓦片内的处理元件可以作为脉动阵列操作,如下详述,在这种情况下,瓦片可以“链接”在一起以形成更大的脉动阵列。
[0028]
每个加速器瓦片acc#包括四个加速器端口,前向传播和后向传播每个各有两个加速器端口。图2右上角的键示出了在每个瓦片120中标识前向传播输入端口(fwdin)、前向传播输出端口(fwdout)、后向传播输入端口(bpin)和后向传播输出端口(bpout)的阴影。(该键不适用于图2中的其他阴影元素。)瓦片acc#被定向为使连接距离和伴随的传播延迟最小化。在一些实施例中,每个加速器瓦片包括可以并发处理和更新来自上游和下游处理元件和瓦片的部分结果以支持并发的前向和后向传播的处理元件。
[0029]
图3是包括外部接口hbm0和加速器瓦片acc0和acc3的图1和图2的加速器裸片105的一部分的框图。裸片105使用包括一对子接口120(如前详述)和命令/地址(ca)接口300的外部通道接口进行外部通信。每个加速器瓦片acc#包括两个半部瓦片305,每个半部瓦片305具有乘累加器(mac或mac单元)的64
×
32阵列,每个乘累加器计算两个数字的乘积并且将该乘积与累加值相加。(合适的mac在下面详述。)每个瓦片中的存储器控制器310管理沿与通路域135相关联的裸片间通道的dram访问。控制器310被标记为“seq”以表示“定序器”,它指的是生成地址序列以通过微程序的简单且高效的控制器类。在这个实施例中,mac单元执行重复的顺序操作,这些操作不需要更复杂的控制器。
[0030]
裸片105另外包括通道仲裁器315、分级缓冲器320和控制器325。hbm ca接口300从外部主机(未示出)接收命令和地址信号。通道仲裁器315在左右分级缓冲器320之间关于服务于那些命令进行仲裁。如果只有一个分级缓冲器连接到通道,则不需要通道仲裁器。所描绘的分级缓冲器320缓冲去往和来自加速器瓦片acc0的数据,以实现速率匹配,使得从加速器裸片105读取数据突发和向加速器裸片105写入数据突发可以与通过加速器瓦片中的mac阵列的数据的常规流水线移动相匹配。
[0031]
主机控制器(未示出)可以使用多种方法来改变加速器裸片105的操作模式,其中一些方法在下面讨论。分级缓冲器320和控制逻辑325(可以针对每个外部通道将其中的一个设置在加速器裸片上)监视主机控制器与定序器310之间的控制切换状态以管理内部和外部操作模式。定序器310可以等待可编程时段,以便主机控制器放弃控制。在一种模式下,加速器瓦片在定序器310的控制下被提供对dram存储体的底层堆叠的直接访问。在另一种模式下,加速器瓦片被禁止访问底层dram存储体以实现不同组件(例如,替代的加速器瓦片、控制逻辑325、或加速器裸片外部的控制器)对那些底层存储体的无冲突访问。在另一种模式下,加速器瓦片在定序器310的控制下被提供对dram存储体的底层堆叠的第一部分的直接访问,并且被禁止访问dram存储体的底层堆叠的第二部分以实现对第二部分的无冲突外部访问。所选择的模式可以应用于任何数目的加速器瓦片,从一个到全部。在存储器裸片是dram的实施例中,维护操作(例如,刷新和周期性校准)可以由有源的外部或内部存储器控制器(例如,主机或(多个)定序器310)管理。每个定序器310还可以监视非维护存储器操
作(例如,写入和预充电序列是否完成),使得层的控制可以例如切换到另一本地或远程控制器。在定序器310控制下的竖直通道数据路径可以具有与hbm通道数据路径不同的数据速率,例如通过不使用存储体分组或通过在hbm通道数据路径的串行器/解串器链内部进行多路复用。
[0032]
图4a是根据实施例的包括加速器裸片405和一对dram裸片dd0和dd1的3-d asic 400的框图。这些裸片如右下方的横截面所示堆叠,但为了便于说明而单独描绘。
[0033]
加速器裸片400包括表示图1的裸片105的方面的多个功能块。用于“直接通道a”的块dca为加速器裸片405提供对相应裸片dd0和dd1中的存储体sb0l0和sb0l1的底层集合的竖直的两裸片堆叠的访问。块dcb类似地提供对存储体sb1l0和sb1l1的底层集合的直接访问。用于“伪通道级别0”的块pcl0为加速器裸片400提供对裸片dd0上的存储体sb0l0和sb1l0的两个集合的访问,而块pcl1类似地提供对裸片dd1上的存储体sb0l1和sb1l1的两个集合的访问。加速器裸片405上的数据多路复用器dmux和命令/地址多路复用器cmux的集合引导相关信号。
[0034]
该框图示出了如何在加速器裸片405内管理数据和命令/地址信号以在如上文详述的那些等内部和外部访问模式下访问底层dram裸片dd0和dd1。在各个元素之间延伸的实线示出了数据流;虚线示出了命令和地址信号流。伪通道pcl0和pcl1以及相关信号线使用粗线突出显示,以说明其中主机控制器(未示出)经由伪通道访问dram裸片dd0和dd1的外部访问模式下的信号流。块pcl0和pcl1提供对相应dram裸片dd0和dd1上的存储体的集合的访问。
[0035]
图4b再现了图4a的框图400,但是直接通道块dca和dcb以及相关信号线使用粗线突出显示以说明内部访问模式下的信号流,在内部访问模式下,加速器裸片405上的加速器瓦片(未示出)访问dram裸片dd0和dd1。回顾一下,dram裸片dd0和dd1竖直堆叠在加速器裸片405下方,块dca提供对dram裸片dd0和dd1上的存储体集合sb0l0/sb0l1的竖直堆叠的访问,而块dcb提供对存储体集合sb1l0/sb1l1的类似竖直堆叠的访问。
[0036]
图5描绘了根据另一实施例的3-d asic 500。asic 500类似于图1的设备100,相同地标识的元素相同或相似。在该实施例中,dram裸片510也被修改以支持到加速器瓦片acc[3:0]的相对直接的裸片间连接。在该架构中,存储体分组的实现方式不同,其中来自远离hbm通道的b[3:0]的突发与来自靠近hbm通道的b[7:4]的突发交错。dram存储体以dram核心频率通过数据通道515将数据传送到位于存储体集合的中间的存储体组逻辑520。在两个存储体组之间交错的数据沿连接到存储体组逻辑520的水平存储器裸片数据端口125中的相应一个进行传送。除此以外,asic 500以类似于图1和图2的设备100的方式操作。
[0037]
图6a描绘了计算机系统600,其中具有主机处理器610的片上系统(soc)605可以访问先前详述的类型的3-d处理设备100。尽管从较早的图中省略,但处理设备100包括可选的基础裸片612,例如,该基础裸片612可以在制造过程中支持dram堆叠的测试功能、分配功率,以及将堆叠的ballout从堆叠内ballout改变为外部微凸块。这些和其他功能可以包含在加速器裸片105上,或者加速器裸片和基础裸片105和612两者的工作可以在它们之间不同地分布。
[0038]
回顾图2的讨论,设备100支持八个hbm通道,处理器610设置有八个存储器控制器mc[7:0],每个hbm通道有一个存储器控制器。存储器控制器mc[7:0]可以是定序器。soc 605
还包括用于与设备100接口的物理层(phy)615。soc 605另外包括或经由硬件、软件或固件支持堆叠控制逻辑620,堆叠控制逻辑620以下面详述的方式管理设备100的模式选择。从soc 605到设备100的控制切换时间可以随通道而变化,刷新和维护操作由定序器310为处于内部访问模式的通道处理。在加速器裸片105中可能不需要全局时钟同步,尽管各种瓦片内的逻辑可以是本地同步的。
[0039]
处理器610支持八个独立的读/写通道625,每个外部存储器控制器mc[7:0]有一个读/写通道,读/写通道根据需要来传送数据、地址、控制和定时信号。在该上下文中,“外部”是指设备100,并且用于区分与设备100集成(在设备100内部)的控制器(例如,定序器)。在该示例中,存储器控制器mc[7:0]及其相应phy 615部分支持八个hbm通道630——每个dram裸片110两个通道——传送符合与hbm dram裸片110相关的hbm规范的数据、地址、控制和定时信号。在外部访问模式下,设备100以hbm存储器所期望的方式与soc 605交互。
[0040]
图6b描绘了实施例中的系统600,其中soc 605通过插入器640与设备100通信,插入器640具有蚀刻在硅中的精细间隔的迹线645。hbm dram支持具有宽接口的高数据带宽。在一个实施例中,hbm通道630包括1,024条数据“线”和数百条用于命令和地址信号的“线”。使用中介层640是因为标准印刷电路板(pcb)无法管理必要的连接密度。中介层640可以扩展为包括附加电路系统,并且可以安装在某种其他形式的基板上,以用于互连到例如功率供应线和设备100的其他实例。
[0041]
右侧的加速器裸片105的平面图描绘了在图3的前述讨论中介绍的半部瓦片305和定序器310。在该示例中,外部模式可以称为“hbm模式”,因为设备100在该模式下作为常规hbm存储器而执行。处理器610可以采用hbm模式来向dram堆叠加载训练数据。处理器610然后可以向设备100发出指令,该指令引导加速器裸片105进入加速器模式并且执行学习算法,该学习算法确定被优化以实现期望结果的一个或多个函数。该学习算法采用定序器310、控制器325和经由通孔域135提供的裸片间连接来访问底层dram存储体中的训练数据和神经网络模型参数并且存储中间和最终输出。加速器裸片105还使用定序器310将在优化期间确定的参数存储在dram神经网络中。学习算法可以在很少或没有来自soc 605的干扰下进行,它可以类似地串联地引导多个神经网络。处理器610可以周期性地读取设备100上的误差寄存器(未示出)以监视学习算法的进度。当一个或多个误差达到期望水平,或未能随着时间进一步减少时,处理器610可以向设备100发出指令以返回hbm模式并且读出优化的神经网络参数——有时称为“机器学习模型”——以及其他感兴趣的数据。
[0042]
在一些实施例中,设备100仅处于一种模式或另一种模式。其他实施例支持更细粒度的模态,以允许不同存储体由不同的外部和内部存储器控制器引导,同时避免存储体冲突。在图6a和图6b的示例中,堆叠控制逻辑620管理八个通道625中的每个的访问模式,并且因此管理到设备100的hbm通道630的访问模式。例如,参考图2的实施例,与接口hbm0相关联的四个外部通道可以处于hbm模式,以允许主机处理器访问加速器裸片下的存储体的16个集合(每个dram裸片有4个存储体);而与接口hbm1相关联的四个外部通道被禁用,以有利于存储体的其他16个集合上方的加速器瓦片(未示出)直接访问存储体。
[0043]
处理器610可以使用多种方法来改变设备100的操作模式。这些包括发出指令以加载控制与受影响的一个或多个瓦片相关联的定序器310的每通道或每瓦片(加速器瓦片)寄存器。也可以使用孔径式访问,在这种情况下,加速器瓦片可以映射到dram存储体的地址之
外的虚拟地址空间。附加的引脚、迹线和地址域可以容纳附加地址。在一些实施例中,系统600包括通过ieee 1500边带通道而访问的全局模式寄存器,该ieee 1500边带通道允许地址空间所有权在外部主机处理器610(例如,每通道625)与加速器裸片105内的定序器310之间转移。神经网络训练和推理操作是确定性的,使得在系统600被指派对训练数据集合进行机器学习之前,可以由编译器设置划分dram地址空间以用于外部和内部访问的模式选择。这种控制切换可能相对不频繁,并且因此对性能的影响很小。
[0044]
在一个实施例中,每个dram裸片110发出“就绪”信号,以指示裸片何时不使用。外部存储器控制器mc[7:0]使用该状态信息来确定dram裸片110何时未被加速器裸片105使用并且因此可用于外部访问。存储器控制器mc[7:0]控制例如对不受内部控制器控制的dram存储体或裸片的刷新操作。加速器裸片105可以在每通道的基础上将控制权交还给主机处理器,“每通道”是指来自外部控制器mc[7:0]的八个外部通道中的一个。在一个实施例中,每个定序器310监视来自底层dram裸片的每层就绪信号以进行控制切换。每个dram裸片的控制切换可以在不同时间进行。在一个实施例中,为了放弃对与给定外部通道相关联的存储体的控制,加速器裸片105上的控制器325经由该通道向对应的主机存储器控制器mc#发出就绪信号。处理器610然后使用例如用于与相关定序器310通信的上述方法中的一个来重新获取控制权。在切换过程中,分级和控制逻辑320/325监视控制切换状态并且与所有瓦片定序器310通信。主机存储器控制器mc#可以等待可编程时段,以便所有定序器310放弃控制。刷新和维护操作在切换之后由主机存储器控制器mc#处理。
[0045]
由控制器325发出的就绪信号可以是异步的、脉宽调制(pwm)全局信号,该信号指示例如某个神经网络学习过程(例如,将误差降低到指定水平,误差稳定在相对稳定的值上,或者训练数据耗尽)的成功完成。内部误差状态(而不是成功完成)可以使用不同脉冲宽度来被传送。soc 605可以实现超时,然后是状态寄存器读取和误差恢复,以处理未断言就绪信号的不可预见误差。soc 605还可以周期性地读取状态寄存器,例如训练误差。状态寄存器可以在每瓦片的基础上集成到加速器瓦片105中和/或作为加速器瓦片的组合状态寄存器。
[0046]
图7a描绘了地址域700,地址域700可以由主机处理器发出以加载加速器裸片105中的寄存器以控制模式。“堆叠#”域将设备100标识为一组类似设备中的一个;“通道#”域标识通过其访问寄存器的通道和伪通道;“瓦片#”域标识一个或多个目标加速器瓦片;并且寄存器域“寄存器#”标识控制一个或多个目标瓦片的操作模式的一个或多个寄存器的地址。例如,控制给定瓦片的一位寄存器可以被加载有逻辑1或0,以分别将对应定序器310(图3)设置为外部或内部访问模式。
[0047]
图7b描绘了可以被主机处理器使用用于孔径式模式选择的地址域705。堆叠#和通道#域如前所述。行、存储体和列域表示通常与dram地址空间相关联的位,但对于模式选择,它们被设置为该空间之外的值。加速器裸片105包括可以响应于这些地址而被选择的寄存器。
[0048]
返回到图6a和图6b,外部存储器控制器mc[7:0]独立地访问八个存储器通道,四个dram裸片110中的每个有两个hbm通道630。每个hbm通道继而提供对同一dram裸片110上的4个存储体组的访问,每个存储体组具有8个存储体,或总共32个存储体。另一方面,每个定序器310提供对四个dram裸片110中的每个上的2个存储体或总共8个存储体的访问。因此,对
于外部和内部访问模式,地址映射可以不同。
[0049]
图7c描绘了两个地址域,即,可以由主机处理器发出以在hbm模式下访问dram页的外部模式地址域710、以及可以由内部存储器控制器使用用于类似访问的内部模式地址域715。在外部地址映射方案中,地址域710指定堆叠和通道,如前所述,并且另外,还指定存储体组bg、存储体、行和列以访问dram页面。内部地址映射方案不同于外部地址映射方案。地址域710省略了堆叠,只有一个,并且包括层#域以从可用dram存储体的底层竖直堆叠中的四个层中进行选择。较大的竖直通道可以跨多个层被拆分,例如,在这个四个dram示例中,是四个中的两个。
[0050]
内部模式地址域715允许内部控制器选择底层dram裸片中的任何列。在每个加速器瓦片可以访问同一设备100上可用的存储体子集的实施例中,地址域715可以具有更少的位。参考图1,在一个实施例中,每个加速器瓦片acc#只能访问正下方的存储体堆叠(例如,瓦片acc0只能访问四个dram裸片110中的存储体b0和b4的堆叠)。存储体组和存储体域bg和存储体因此可以简化为用于区分指定层中的存储体b0和b4的单个存储体位。
[0051]
图8示出了用于人工神经网络的专用集成电路(asic)800,其架构使处理元件与存储器(例如,堆叠的存储器裸片)之间的连接距离最小化,并且从而提高了效率和性能。asic 800还支持用于训练的小批次和流水线、并发的前向和后向传播。小批次将训练数据拆分为小“批次”(迷你批次),而流水线和并发的前向和后向传播通过同时传播前向训练样本同时后向传播先前训练样本的调节来支持快速高效的训练。
[0052]
asic 800使用八通道接口chan[7:0]与外部通信,该八通道接口可以是前面讨论的类型的hbm通道。靠近每个通道接口的一对分级缓冲器815缓冲进出存储器核心(未示出)的数据。缓冲器815实现了速率匹配,使得通过八通道接口chan[7:0]从瓦片820读取和向瓦片820写入的数据突发可以与加速器瓦片820阵列的常规流水线移动相匹配。瓦片内的处理元件可以作为脉动阵列操作,如下详述,在这种情况下,瓦片可以“链接”在一起以形成更大的脉动阵列。缓冲器815可以经由一个或多个环形总线825互连以增加灵活性,例如以允许将来自任何通道的数据发送到任何瓦片,并且支持其中网络参数(例如,权重和偏差)被分区使得处理发生在神经网络的某些部分上的用例。以相反方向传送信号的环形总线可以提高容错性和性能。
[0053]
asic 800被划分为八个通道,每个通道可以用于小批次处理。一个通道包括一个通道接口chan#、一对分级缓冲器815、一系列加速器瓦片820和支持存储器(未示出)。这些通道在功能上相似。以下讨论仅限于以虚线边框为界的左上通道chan6。标记为“i”(用于“输入”)的加速器瓦片820从缓冲器815中的一个接收输入。该输入瓦片820在左侧的下一瓦片820上游。对于推理或“前向传播”,信息沿实线箭头移动通过瓦片链820,以从标记为“o”(用于“输出”)的最终的下游瓦片到另一分级缓冲器815出现。对于训练或“后向传播”,信息沿虚线从标记为“o”的最终的下游瓦片移动,以从标记为“i”的最终的上游瓦片显露。
[0054]
每个瓦片820包括四个端口,前向传播和后向传播每个各有两个加速器端口。图8左下角的键示出了在每个瓦片820中标识前向传播输入端口(fwdin)、前向传播输出端口(fwdout)、后向传播输入端口(bpin)和后向传播输出端口(bpout)的阴影。在其中瓦片820可以占据3d-ic的不同层的实施例中,瓦片820被定向以使连接距离最小化。如下详述,每个瓦片820包括处理元件阵列,每个处理元件可以并发处理和更新来自上游和下游处理元件
和瓦片的部分结果以支持并发的前向和后向传播。在这个实施例中,每个小瓦片820与个体存储体的竖直堆叠重叠。然而,加速器瓦片的大小可以设置为重叠存储体对的堆叠(如图1的示例中所示)或其他数目的存储体的堆叠(例如,每裸片四个或八个存储体)。通常,每个存储器占据存储体区域,并且一个加速器瓦片占据的瓦片区域基本等于整个数目的存储体区域的区域。
[0055]
图9示出了被互连以支持并发的前向和后向传播的四个加速器瓦片820。细的、平行的箭头集合表示通过这四个瓦片820的前向传播路径。块状箭头表示后向传播路径。在该示例中,前向和后向传播端口fwdin、fwdout、bpin和bpout是单向的,并且前向和后向传播端口集合可以并发使用。前向传播以顺时针方向从左上瓦片开始穿过瓦片820。后向传播从左下方逆时针进行。
[0056]
图10包括在单个加速器瓦片820上实例化的神经网络的功能表示1000和阵列1005。表示1000和阵列1005示出了前向传播,并且为了便于说明而省略了后向传播端口bpin和bpout。下面分别详详述后向传播。
[0057]
功能表示1000是典型的神经网络。数据从左侧传入,由一层神经元o1、o2和o3表示,每个神经元从一个或多个上游神经元接收相应部分结果。数据从右边离开,由另一层神经元x1、x2、x3和x4表示,它们传达了它们自己的部分结果。神经元通过加权连接w
ij
(有时称为突触)被连接,其权重在训练中确定。每个权重的下标引用连接的起点和终点。神经网络按照图10所示的等式计算每个输出神经元的乘积之和。偏差项b#引用了偏差神经元,为了便于说明,偏差神经元在此处省略。偏差神经元及其使用是众所周知的,因此省略了详细讨论。
[0058]
加速器瓦片820的阵列1005是处理元件1010、1015和1020的脉动阵列。在脉动阵列中,数据以逐步方式从一个处理元件传输到下一处理元件。对于每个步骤,每个处理元件计算部分结果作为从上游元件接收的数据的函数,存储部分结果以预期下一步,并且将结果传递给下游元件。
[0059]
元件1015和1020执行与每个功能表示1000的前向传播相关联的计算。此外,元件1010中的每个执行激活函数,该激活函数以本公开充分理解和不必要的方式变换该节点的输出。在表示1000中表示为神经元的层在数组1005中被描绘为数据输入和输出,所有计算由处理元件1010、1015和1020执行。处理元件1015包括简单的累加器,累加器将偏差添加到累加的值,而元件1020包括mac,每个mac计算两个数字的乘积并且将该乘积与累加值相加。在其他实施例中,每个处理元件1020可以包括一个以上的mac,或与mac不同的计算元件。如下详述,处理元件1010、1015和1020支持流水线式和并发的前向和后向传播,以使空闲时间最小化并且因此提高硬件效率。
[0060]
图11a描绘了处理元件1100,它是适合用作图10的每个处理元件1020的电路系统的示例。元件1100支持并发的前向和后向传播。为了支持前向传播而提供的电路元件使用粗线宽突出显示。右下方的图1105提供了元件1100在前向传播状态之间转变的功能描述。首先,元件1100接收来自上游瓦片的部分和oj和来自上游处理元件的前向传播部分结果∑f(如果有的话)作为输入。在一个计算周期之后,处理元件1100产生已更新部分结果∑f=∑f+oj*w
jk
,并且将部分和oj传递给另一处理元件1100。例如,参考图10的阵列1005,标记为w
22
的处理元件1020将部分和传递给标记为w
32
的下游元件,并且将输出o2中继到标记为w
23
的元件。
[0061]
返回图11a,作为对前向传播的支持,处理元件1100包括一对同步存储元件1107和1110、前向传播处理器1115、以及用于存储用于计算部分和的加权值或权重w
jk
的本地或远程存储装置1120。处理器1115(mac)计算前向部分和并且将结果存储在存储元件1110中。为了支持后向传播,处理元件1100包括另一对同步存储元件1125和1130、后向传播mac 1135、以及用于存储在训练期间使用以更新权重w
jk
的值alpha的本地或远程存储装置1140。
[0062]
图11b描绘了图11a的处理元件1100,其具有为支持后向传播而提供的电路元件,使用粗线宽突出显示。右下方的图1150提供了元件1100在后向传播状态之间转变的功能描述。元件1100接收来自下游瓦片的部分总和pk和来自下游处理元件的后向传播部分结果∑b(如果有的话)作为输入。在一个计算周期之后,处理元件1100向上游处理元件1100产生已更新部分结果∑b=∑b+alpha*pk*oj*w
jk
。alpha通过控制响应于估计的误差而改变权重的程度来指定学习速率。
[0063]
图12描绘了与图11a和图11b的处理元件1100相似的处理元件1200,其中相同地标识的元素相同或相似。为后向传播服务的mac 1205包括四个乘法器和两个加法器。mac 1205存储两个学习速率值alpha1和alpha2,它们可以不同地调节后向传播计算。对于每个计算,可能需要添加比例因子来强调或不强调计算对旧值的影响程度。在其他实施例中,处理元件可以具有更多或更少的乘法器和加法器。例如,可以通过重用硬件(例如,乘法器或加法器)来简化处理元件1200,尽管这样的修改可能会降低处理速度。
[0064]
图13示出了在通过图12的加速器瓦片1200的后向传播期间的信息流。对于后向传播,在神经网络的最后一层执行的计算不同于所有其他层的计算。等式可能因实现而异。以下示例说明了用于输出层以外的层的硬件,因为它们需要更多的计算。
[0065]
简单的神经网络1300表示包括输入层x[2:0]、隐藏层y[3:0]和输出层z[1:0],以产生误差e[1:0]。输出层的神经元z0(神经元也称为“节点”)在左下方示出为划分为net
z0
和out
z0
。隐藏层的神经元y0在右下方示出为划分为net
y0
和out
y0
。每个神经元设置有相应偏差b。为了便于说明,该图形表示表示支持如本文详述的并发的前向和后向传播的处理元件的收缩阵列(例如,图10的元件1020以及图11和图12的元件1100和1200)。
[0066]
后向传播的输出层计算使用上一步的总误差。以数学方式表示n个输出outo:
[0067][0068]
在网络1300中,n=2。每个权重的梯度是基于权重对总误差e
total
的贡献而针对每个权重来计算的。
[0069]
对于每个输出节点o{
[0070]
对于连接到输出节点o的每个传入权重/偏差{
[0071]
使用链式法则确定权重/偏差的误差贡献并且对其进行调节。该图假定例如sigmoid激活函数,其导数是下面的等式4。考虑来自输出节点z0的总误差e
total
:
[0072]
[0073][0074][0075][0076][0077]
}
[0078]
}
[0079]
后向传播的隐藏层计算也是基于总误差,但等式不同。例如,一个实施例的工作方式如下:对于每个隐藏节点y{
[0080]
使用链式法则确定权重的误差贡献并且对其进行调节:
[0081][0082][0083][0084][0085][0086][0087]
}
[0088]
}
[0089]
如果神经网络有多个隐藏层,则误差项e
total
是下一层节点处的误差,这可以通过
节点的实际输出与期望输出之间的差异来计算。当调节下一层时,在上一次迭代中计算期望输出。
[0090]
后向传播从输出到输入起作用,因此在计算当前层的调节时,前一层的调节是已知的。该过程可以被概念化为三层节点之上的滑动窗口,其中查看最右边层的误差并且使用它们来计算对进入窗口的中间层的权重的调节。
[0091]
虽然前述讨论考虑了神经网络加速器裸片与dram存储器的集成,但其他类型的紧密集成的处理器和存储器可以受益于上述模式和通道的组合。例如,更多或更少的dram裸片可以包括附加的堆叠加速器裸片,加速器裸片或加速器瓦片的子集可以用一个或多个图形处理裸片代替或补充,并且一个或多个dram裸片可以用不同类型的动态或非易失性存储器替换或补充。本领域普通技术人员在阅读本公开之后将很清楚这些实施例的变化。此外,一些组件示出为直接彼此连接,而其他组件示出为通过中间组件连接。在每种情况下,互连或“耦合”方法在两个或更多个电路节点或端子之间建立某种期望电通信。如本领域技术人员将理解的,这种耦合通常可以使用多种电路配置来实现。因此,所附权利要求的精神和范围不应限于前述描述。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1