存储器器件及其操作方法与流程
1.本技术的实施例涉及存储器器件及其操作方法。
背景技术:
2.存储器中计算(cim)系统和方法将信息储存在存储器器件的存储器(诸如随机存取存储器(ram))中,并在存储器器件中执行计算,这与在存储器器件和用于各种计算步骤的另一种器件之间移动数据相反。在cim系统和方法中,从存储器器件存取所储存的数据比从其他存储器器件存取所储存的数据更快。此外,数据在存储器器件中的分析速度更快,从而能够在诸如卷积神经网络(cnn)的商业应用和机器学习应用中更快地进行报告和决策。cnn,也称为卷积网络,是一类人工神经网络,其专门处理具有网格状拓扑的数据,诸如包含视觉图像的二进制表示的数字图像数据。数字图像数据包括以网格状拓扑排列的像素,其包含表示图像特征的值,诸如颜色和亮度。cnn通常用于分析图像识别应用中的视觉图像。正在努力提高cim系统和cnn的性能。
技术实现要素:
3.根据本技术的实施例的一个方面,提供了一种存储器器件,包括:乘法单元,被配置为接收第n层的数据和权重,其中n为正整数,并将数据乘以权重以提供乘法结果;以及可配置求和单元,由第n层值配置以接收第n层数量的输入并执行第n层数量的加法,可配置求和单元对乘法结果求和并提供可配置求和单元输出。
4.根据本技术的实施例的另一个方面,提供了一种存储器器件,包括:存储器阵列,包括存储器元件;以及存储器中计算电路,位于存储器器件中并且电耦合到存储器阵列。存储器中计算电路包括:乘法单元,从存储器阵列接收第n层的权重和数据输入,其中n为正整数,乘法单元将每个数据输入与权重中的相应一个交互以提供交互结果;可配置求和单元,通过第n层被配置为对交互结果求和并提供求和结果;池化单元,池化求和结果;和缓冲器,将池化结果反馈给乘法单元以计算第n层的下一层,其中缓冲器在所有n层完成之后输出结果。
5.根据本技术的实施例的又一个方面,提供了一种存储器中计算方法,包括:根据第n层从存储器阵列获取权重,其中n为正整数;通过乘法单元将每个数据输入与权重中的相应一个进行交互,以提供交互结果;对可配置求和单元进行配置以接收第n层数量的输入并执行第n层数量的加法;以及通过可配置求和单元对交互结果进行求和以提供求和输出。
附图说明
6.当结合附图进行阅读时,从以下详细描述可最佳理解本发明的各个方面。应该强调,根据工业中的标准实践,各个部件未按比例绘制并且仅用于说明的目的。实际上,为了清楚的讨论,各个部件的尺寸可以任意地增大或减小。另外,附图被示出为本公开的实施例的示例,并且意在进行限定。
7.图1是示意性地示出根据一些实施例的包括位于存储器器件电路上方或顶部上的存储器阵列的存储器器件的图。
8.图2是示意性地示出根据一些实施例的电耦合到存储器器件电路的dram存储器阵列的图。
9.图3是示意性地示出根据一些实施例的包括电耦合到cim存储器器件中的存储器阵列的cim电路的cim存储器器件的示例的图。
10.图4是示意性地示出根据一些实施例的存储器阵列和对应的cim电路的图。
11.图5是示意性地示出根据一些实施例的存储器阵列的1t-1c存储器元件的存储器元件的图。
12.图6是示意性地示出根据一些实施例的cnn的至少部分的图。
13.图7是示意性地示出根据一些实施例的存储器阵列和cim电路的图,存储器阵列和cim电路可以被配置为确定cnn中不同卷积层的输出。
14.图8是示意性地示出根据一些实施例的图7的cim电路的操作流程的图。
15.图9是示意性地示出根据一些实施例的确定cnn中卷积层的求和结果的方法的图。
具体实施方式
16.以下公开内容提供了许多用于实现本发明的不同特征不同的实施例或实例。下面描述了组件和布置的具体实施例或实例以简化本发明。当然,这些仅是实例而不旨在限制。例如,在以下描述中,在第二部件上方或者上形成第一部件可以包括第一部件和第二部件直接接触形成的实施例,并且也可以包括在第一部件和第二部件之间可以形成额外的部件,从而使得第一部件和第二部件可以不直接接触的实施例。此外,本发明可以在各个示例中重复参考数字和/或字母。该重复是为了简单和清楚的目的,并且其本身不指示讨论的各个实施例和/或配置之间的关系。
17.此外,为了便于描述,本文中可以使用诸如“在
…
下方”、“在
…
下面”、“下部”、“在
…
上面”、“上部”等的间隔关系术语,以描述如图中所示的一个元件或部件与另一元件或部件的关系。除了图中所示的方位外,间隔关系术语旨在包括器件在使用或操作工艺中的不同方位。器件可以以其它方式定位(旋转90度或在其它方位),并且在本文中使用的间隔关系描述符可以同样地作相应地解释。
18.本公开涉及存储器并且更具体地涉及包括至少一个可编程或可配置求和单元的cim系统和方法。可配置求和单元可以在cim系统的操作期间被编程或被设置以使用不同数量的求和单元(诸如加法器树中的加法器)处理不同数量的输入,并且在一些实施例中,提供不同数量的加法器的输出。在一些实施例中,cim系统和方法用于cnn,诸如用于加速或改进cnn的性能。
19.通常,cnn包括输入层、输出层和隐藏层,隐藏层包括多个卷积层、池化层、全连接层和归一化层。其中卷积层可以包括执行卷积和/或执行互相关。在cnn中,对于不同的层,诸如对于不同的卷积层,输入数据的尺寸往往是不同的。此外,对于不同的卷积层,权重值、过滤器/内核值和其他操作数的数量通常是不同的。结果,求和单元的尺寸(诸如加法器树中的加法器的数量)、输入的数量和/或输出的数量对于不同的层(诸如对于不同的卷积层)通常是不同的。然而,传统的cim电路具有基于存储器阵列的尺寸的固定配置,使得它们不
提供对输入的数量和/或加法器中的加法器的数量进行调整。
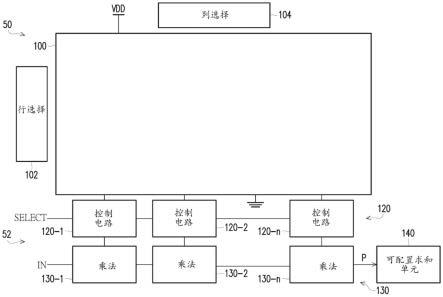
20.所公开的实施例包括存储器电路,存储器电路包括位于一个或多个位于cim逻辑电路之上或顶部上的存储器阵列,即,一个或多个cim逻辑电路位于存储器阵列之下。在一些实施例中,耦合到cim逻辑电路的存储器阵列是动态随机存取存储器(dram)阵列、电阻随机存取存储器(rram)阵列、磁阻随机存取存储器(mram)阵列和相变随机存取存储器(pcram)阵列中的一种或多种。在其他实施例中,存储器阵列可以位于一个或多个cim逻辑电路下方或下面。
21.所公开的实施例还包括存储器电路,存储器电路包括至少一个可编程的可配置求和单元,使得它可以在cim系统的操作期间被编程或被设置。在一些实施例中,在cim系统的操作期间为每个不同的卷积层设置至少一个可配置求和单元以使用不同数量的求和单元(例如加法器树中的加法器)适应(即处理)不同数量的输入,和/或为不同的卷积层提供不同数量的输出。
22.在一些实施例中,cim系统可以使用相同的可配置求和单元对cnn的不同层中的每个(包括不同卷积层中的每个)进行计算。在一些实施例中,在cnn的第一层中,诸如乘法单元的单元将输入数据与诸如内核/滤波器权重的权重进行交互。交互结果被输出到对交互结果进行求和的可配置求和单元,并且在一些实施例中,提供比例调节求和结果和非线性激活函数中(诸如整流非线性单元(relu)函数)的一个或多个。接下来,对来自可配置求和单元的数据执行池化以减小数据的尺寸,并且在池化之后,将输出反馈给用于将数据与权重进行交互的单元,以完成cnn的下一层。一旦完成了cnn的所有层的所有计算,就输出结果。本公开的实施例可以在多个不同的技术世代中使用,诸如在多个不同的技术节点处使用。此外,本公开的实施例可以适用于除了cnn之外的应用。
23.该架构的优点包括具有可配置求和单元,该可配置求和单元可以支持可变数量的输入、加法器和输出。可以对于cnn的不同层中的每个(诸如不同卷积层中的每个)编程或设置可配置求和单元,包括设置输入的数量、求和的数量或加法器的数量以及输出的数量,使得从第一层到最后一层的每个不同层的计算都可以由一个存储器器件中的一个可配置求和单元完成。此外,这种架构能够使执行cnn功能的cim系统具有更高的存储器容量,诸如加速或提高cnn的性能。
24.图1是示意性地示出根据一些实施例的包括位于存储器器件电路24之上或顶部上的存储器阵列22的存储器器件20的图。在一些实施例中,存储器器件20是包括存储器器件电路24的cim存储器器件,存储器器件电路24被配置为为诸如cnn应用的应用提供功能。在一些实施例中,存储器器件20包括存储器阵列22,存储器阵列22是位于作为前端制程(feol)电路的存储器器件电路24上方的后端制程(beol)存储器阵列。在其他实施例中,存储器阵列22可以位于存储器器件电路24的相同层或位于存储器器件电路24下方/下面。
25.存储器阵列22是dram存储器阵列,其包括多个一晶体管、一电容器(1t-1c)dram存储器阵列26。在其他实施例中,存储器阵列22可以是不同类型的存储器阵列,诸如rram阵列、mram阵列和pcram阵列。在其他实施例中,存储器阵列22可以是静态随机存取存储器(sram)阵列。
26.存储器件电路24包括字线驱动器(wldv)28、感测放大器(sa)30、列选择(cs)电路32、读取电路34和cim电路36。wldv 28和sa 30位于dram存储器阵列26正下方并且电耦合到
dram存储器阵列26。cs电路32和读取电路34位于dram存储器阵列26的占用空间之间并且电耦合到sa 30。读取电路34中的每个包括电耦合到cim电路36的读取端口,cim电路36被配置为从读取端口接收数据。
27.cim电路36包括执行所支持的应用(例如cnn应用)的功能的电路。在一些实施例中,cim电路36包括模数转换器(adc)电路38和至少一个可编程/可配置求和单元40,可编程/可配置求和单元40可以在存储器器件20的操作期间被编程或被设置以使用不同数量的求和单元(诸如加法器树中的加法器)处理不同数量的输入,并提供不同数量的输出。在一些实施例中,cim电路36执行cnn的功能,使得在用于cnn中的每个不同卷积层的存储器器件的操作期间设置至少一个可配置求和单元40,以使用不同数量的求和单元处理不同数量的输入,和/或为不同的卷积层提供不同数量的输出。
28.图2是示意性地示出根据一些实施例的电耦合到存储器器件电路24的dram存储器阵列26的图。存储器器件电路24包括位于dram存储器阵列26正下方并且电耦合到dram存储器阵列26的wldv 28和sa 30。此外,存储器器件电路24包括电耦合到sa 30的cs电路32和读取电路34并且位于dram存储器阵列26的占用空间附近。此外,存储器器件电路24包括cim电路36,cim电路36包括adc电路38和至少一个可编程或可配置求和单元40。
29.在读取操作期间,sa 30感测来自dram存储器阵列26中的存储器元件的电压,并且读取电路34从sa 30获得与从dram存储器阵列26中的存储器元件感测的电压相对应的电压。wldv 28和cs电路32提供用于读取dram存储器阵列26的信号,并且读取电路34在读取端口处输出与由读取电路34从sa 30读取的电压相对应的电压。cim电路36接收来自读取端口的输出电压并执行存储器器件20的功能,诸如用于cnn的功能。在写入操作期间,wldv 28和cs电路32提供用于写入dram存储器阵列26的信号,并且sa 30接收写入dram存储器阵列26的数据。在一些实施例中,读取电路34是电连接到sa 30的单独电路。
30.读取电路34通过读取端口提供与从sa30和dram存储器阵列26读取的电压相对应的输出电压。在一些实施例中,读取端口直接向adc电路38输出电压并且adc电路38向cim电路36中的其他电路提供输出电压。在一些实施例中,读取端口直接向cim电路36中的其他电路(即,除了adc电路38之外的电路)提供输出电压。
31.图3是示意性地示出根据一些实施例的包括电耦合到cim存储器器件50中的存储器阵列100的cim电路52的cim存储器器件50的示例的图。
32.在一些实施例中,cim存储器器件50类似于图1的存储器器件20。在一些实施例中,cim电路52被配置为为诸如cnn应用的应用提供功能。在一些实施例中,存储器阵列100是位于作为feol电路的cim电路52上方的beol存储器阵列。
33.在该示例中,存储器阵列100包括储存cnn权重的多个存储器元件。存储器阵列100和相关电路连接在被配置为接收vdd电压的电源端子和接地端子之间。行选择电路102和列选择电路104连接到存储器阵列100并且被配置为在读取和写入操作期间选择存储器阵列100的行和列中的存储器元件。
34.存储器阵列100包括控制电路120,控制电路120连接到存储器阵列100的位线并且被配置为响应于选择信号select来选择存储器元件。控制电路120包括连接到存储器阵列100的控制电路120-1、120-2
…
120-n。
35.cim电路52包括乘法单元或乘法电路130和可配置求和单元或可配置求和电路
140。输入端子被配置为接收输入信号in,并且乘法电路130被配置为将储存在存储器阵列100中的所选权重与输入信号in相乘以产生多个部分乘积p。乘法电路130包括乘法电路130-1、130-2
…
130-n。部分乘积p被输出到可配置求和单元140,该求和单元140被配置为将部分乘积p相加以产生求和输出。
36.图4是示意性地示出根据一些实施例的存储器阵列100和对应的cim电路52的图。存储器阵列100包括排列成行和列的多个存储器元件200,存储器元件200包括存储器元件200-1、200-2、200-3和200-4。存储器阵列100具有n行,其中n行中的每行具有对应的字线wl,指定为字线wl_0至wl_n-1中的一个。多个存储器元件200中的每个都耦合到其行的字线wl。此外,阵列100的每列具有位线bl和反位线(反相位线)blb。在该示例中,存储器阵列100具有y列,使得位线被指定为位线bl[0]至bl[y-1]以及blb[0]至blb[y-1]。多个存储器元件200中的每个连接到其列中的位线bl中的一个或反位线blb中的一个。
[0037]
sa 122和控制电路120连接到位线bl和反位线blb,并且多路复用器(mux)124连接到sa 122和控制电路120的输出。响应于权重选择信号w_sel,mux 124将从存储器阵列100检索的所选权重提供给乘法电路130。
[0038]
存储器阵列100中的存储器元件200中的每个储存高电压、低电压或参考电压。存储器阵列100中的存储器元件200是1t-1c存储器元件,在1t-1c存储器元件中电压储存在电容器上。在其他实施例中,存储器元件200可以是另一类型的存储器元件。
[0039]
图5是示意性地示出根据一些实施例的存储器阵列100的1t-1c存储器元件200的存储器元件200-1的图。存储器元件200-1具有一个晶体管,诸如金属氧化物半导体场效应晶体管(mosfet)202,以及一个储存电容器204。晶体管202操作为插入在存储器元件200-1的储存电容器204和位线bl之间的开关。晶体管202的第一漏极/源极端子连接到位线bl,并且晶体管202的第二漏极/源极端子连接到电容器204的第一端子。电容器204的第二端子连接到接收参考电压(诸如)的电压端子。存储器元件200-1将信息的位储存为电容器204上的电荷。晶体管202的栅极连接到用于存取存储器元件200-1的字线wl中的一个。在一些实施例中,vdd是1.0伏(v)。在其他实施例中,电容器204的第二端子连接到接收参考电压(诸如地)的电压端子。
[0040]
参考图4,字线wl中的每个连接到多个存储器元件200的多个存储器元件,存储器阵列100的每行具有对应的wl。此外,存储器阵列100的每列包括位线bl和反位线blb。存储器阵列100的第一列包括bl[0]和blb[0],存储器阵列100的第二列包括bl[1]和blb[1],依此类推,直到第y列包括bl[y-1]和blb[y-1]。每个位线bl和反位线blb都连接到列中的每隔一个存储器元件200。因此,存储器阵列100的最左列中所示的存储器元件200-1连接到位线bl[0],存储器元件200-2连接到反位线blb[0],存储器元件200-3连接到位线bl[0],存储器元件200-4连接到反位线blb[0],以此类推。
[0041]
存储器阵列100的每列具有连接到该列的位线bl和反位线blb的sa122。sa 122包括在位线bl和反位线blb之间的一对交叉连接的反相器,第一反相器具有连接到位线bl的输入和连接到反位线blb的输出,以及第二反相器具有连接到反位线blb的输入和连接到位线bl的输出。这导致正反馈回路稳定在位线bl和反位线blb中的一个处于高电压并且位线bl和反位线blb中的另一个处于低电压。
[0042]
在读取操作中,基于由行选择电路102和列选择电路104接收到的地址来选择字线
和位线。存储器阵列100中的位线bl和反位线blb被预充电到高电压(诸如vdd)和低电压(诸如地)之间的电压。在一些实施例中,位线bl和反位线blb被预充电至
[0043]
此外,驱动用于所选行的字线wl以存取储存在所选存储器元件200中的信息。如果存储器阵列100中的晶体管是nmos晶体管,则字线被驱动到高电压以导通晶体管并且将储存电容器连接到对应的位线bl和反位线blb。如果存储器阵列100中的晶体管是pmos晶体管,则字线被驱动为低电压以导通晶体管并将储存电容器连接到对应的位线bl和反位线blb。
[0044]
将储存电容器连接到位线bl或反位线blb,将该位线bl或位线blb上的电荷/电压从预充电电压电平改变为更高或更低的电压。sa 122中的一个将这个新电压与另一个电压进行比较以确定储存在存储器元件200中的信息。
[0045]
在一些实施例中,为了感测该新电压,控制电路120中的一个响应于select信号来选择sa 122,并且将来自位线bl和反位线blb(或参考存储器元件)的电压提供给sa 122。sa 122比较这些电压,并且读取电路(诸如读取电路34中的一个)将输出信号提供给adc电路(诸如adc电路38)。adc电路38向mux 124中的一个提供adc输出,mux 124向乘法电路130中的一个提供mux输出,在乘法电路130中输入信号in与权重信号组合。乘法电路130进一步将部分乘积p提供给可配置求和单元140,可配置求和单元140被配置为将部分乘积p相加以产生可配置求和单元输出。
[0046]
在写入操作中,基于由行选择电路102和列选择电路104接收的地址来选择字线和位线。为了写入诸如存储器元件200-1的存储器元件,字线wl_0被驱动为高以存取储存电容器204,并且通过将位线bl[0]驱动至高或低电压电平而将高电压或低电压写入存储器元件200-1,这将储存电容器204进行充电或放电到所选的电压电平。
[0047]
在一些实施例中,图1的存储器器件20和图3的cim存储器器件50用于执行cnn功能。如上所述,cnn包括多个层,诸如输入层、隐藏层和输出层,其中隐藏层可以包括多个卷积层、池化层、全连接层以及比例调节层或归一化层。
[0048]
图6是示意性地示出根据一些实施例的cnn 300的至少部分的图。cnn 300包括三个卷积(conv)302、304和306以及池化(pool)函数308。在一些实施例中,cnn 300包括更多的卷积和/或更多的池化函数。在一些实施例中,cnn 300包括其他函数,诸如比例调节/归一化函数和/或非线性激活函数(诸如relu函数)。
[0049]
第一卷积302接收输入图像310,输入图像310为224x224x3单元(诸如像素)。此外,第一卷积302包括64个内核/滤波器312,每个内核/滤波器312是用于总共(3x3x3)x 64个权重314的3x3x3单元。求和单元316的输入是利用64个内核/过滤器312对224x224x3输入图像310的3x3x3卷积计算,这得到输出图像318为224x224x64单元。
[0050]
第二卷积304接收为224x224x64单元的输出图像318。此外,第二卷积304包括64个内核/过滤器320,每个内核/滤波器312是用于总共(3x3x64)x64个权重322的3x3x3单元。求和单元324的输入是利用64个内核/过滤器320对224x224x64图像318的3x3x64卷积计算,得到输出图像326为224x224x64单元。
[0051]
池化函数308被配置为接收224x224x64的输出图像326并产生112x112x64单元的尺寸减小的输出图像328。
[0052]
第三卷积306接收尺寸减小的输出图像328,其为112x112x64单元,并且第三卷积
306包括128个内核/滤波器330,每个内核/滤波器330为用于总共(3x3x64)x128个权重332的3x3x3。求和单元334的输入是利用128个内核/滤波器330对112x112x64图像320的3x3x64卷积计算,得到输出图像336为112x112x128单元。在一些实施例中,对于更多卷积和/或更多池化函数继续进行此过程。
[0053]
因此,在输入图像数据的cnn尺寸中,内核/滤波器的尺寸和数量、权重的数量以及输出图像数据的尺寸从一个卷积层到下一个卷积层不同。结果,对于不同的卷积层,求和单元的尺寸和数量(诸如输入的数量)、加法器树中的加法器的数量以及输出的数量通常是不同的。
[0054]
在cnn300中,求和单元316、324和334的输入数据的尺寸从3x3x3单元变化到3x3x64单元,并且结果输出318、326和336的尺寸从224x224x64单元变化到112x112x128单元。因此,对于不同的卷积层,输入数据的尺寸、求和单元或加法器的尺寸和数量以及输出的尺寸是不同的。
[0055]
图7是示意性地示出根据一些实施例的存储器阵列340和cim电路342的图,存储器阵列340和cim电路342可以被编程或被配置为确定cnn(诸如图6的cnn 300)中不同卷积层的输出。在一些实施例中,cim电路342类似于cim电路36(如图1所示)。在一些实施例中,cim电路342类似于cim电路52(如图3所示)。
[0056]
cim电路342包括乘法单元344、可配置求和单元346、池化单元348和缓冲器350。存储器阵列340电耦合到乘法单元344,乘法单元344电耦合到可配置求和单元346和缓冲器350。此外,可配置求和单元346电耦合到池化单元348,池化单元348电耦合到缓冲器350。
[0057]
存储器阵列340储存cnn的每个卷积层1-n的内核/滤波器,诸如cnn300的内核/滤波器312、320和330。因此,存储器阵列340储存cnn的权重。存储器阵列340位于cim电路342之上或顶部上,即cim电路342位于存储器阵列340之下。在一些实施例中,存储器阵列340类似于存储器阵列22(如图1所示)。在一些实施例中,存储器阵列340类似于存储器阵列26(如图1所示)中的一个。在一些实施例中,存储器阵列340类似于存储器阵列100(如图3所示)。在一些实施例中,存储器阵列340是dram阵列、rram阵列、mram阵列和pcram阵列中的一种或多种。在其他实施例中,存储器阵列340位于与cim电路342齐平或低于/低于cim电路342。
[0058]
缓冲器350被配置为接收来自数据输入352的输入数据,诸如初始图像数据,以及来自池化单元348的经处理的输入数据。乘法单元344接收来自缓冲器350的输入数据和来自存储器阵列340的权重。乘法单元344将输入数据与权重进行交互以产生提供给可配置求和单元346的交互结果。在一些实施例中,乘法单元344接收来自缓冲器350的输入数据和来自存储器阵列340的权重并对输入数据和权重执行卷积乘法以产生交互结果。在一些实施例中,输入数据被组织成数据矩阵in
00
到in
mn
并且权重被组织成权重矩阵w
00
到w
mn
。在一些实施例中,乘法单元344类似于乘法单元130。
[0059]
可配置求和单元346包括求和单元354a-354x和比例调节/relu单元356a-356x。可配置求和单元346由每个卷积层1-n编程,诸如通过0和1的模式,以配置可配置求和单元346处理所选数量的输入,提供所选数量的求和,并为卷积层1-n提供所选数量的输出。可配置求和单元346从乘法单元344接收交互结果并且利用所选数量的求和单元354a-354x对交互结果求和以提供求和结果。在一些实施例中,在cnn 300中,可配置求和单元346由每个卷积层302、304和306配置以执行求和单元316、324和334(如图6所示)中的每个的求和。在一些
实施例中,可配置求和单元346类似于可配置求和单元40。在一些实施例中,可配置求和单元346类似于可配置求和单元140。
[0060]
求和单元354a-354x将求和结果提供给比例调节/relu单元356a-356x。在一些实施例中,比例调节/relu单元356a-356x接收求和结果并对求和结果进行比例调节,诸如对求和结果进行标准化,以提供比例调节结果。在一些实施例中,比例调节/relu单元356a-356x接收求和结果并对求和结果执行relu函数。在一些实施例中,比例调节/relu单元356a-356x对比例调节结果执行relu函数。在其他实施例中,比例调节/relu单元356a-356x对求和结果或比例调节结果执行另外的非线性激活函数。
[0061]
可配置求和单元346向池化单元348提供可配置求和单元结果,池化单元348对可配置求和单元结果执行池化函数以减小输出数据的尺寸并提供池化输出。在一些实施例中,池化单元348被配置为执行池化函数308(如图6所示)。
[0062]
在池化之后,池化输出由缓冲器350接收并反馈到乘法单元344以将数据与cnn(诸如cnn 300)的下一个卷积层1-n的权重进行交互。一旦对于cnn的所有层的所有计算都完成了,从缓冲器350输出结果。
[0063]
cim电路342的优点包括具有支持多个不同卷积层1-n的可配置求和单元346。可配置求和单元346可以对于cnn的不同卷积层1-n中的每个进行编程或设置,诸如对于cnn 300的不同卷积层中的每个,包括对于输入的数量、求和的数量或加法器和输出的数量进行设置,使得从第一层到最后一层的不同卷积层1-n中的每个的计算都可以由一个可配置求和单元346完成。
[0064]
图8是示意性地示出根据一些实施例的cim电路342的操作流程的图。cim电路342包括可配置求和单元346,使得可以使用相同的电路来完成对cnn的不同卷积层的计算。通过由卷积层提供的值(诸如通过0和1的模式)为卷积层1-n中的一个编程或设置可配置求和单元346,以设置输入的数量、求和的数量以及卷积层的输出数量。这可以对于cnn中的每个卷积层可以这样做。
[0065]
在400处,通过缓冲器350接收输入数据,诸如用于第一个卷积层的初始图像数据或者是来自先前卷积层的输出数据并用于后续卷积层的输入数据。在402处,用于卷积层1-n中的一个的来自缓冲器350的输入数据和来自存储器阵列340的权重由乘法单元344接收,乘法单元344将输入数据与权重交互以获得交互结果。在一些实施例中,乘法单元344提供输入数据与权重的卷积乘法以提供交互结果。
[0066]
在404处,可配置求和单元346从卷积层数据接收值,该值用于设置当前卷积层的输入数量、求和或加法器的数量以及输出的数量。可配置求和单元346被设置用于当前卷积层并且可配置求和单元346从乘法单元344接收交互结果。可配置求和单元346执行一个或多个的对交互结果求和以提供求和结果,对求和结果进行比例调节以提供比例调节结果,并对求和结果或比例调节结果执行非线性激活函数(例如relu)以提供可配置求和单元结果。
[0067]
在406处,池化单元348接收可配置求和单元结果并对可配置求和单元结果执行池化函数以减小输出数据的尺寸并提供池化输出。在池化之后,如果cnn的所有层没有都完成,则在400处将池化输出提供给缓冲器350,并在402处将池化输出数据与用于cnn的下一卷积层1-n的权重进行交互。在池化之后,如果cnn的所有层的所有计算都完成了,则从缓冲
器350提供结果。在一些实施例中,在贯穿方法期间仅执行该方法的一些步骤。在一些实施例中,406处的池化是可选的。
[0068]
图9是示意性地示出根据一些实施例的确定cnn中卷积层的求和结果的方法的图。在500处,方法包括根据第n层从诸如存储器阵列340的存储器阵列获得权重,其中n是正整数。在502处,方法包括通过诸如乘法单元344的乘法单元将每个数据输入与对应的一个权重进行交互以提供交互结果。在一些实施例中,乘法单元344提供输入数据与权重的卷积乘法以提供交互结果。
[0069]
在504处,方法包括配置可配置求和单元,诸如可配置求和单元346,以接收第n层数量的输入并执行第n层数量的加法。在一些实施例中,通过由卷积层提供的值(例如通过0和1的模式)为卷积层1-n中的一个对可配置求和单元346进行编程,以设置卷积层的输入数量、求和数量和输出数量中的一个或多个。
[0070]
在506处,方法包括由可配置求和单元对交互结果进行求和以提供求和结果,在本文中也称为求和输出。在一些实施例中,方法包括以下至少中的一个:对求和输出进行比例调节以提供比例调节结果,在本文中也称为比例调节输出,以及用非线性激活函数过滤求和输出和比例调节输出中的一个以提供可配置求和单元结果/输出。在一些实施例中,用非线性激活函数过滤求和输出和比例调节输出中的一个包括用relu函数过滤求和输出和比例调节输出中的一个。
[0071]
在一些实施例中,方法还包括以下中的一个或多个:将可配置求和单元结果池化以提供池化结果,将池化结果反馈给乘法单元以执行下一个第n层的计算,以及在完成所有n层之后输出最终结果。
[0072]
因此,所公开的实施例提供了包括至少一个可编程或可配置求和单元的cim系统和方法,可配置求和单元可以在cim系统的操作期间被编程以使用不同数量的求和单元处理不同数量的输入,诸如加法器树中的加法器,并提供不同数量的输出。在一些实施例中,在cim系统的操作期间为cnn中的每个卷积层对至少一个可配置求和单元进行设置。
[0073]
在一些实施例中,在cnn的第一层中,乘法单元将输入数据与权重进行交互以提供交互结果。可配置求和单元接收交互结果并且对交互结果进行求和,并提供比例调节求和结果和非线性激活函数中的一个或多个,诸如relu函数。接下来,至少可选地,对来自可配置求和单元的数据执行池化以减小数据的尺寸。在池化之后,如果没有完成所有层,则输出将反馈到乘法单元,用于将数据与cnn下一层的权重进行交互。一旦完成了cnn的所有层的所有计算,就输出结果。
[0074]
该架构的优点包括具有可配置求和单元,可配置求和单元可以针对cnn的每个不同层进行编程,使得从第一层到最后一层的每个不同层的计算都可以是由一个存储器器件中的一个可配置求和单元完成。
[0075]
公开的实施例还包括位于cim电路之上或顶部上的存储器阵列。这种架构可以为执行cnn功能的cim系统提供更高的存储器容量,诸如加速或提高cnn的性能。
[0076]
根据一些实施例,一种存储器器件包括乘法单元和可配置求和单元。乘法单元被配置为接收第n层的数据和权重,其中n为正整数。乘法单元被配置为将数据乘以权重以提供乘法结果。可配置求和单元由第n层值配置以接收第n层数量的输入并执行第n层数量的加法,并且对乘法结果求和并提供可配置求和单元输出。
[0077]
在一些实施例中,可配置求和单元包括至少一个求和单元,求和单元被配置为对乘法结果求和并提供求和输出。
[0078]
在一些实施例中,可配置求和单元包括比例调节单元,比例调节单元被配置为比例调节求和输出并提供比例调节输出。
[0079]
在一些实施例中,可配置求和单元包括非线性激活函数单元,非线性激活函数单元被配置为对求和输出和比例调节输出中的一个进行滤波以提供可配置求和单元输出。
[0080]
在一些实施例中,非线性激活函数单元包括整流非线性单元(relu)。
[0081]
在一些实施例中,上述存储器器件包括池化单元,池化单元被配置为池化可配置求和单元输出并提供池化结果。
[0082]
在一些实施例中,上述存储器器件包括缓冲器,缓冲器被配置为接收输入数据和池化结果并将输入数据和池化结果中的一个提供回乘法单元以计算第n层中的下一层,其中,缓冲器在所有n层完成之后输出结果。
[0083]
在一些实施例中,上述存储器器件包括存储器阵列,存储器阵列包括存储器元件,存储器元件被配置为储存权重。
[0084]
根据进一步的实施例,存储器器件包括:存储器阵列,包括存储器元件;以及存储器中计算电路,位于存储器器件中并且电耦合到存储器阵列。存储器中计算电路包括乘法单元、可配置求和单元、池化单元和缓冲器。乘法单元从存储器阵列接收第n层的权重和数据输入,其中n为正整数,乘法单元将每个数据输入与权重中的相应一个交互以提供交互结果。可配置求和单元通过第n层被配置为对交互结果求和并提供求和结果。池化单元将求和结果进行池化,缓冲区将池化结果反馈给乘法单元以计算第n层的下一层,其中缓冲器在所有n层完成之后输出结果。
[0085]
在一些实施例中,可配置求和单元通过第n层被配置为接收第n层数量的输入。
[0086]
在一些实施例中,可配置求和单元通过第n层被配置为执行第n层数量的加法。
[0087]
在一些实施例中,可配置求和单元包括多个加法器。
[0088]
在一些实施例中,可配置求和单元包括加法器树中的多个加法器。
[0089]
在一些实施例中,n层是卷积神经网络中的卷积层。
[0090]
在一些实施例中,卷积层包括执行互相关。
[0091]
根据又进一步公开的方面,一种操作存储器器件的方法包括:根据第n层从存储器阵列获取权重,其中n为正整数;通过乘法单元将每个数据输入与权重中的相应一个进行交互,以提供交互结果;对可配置求和单元进行配置以接收第n层数量的输入并执行第n层数量的加法;以及通过可配置求和单元对交互结果进行求和以提供求和输出。
[0092]
在一些实施例中,上述方法包括以下至少一项:比例调节求和输出以提供比例调节输出;和利用非线性激活函数求和输出和比例调节输出中的一个进行过滤,以提供可配置求和单元输出。
[0093]
在一些实施例中,利用非线性激活函数对求和输出和比例调节输出中的一个进行滤波包括利用整流非线性单元(relu)函数对求和输出和比例调节输出中的一个进行滤波。
[0094]
在一些实施例中,上述方法包括池化可配置求和单元输出以提供池化结果。
[0095]
在一些实施例中,上述方法包括:将池化结果反馈给乘法单元以执行下一个第n层计算;在完成所有n层之后输出结果。
[0096]
本公开概述了几个实施例的特征,以便本领域技术人员可以更好地理解本公开的各个方面。本领域技术人员应当理解,他们可以容易地使用本公开作为设计或修改用于实现本文所介绍的实施例的相同目的和/或实现其相同优点的其它过程和结构的基础。本领域技术人员还应当认识到,此类等效结构不背离本发明的精神和范围,并且它们可以在不背离本发明的精神和范围的情况下在本发明中进行各种改变、替换以及改变。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1