用于衬底处理系统的基于模型的调度的制作方法
用于衬底处理系统的基于模型的调度
相关申请的交叉引用
1.本公开内容是于2019年3月29日申请的美国专利申请no.62/826,185的pct国际专利申请。上述引用的申请其全部公开内容都通过引用合并于此。
技术领域
2.本公开内容总体上涉及衬底处理系统,尤其是用于衬底处理系统的基于模型的调度。
背景技术:
3.这里提供的背景描述是为了总体呈现本公开的背景的目的。当前指定的发明人的工作在其在此背景技术部分以及在提交申请时不能确定为现有技术的说明书的各方面中描述的范围内既不明确也不暗示地承认是针对本公开的现有技术。
4.半导体制造商在半导体晶片的制造期间使用一或更多个衬底处理工具,以执行沉积、蚀刻、清洁和/或其他衬底处理。每一衬底处理工具可包括多个处理室,其执行相同类型的处理(例如沉积、蚀刻或清洁)或不同的处理,例如衬底上的一系列或一连串处理。
5.衬底处理工具中的处理室通常在多个衬底上重复相同任务。处理室基于定义处理参数的配方进行操作。例如,配方定义顺序、操作温度、压力、气体化学物质、等离子体使用、并行模块、每一操作或子操作的时间段、衬底路线安排途径和/或其他参数。衬底可依特定顺序在两个或更多处理室之间转移,以进行不同的处理。
技术实现要素:
6.一种用于在工具中处理半导体衬底的系统,所述工具包括被配置成根据配方来处理所述半导体衬底的多个处理室,所述系统包括:处理器;以及存储器,其存储用于由所述处理器执行的指令。所述指令配置成:接收来自所述工具的关于根据所述配方处理在所述多个处理室中的所述半导体衬底的第一数据;以及接收关于所述工具的配置与所述配方的第二数据。所述指令被配置成使用所述第二数据来模拟用于根据所述配方处理在所述多个处理室中的所述半导体衬底的多个处理方案以及用于所述多个处理方案的调度参数。所述指令被配置成使用所述多个处理方案以及用于所述多个处理方案的所述调度参数来模拟根据所述配方处理在所述多个处理室中的所述半导体衬底。所述指令被配置成使用所述第一数据及所述模拟所产生的数据来训练模型,以预测用于根据所述配方处理在所述多个处理室中的所述半导体衬底的最佳调度参数。所述指令被配置成接收来自所述工具的关于根据所述配方处理在所述多个处理室中的所述半导体衬底中的一者的输入。所述指令被配置成使用所述模型,基于所述输入来预测用于根据所述配方处理在所述多个处理室中的所述半导体衬底中的所述一者的最佳调度参数。所述指令被配置成基于用于根据所述配方处理在所述多个处理室中的所述半导体衬底中的所述一者的所述最佳调度参数,对所述工具的操作进行调度。
7.在另一特征中,所述指令配置成基于用于根据所述配方处理在所述多个处理室中的所述半导体衬底中的所述一者的所述最佳调度参数来执行所述工具的所述操作。
8.在其他特征中,在所述多个处理室中根据所述配方进行处理期间,所述最佳调度参数将所述半导体衬底中的所述一者的空闲时间最小化,并且所述最佳调度参数使所述工具的产量最大化。
9.在另一特征中,所述指令被配置成使用包括人工神经网络和支持向量回归的机器学习方法来训练所述模型。
10.在其他特征中,所述指令被配置成:分析从所述工具接收的所述第一数据以及通过所述模拟所产生的所述数据;基于所述分析,检测关于所述工具的预防性维护操作、无晶片自动清洁时间、等待时间、配方时间和产量的模式;以及基于检测到的所述模式,训练所述模型。
11.在另一特征中,所述指令被配置成训练所述模型,以预测用于所述多个处理方案中的一者的所述最佳调度参数。
12.在另一特征中,所述指令被配置成训练所述模型,以预测用于所述多个处理方案中的全部的所述最佳调度参数。
13.在另一特征中,所述指令被配置成训练所述模型,以用于在所述半导体衬底中的所述一者上仅执行蚀刻操作。
14.在另一特征中,所述指令配置成训练所述模型,以用于在所述半导体衬底中的所述一者上执行蚀刻和剥离操作两者。
15.在其他特征中,所述模型是从所述工具远程地实现的,且其中所述指令被配置成基于从多个工具接收的数据来训练所述模型。
16.在另一特征中,所述指令被配置成针对在配置和操作中的工具与工具之间的变化来调整所述模型。
17.在另一特征中,所述模型是在云端作为软件即服务(saas)实现,并且所述工具配置成通过网络访问所述模型。
18.在其他特征中,所述指令被配置成基于第二工具的数据来训练第二模型;并且所述模型和所述第二模型是从所述工具和所述第二工具远程地实现的。所述工具和所述第二工具分别被配置成通过一或更多网络访问所述模型和所述第二模型。
19.在另一特征中,所述指令被配置成使得所述工具和所述第二工具分别基于所述工具和所述第二工具的配置来选择所述模型和所述第二模型。
20.在其他特征中,所述模型实施在所述工具上,且所述指令被配置成使用所述模型以利用所述工具所产生的数据来预测用于根据所述配方处理在所述多个处理室中的所述半导体衬底中的所述一者的所述最佳调度参数。
21.在其他特征中,所述模型实施在所述工具上,且所述指令配置成针对所述工具的性能的任何漂移来调整所述模型。
22.在另一特征中,从所述工具接收的所述第一数据包括来自在所述工具上执行的预防性维护操作的数据以及关于所述工具的配方时间和无晶片自动清洁时间的数据。
23.在另一特征中,通过所述模拟所产生的所述数据包括基于从所述工具获得的所述工具的配置、晶片流类型、运行方案、配方时间和无晶片自动清洁时间所产生的数据。
24.在另一特征中,从所述工具接收的所述输入包括关于所述工具的预防性维护操作的数量、配方时间和无晶片自动清洁时间的数据。
25.在另一特征中,所述指令配置成通过考虑一或更多跳过的预防性维护操作来预测所述最佳调度参数。
26.在其他特征中,所述指令配置成:使用所述模型,对用于根据所述配方处理在所述多个处理室中的所述半导体衬底中的所述一者的多个操作进行调度。所述工具分别响应于执行所述多个操作而经历多个状态。所述工具的状态包括所述工具的资源的指示和所述半导体衬底中的所述一者的处理状态的指示。所述指令被配置成针对所述多个状态中的每一者,对所述模型发送所述多个状态中的当前状态及用于进展到所述多个状态中的下一状态的多个可调度操作,从所述模型接收由所述模型基于所述当前状态所选择的所述多个可调度操作中的最佳操作以进展到所述下一状态,并且模拟所述最佳操作的执行以模拟进展到所述下一状态。所述指令被配置成当根据所述配方处理在所述多个处理室中的所述半导体衬底时,训练所述模型以推荐所述最佳操作作为响应于所述工具经历所述多个状态的所述多个操作。
27.在还有的其他特征中,一种用于在工具中处理半导体衬底(所述工具包括被配置成根据配方来处理所述半导体衬底的多个处理室)的系统包括:处理器;以及存储器,其存储用于由所述处理器执行的指令。所述指令配置成:使用模型,对用于根据所述配方处理在所述多个处理室中的半导体衬底的多个操作进行调度。所述工具分别响应于执行所述多个操作而经历多个状态。所述工具的状态包括所述工具的资源的指示和所述半导体衬底的处理状态的指示。所述指令被配置成针对所述多个状态中的每一者,对所述模型发送所述多个状态中的当前状态及用于进展到所述多个状态中的下一状态的多个可调度操作,从所述模型接收由所述模型基于所述当前状态所选择的所述多个可调度操作中的最佳操作以进展到所述下一状态,并且模拟所述最佳操作的执行以模拟进展到所述下一状态。所述指令被配置成当根据所述配方处理在所述多个处理室中的所述半导体衬底时,训练所述模型以推荐所述最佳操作作为响应于所述工具经历所述多个状态的所述多个操作。
28.在其他特征中,所述指令配置成使用关于从所述工具接收的所述半导体衬底的处理的历史数据并且通过模拟所述工具的多个处理方案来训练所述模型,以预测用于根据所述配方处理在所述多个处理室中的所述半导体衬底的最佳调度参数。所述指令被配置成接收来自所述工具的关于根据所述配方处理在所述多个处理室中的所述半导体衬底的输入。所述指令被配置成使用所述模型,基于所述输入来预测用于根据所述配方处理在所述多个处理室中的所述半导体衬底的最佳调度参数。所述指令被配置成基于用于根据所述配方处理在所述多个处理室中的所述半导体衬底的所述最佳调度参数,对所述多个操作进行调度。
29.在另一特征中,所述指令被配置成基于用于根据所述配方处理在所述多个处理室中的所述半导体衬底的所述最佳调度参数来执行所述多个操作。
30.在其他特征中,在所述多个处理室中根据所述配方进行处理期间,所述最佳调度参数将所述半导体衬底的空闲时间最小化,且所述最佳调度参数使所述工具的产量最大化。
31.在另一特征中,所述指令被配置成使用包括人工神经网络和支持向量回归的机器
学习方法来训练所述模型。
32.在其他特征中,所述指令被配置成:分析从所述工具接收的所述历史数据以及通过模拟所述工具的所述多个处理方案而产生的数据;基于所述分析,检测关于所述工具的预防性维护操作、无晶片自动清洁时间、等待时间、配方时间和产量的模式;以及基于检测到的所述模式,训练所述模型。
33.在另一特征中,所述指令被配置成训练所述模型,以预测用于所述多个处理方案中的一者的所述最佳调度参数。
34.在另一特征中,所述指令被配置成训练所述模型,以预测用于所述多个处理方案中的全部的所述最佳调度参数。
35.在另一特征中,所述指令被配置成训练所述模型,以用于在所述半导体衬底上仅执行蚀刻操作。
36.在另一特征中,所述指令配置成训练所述模型,以用于在所述半导体衬底中的所述一者上执行蚀刻和剥离操作两者。
37.在其他特征中,所述模型是从所述工具远程地实现的,且所述指令被配置成基于从多个工具接收的数据来训练所述模型。
38.在另一特征中,所述指令被配置成针对在配置和操作中的工具与工具之间的变化来调整所述模型。
39.在其他特征中,所述模型是在云端作为软件即服务(saas)实现,且其中所述工具配置成通过网络访问所述模型。
40.在其他特征中,所述模型实施在所述工具上,且所述指令被配置成使用所述模型以利用所述工具所产生的数据来预测用于根据所述配方处理在所述多个处理室中的所述半导体衬底的所述最佳调度参数。
41.在其他特征中,所述模型实施在所述工具上,且所述指令配置成针对所述工具的性能的任何漂移来调整所述模型。
42.在另一特征中,从所述工具接收的所述数据包括来自在所述工具上执行的预防性维护操作的数据以及关于所述工具的配方时间和无晶片自动清洁时间的数据。
43.在另一特征中,通过模拟所述多个处理方案包括基于从所述工具获得的所述工具的配置、晶片流类型、运行方案、配方时间和无晶片自动清洁时间所产生的数据。
44.在另一特征中,从所述工具接收的所述输入包括关于所述工具的预防性维护操作的数量、配方时间和无晶片自动清洁时间的数据。
45.在另一特征中,所述指令配置成通过考虑一或更多跳过的预防性维护操作来预测所述最佳调度参数。
46.在还有的其他特征中,一种用于处理半导体衬底的工具包括:第一机械手、多个处理室、第二机械手和控制器。第一机械手被配置成将所述半导体衬底输入至所述工具,以在所述工具中处理所述半导体衬底。所述多个处理室被配置成在所述工具中根据配方处理所述半导体衬底。第二机械手被配置成根据所述配方在所述多个处理室之间转移所述半导体衬底。所述控制器被配置成使用通过模拟所述工具和所述配方所训练的模型来预测:在所述多个处理室中处理所述半导体衬底的处理时间;所述第二机械手在所述多个处理室之间转移所述半导体衬底的转移时间;基于所述处理时间和所述转移时间,在所述多个处理室
之间转移所述半导体衬底的路线;以及所述第一机械手基于所述处理时间和所述转移时间待调度额外半导体衬底以在所述工具中进行处理的时间。根据预测的所述路线处理所述半导体衬底以及根据预测的所述时间处理所述额外半导体衬底,使得沿所述预测路径的所述半导体衬底的等待时间优化,并使所述工具的产量优化。
47.在另一特征中,所述控制器配置成:基于所述半导体衬底及所述额外半导体衬底在所述工具中进行所述处理期间所产生的数据,进一步渐进地训练所述模型。
48.在另一特征中,所述控制器被配置成使用所述进一步训练的模型预测:在所述工具中处理所述额外半导体衬底的第二处理时间、第二转移时间、以及第二路线;以及调度下一组半导体衬底以在所述工具中进行处理的第二时间。根据所述第二路线处理所述额外半导体衬底并且根据所述第二时间处理所述下一组半导体衬底,使得所述额外半导体衬底的等待时间和所述工具的产量进一步优化。
49.在另一特征中,所述控制器被配置成响应于所述配方、所述工具或两者的任何改变来调整所述模型。
50.在另一特征中,所述模型包括:第一多个神经网络,其被配置成分别预测所述多个处理室的所述处理时间;第二多个神经网络,其被配置成分别预测所述第一和第二机械手的所述转移时间;以及第三神经网络,其耦合至所述第一和第二多个神经网络,并且被配置成预测在所述多个处理室之间转移所述半导体衬底的所述路线,并且预测所述第一机械手将调度所述额外半导体衬底以在所述工具中进行处理的所述时间。
51.在另一特征中,所述模块通过模拟多个工具的配置和多个配方来进一步训练。
52.在另一特征中,进一步训练的所述模型被配置成响应于接收配方信息作为输入以针对工具配置输出推荐。
53.在另一特征中,所述配方用于在所述半导体衬底上沉积多个层。所述多个处理室包括用于沉积所述多个层的一或更多处理室、以及用于分别在沉积所述多个层之前和之后处理所述半导体衬底的预处理室和后处理室。所述第二机械手被配置成根据预测的所述路线,在所述多个处理室之间转移所述半导体衬底,以使所述半导体衬底的所述等待时间优化。所述第一机械手被配置成根据预测的所述时间,调度所述额外半导体衬底以在所述工具中进行处理,以使所述工具的所述产量优化。
54.在还有的其他特征中,一种用于在半导体处理工具中处理半导体衬底期间使产量和等待时间优化的系统包括:处理器;以及存储器,其存储用于由所述处理器执行的指令。所述指令配置成基于所述半导体处理工具的配置以及将在所述半导体处理工具中的所述半导体衬底上执行的配方,模拟多个路线以在所述半导体处理工具的多个处理室之间安排所述半导体衬底的路径。所述指令配置成沿着所述多个路线,模拟根据所述配方对在所述半导体处理工具中的所述半导体衬底的处理。所述指令配置成基于对所述半导体衬底的所述处理,模拟多个定时调度,以随后处理在所述半导体处理工具中的额外半导体衬底。所述指令配置成根据所述多个定时调度,模拟对所述额外半导体衬底的处理。所述指令配置成基于所述模拟所产生的数据,训练模型。所述指令配置成当根据所述配方处理在所述半导体处理工具中的所述半导体衬底时,使用所述半导体处理工具上的所述模型,预测在所述多个处理室之间转移所述半导体衬底的最佳路线。所述指令配置成使用所述半导体处理工具上的所述模型来预测最佳时间,以调度所述额外半导体衬底,以在所述半导体处理工具
中进行处理。所述指令配置成在所述半导体处理工具中,根据所述最佳路线来处理所述半导体衬底,以使沿着所述最佳路线的所述半导体衬底的等待时间优化。所述指令配置成在所述半导体处理工具中,以所述最佳时间处理所述额外半导体衬底,以使所述半导体处理工具的产量优化。
55.在其他特征中,所述指令被配置成基于所述模拟所产生的所述数据来训练所述模型,以预测:在所述多个处理室中处理所述半导体衬底的处理时间;用于在所述多个处理室之间转移所述半导体衬底的所述半导体处理工具的机械手的转移时间;基于所述处理时间和所述转移时间,用于在所述多个处理室之间安排所述半导体衬底的所述最佳路线;以及基于所述处理时间和所述转移时间,调度所述额外半导体衬底以在所述半导体处理工具中进行处理的所述最佳时间。
56.在另一特征中,所述指令被配置成基于所述半导体衬底和所述额外半导体衬底在所述半导体处理工具中进行所述处理期间所产生的数据来进一步渐进地训练所述模型。
57.在另一特征中,所述指令被配置成针对所述配方、所述半导体处理工具或两者的任何改变来调整所述模型。
58.在其他特征中,所述指令被配置成基于所述模拟所产生的所述数据来产生所述模型,而所述模型包括:第一多个神经网络,其被配置成分别预测在所述多个处理室中处理所述半导体衬底的处理时间。所述模型包括:第二多个神经网络,其被配置成分别预测所述第一和第二机械手的转移时间。所述第一和第二机械手分别配置成将所述半导体衬底转移至所述半导体处理工具中以及在所述多个处理室之间转移所述半导体衬底。所述模型包括:第三神经网络,其耦合至所述第一和第二多个神经网络,并且被配置成预测用于在所述多个处理室之间安排所述半导体衬底路径的所述最佳路线,并且预测调度所述额外半导体衬底以在所述半导体处理工具中进行处理的所述最佳时间。
59.在另一特征中,所述指令被配置成通过模拟多个半导体处理工具的配置和多个配方来训练所述模型。
60.在另一特征中,所述指令被配置成响应于接收配方信息作为输入来训练所述模型,以针对工具配置输出推荐。
61.上述和下述的任何特征可分开实施(即,独立于上述和下述的其他特征)。在一些实施方案中,上述及下述的任何特征可以与上述和下述的其他特征组合。
62.根据详细描述、权利要求和附图,本公开内容的适用性的进一步的范围将变得显而易见。详细描述和具体示例仅用于说明的目的,并非意在限制本公开的范围。
附图说明
63.根据详细描述和附图将更充分地理解本公开,其中:
64.图1是包括一或更多个处理室的衬底处理工具示例的功能框图;
65.图2是包括处理室的衬底处理系统示例的功能框图;
66.图3是数据收集系统示例的功能框图;
67.图4示出了用于产生并且训练机器学习辅助模型以调度衬底处理工具的晶片处理操作的系统的功能框图;
68.图5a
‑
8示出了用于产生并且训练机器学习辅助模型的方法;
69.图9
‑
11示出了用于产生本文所述模型的深度神经网络示例;
70.图12示出了使用离散事件模拟器来训练强化学习模型的系统的功能框图;
71.图13示出了使用离散事件模拟器训练强化学习模型的方法;
72.图14示出了用于训练具有嵌套神经网络的模型的系统,其使用离线模拟器以及来自工具的在线实时数据,以调度并且调整工具中的晶片处理;
73.图15a和15b示出了用于训练具有嵌套神经网络的模型的方法,其使用离线模拟器以及在线实时工具数据,以调度并且调整工具中的晶片处理;
74.图16示出了包括有多个处理模块(例如,电镀槽)的工具示例;
75.图17示出了用于图16的工具中的处理模块(例如,电镀槽)的示例;以及
76.图18示出了晶片厂(fab)数据收集系统的示例,其与图14的离线模拟器合并使用,以训练用于调度并且调整工具(例如,图16的工具)中的晶片处理的模型。
77.在附图中,可以重复使用附图标记来标识相似和/或相同的元件。
具体实施方式
78.通常,衬底处理工具(下文称“工具”)的操作员是基于过去的经验、实验或通过利用试错法(trial
‑
and
‑
error approach),来手动选择调度参数值。这是因为不易建立用于选择调度参数值的简单准则。由于工具(例如蚀刻工具)的不同衬底处理方案可能需要不同组的调度参数值,以实现工具的最佳产量,因此在启动在工具上运行的每一晶片流前,操作员可能必须手动地将调度参数值输入至控制工具的系统软件中。
79.在一些工具中,系统软件中的调度器可以使用成组的调度规则及评分系统,以作出调度决策。然而,随着工具的系统配置、运行方案及调度限制的复杂性增加,调度决策方案的复杂性也随之增加,其因而需要更多开发工作,以实现并且维持最佳的系统产量。
80.此外,在用于多个并行材料沉积处理的批量(多个衬底)处理工具中(其对晶片等待时间有限制),对工具的调度器进行调整(pacing)以实现最佳产量及最小晶片等待时间可能是非常困难的。调度器规则是非常动态的,而不正确的调度计算可能因晶片变干而导致异常晶片或产量下降,其增加了工具的持有成本(cost
‑
of
‑
ownership)。此外,不同的客户应用使得调整预测更加复杂。例如,长的处理时间配方(例如,巨型柱体(mega
‑
pillar)配方)使处理模块成为瓶颈,而短的处理时间配方(例如,重布层配方或rdl配方)则使后端机械手(具有若干用于一起处理批量/多个衬底的臂)成为瓶颈。
81.本公开内容如下文通过使用经训练的模型并且进一步通过使用强化学习,来解决这些问题。对于蚀刻工具,训练神经网络模型(下称“模型”),以预测最佳调度参数值。该模型是使用从预防性维护操作(pm)、配方时间及无晶片自动清洁(wac)时间收集的数据作为模型的输入来进行训练。该模型被用于获取调度参数值与各种晶片处理方案之间的基础关系,以相应地作出预测,从而消除了为最佳值选择建立准则的需要。
82.在训练之前,辨识模型所预测的成组的重要调度参数。从半导体制造商所使用的工具中收集大量的训练数据。使用模拟产生其他训练数据,以涵盖使用该工具的半导体制造商所使用的各种处理方案。确定最佳神经网络结构,以支持可跨调度参数空间提供一致预测准确性的模型。尽管可以使用晶片处理方案的专用模型,但也可通过使用从其他处理方案收集的数据来随时间推移训练模型而产生可覆盖各种处理方案的单一模型。
83.为易于模型维护,可以在工具的系统软件外部运行模型。即,模型可以在工具的系统软件外部,其与工具系统软件分离,且不整合于工具的系统软件中。该模型可以根据操作员所选择的晶片流,从系统软件接收输入参数。接着,该模型可以计算并且预测最佳调度参数值,并将其发送回系统软件。例如,设备制造商可以将模型部署在云端中作为半导体制造商可订购的软件即服务(software
‑
as
‑
a
‑
service)。替代地,设备制造商可以将模型运用至工具的系统软件中。
84.使用经训练的模型使得系统软件中内置的调度器的基本的行为能被捕获到神经网络模型中,其可接着用于预测将被使用的最佳调度参数值。操作员不再需要进行广泛的模拟研究,以选择最佳调度参数值。使用经训练的模型也使得系统软件在新晶片流要开始时能自动选择调度参数值。
85.另外,调度器的调度规则及评分系统可以用神经网络模型代替。该模型使用离散事件模拟器以及强化学习来训练,以自探索并且记忆系统的给定状态的最佳调度决策。这使得能实现并且维持系统的最佳产量性能。
86.自探索过程使用离散事件模拟器,以自动化努力以找出以最佳产量性能操作系统的最佳可能方式(例如,找出通过工具移动晶片的最佳路径)。通过在工具上运行自训练过程,可针对特定工具配置、晶片处理方案以及该工具特有的限制使该神经网络模型优化。
87.因此,本发明提供了一种智能机器学习辅助调度器。智能调度器利用自学习过程来训练神经网络模型,以对系统的给定状态作出最佳调度决策。这些决策有助于在特定于半导体制造商的运行方案和调度限制条件下实现和维护工具处于最佳产量条件。
88.例如,对于每一配方,智能调度器可确保晶片空闲时间可小于总处理时间的2%,且制造效率(实际周期时间/理论周期时间)可以大于97%。此外,智能调度器可以补偿工具之间的差异以及同一工具内随时间推移可能发生的性能漂移。此外,智能调度器可以通过考虑可能必须跳过或延迟以满足制造期限的预防性维护,以使调度参数值优化。智能调度器的这些和其他特征将于下文详细描述。
89.此外,如下文所解释的,为了改善用于多个并行材料沉积(例如,多层镀覆)处理的工具中所使用的调度器调整的准确性,本公开内容提出了基于嵌套神经网络的机器学习方法,其用于准确地预测针对不同处理的调度器调整。使用该方法,最初利用模拟在离线下开发并且训练模型,接着使用实际工具进行在线训练,用于预测晶片路线安排途径及调度,以实现最高工具/机群利用率、最短等待时间以及最快产量。
90.本公开内容安排如下。参考图1,示出并描述工具的示例。参考图2,示出并且描述了包括有处理室的衬底处理系统的示例。参考图3,示出并描述了用于从各种工具收集数据的数据收集系统的示例。参考图4,示出并描述了用于产生并且训练机器学习辅助模型的系统。参考图5a
‑
8,示出并描述了用于产生并训练机器学习辅助模型的方法。参考图9
‑
11,示出并描述了用于产生本文所述模型的深度神经网络的示例。参考图12,示出并描述了使用离散事件模拟器来训练强化学习模型的系统。参考图13,示出并描述使用离散事件模拟器来训练强化学习模型的方法。参考图14,示出并描述了用于训练具有嵌套神经网络的模型的系统,其使用离线模拟器以及在线实时工具数据,以调度并且调整工具中晶片处理。参考图15a和15b,示出并描述了用于训练具有嵌套神经网络的模型的方法,其使用离线模拟器以及在线实时工具数据,以调度并且调整工具中晶片处理。参考图16,示出并描述了包括有
多个处理模块(例如,电镀槽)的工具的示例。参考图17,示出并描述了图16的工具的处理模块示例。参考图18,示出并描述了晶片厂数据收集系统的示例,其与离线模拟器合并使用,以训练用于调度并且调整工具中晶片处理的模型。
91.图1示出了衬底处理工具100的示例。衬底处理工具100包括多个处理室104
‑
1、104
‑
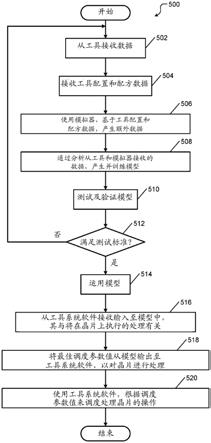
2、...及104
‑
m(统称为处理室104)(其中m为大于的1整数)。仅作为示例,每一处理室104可配置成执行一或更多类型的衬底处理。换言之,衬底可装载至处理室104中的一者中进行处理,接着移动至处理室104中的其他一或多者中(如果至少一者执行不同处理的话)和/或从衬底处理工具100中移出(如果所有都执行相同处理的话)。
92.待处理的衬底经由大气到真空(atv)转移模块108的装载站的端口,装载至衬底处理工具100中。在一些示例中,atv转移模块108包括设备前端模块(efem)。接着,衬底转移至一或更多个处理室104中。例如,转移机械手112被布置成将衬底从装载站116转移至气锁(airlock)或装载室120,且真空转移模块128的真空转移机械手124被布置成将衬底从装载室120转移至各个处理室104中。
93.可提供处理室控制器130、传送控制器134和/或系统控制器138。传送控制器134控制机械手112和124、与传送衬底进出衬底处理工具100有关的致动器和传感器。处理室控制器130控制处理室104的操作。一般而言,处理室控制器130监测传感器135,例如温度传感器、压力传感器、位置传感器等,并且控制致动器136,例如机械手、端口、加热器、气体输送系统、静电卡盘(esc)、射频(rf)产生器等。与处理室104相关联的处理室控制器130一般遵循着配方,其具体指定步骤的定时、待供应的处理气体、温度、压力、rf功率等。
94.图2示出了用于处理衬底的衬底处理系统200的示例,以说明在处理室的操作期间所产生的数据类型的示例。尽管示出了特定类型的处理室,但可以使用其他类型的处理室。衬底处理系统200包括处理室202,其包围衬底处理系统200的其他部件并且含有rf等离子体。衬底处理系统200包括上电极204和衬底支座,例如静电卡盘(esc)206。在操作期间,衬底208被布置于esc206上。
95.仅作为示例,上电极204可以包括喷头209,其引入并分布处理气体,例如沉积前体、蚀刻气体、载气等。esc206包括用作下电极的导电底板210。底板210支撑加热板212,其可对应于陶瓷多区域加热板。热阻层214可被布置于加热板212与底板210之间。底板210可包括一或更多个冷却剂通道216,以用于使冷却剂流过底板210。
96.rf产生系统220产生并输出rf电压至上电极204与下电极(例如,esc206的底板210)中的一者。上电极204与底板210中的另一者可以是dc接地、ac接地或浮置。仅作为示例,rf产生系统220可包括rf电压产生器222,其产生由匹配和分配网络224供应至上电极204或底板210的rf电压。在其他示例中,等离子体可感应地或远程地产生。
97.气体输送系统230包括一或更多个气体源232
‑
1、232
‑
2、
…
及232
‑
n(统称为气体源232),其中n为大于零的整数。气体源232供应一或更多种沉积前体、蚀刻气体、载气等。也可以使用汽化前体。气体源232通过阀234
‑
1、234
‑
2、
…
以及234
‑
n(统称为阀234)和质量流量控制器236
‑
1、236
‑
2、
…
和236
‑
n(统称为质量流量控制器236)连接至歧管238。歧管238的输出供应至处理室202。仅作为示例,歧管238的输出供应至喷头209。
98.光学发射光谱(oes)传感器239可安置于邻近被布置在室表面241上的窗口240。oes传感器239选择性地产生oes数据。温度控制器242可连接至被布置于加热板212中的多
个热控制元件(tce)244。例如,tce244可包括,但不限于,对应于多区域加热板中每一区域的各个巨型tce和/或设置于多区域加热板的多个区域各处的微型tce阵列。温度控制器242可以用于控制多个tce244,以控制esc206和衬底208的温度。
99.温度控制器242可以与冷却剂组件246连通,以控制流过通道216的冷却剂流。例如,冷却剂组件146可以包括冷却剂泵和贮存器。温度控制器242操作冷却剂组件246,以使冷却剂选择性地流过通道216以冷却esc206。
100.阀250和泵252可以用于从处理室202中抽空反应物。控制器260可以用于控制衬底处理系统200的部件。机械手270可用于输送衬底至esc206上并将衬底移离esc206。例如,机械手270可以在esc206与装载室272之间转移衬底。虽然被示为分开的控制器,但温度控制器242可以在控制器260中实现。
101.在衬底的处理和传送期间,衬底处理工具产生大量的离散数据和串流数据。事件数据可以用于确定各种部件中的位置和停留时间。例如,在模组或前开式晶片传送盒(foup)中的停留时间可能导致衬底之间的处理差异。系统日志记录系统级数据。在衬底传送期间,记录额外数据。每一处理室也在衬底处理期间记录数据。记录的数据包括不同的数据类型、采样率和/或格式。一些数据仅局部存储于处理室中,而其他数据则存储于晶片厂级。
102.数据通常在固定频率下以消息格式从工具传至主机。数据一般不是基于衬底发送。而是按时间发送数据。数据通常基于固定频率或文件大小收集于文件中。数据通常是连续收集,并且无界限。在一些系统中,分别在处理最初和最终衬底期间在配方开始和配方结束时收集数据,但不对中间衬底进行收集。
103.从这些数据,可以使用大数据工具和/或机器学习来收集并分析非机密操作数据,以建立并训练可提供最佳调度参数的模型,从而改善生产率和系统产量。此外,基于工具配置和配方数据,可利用模拟来产生额外模型训练数据。
104.半导体制造商可组合来自具有不同格式的不同文件的数据。在一些示例中,从客户工具收集的数据可以是支持加密和向前/向后兼容性(forward/backward compatibility)的一般结构化文件格式。在一些示例中,数据格式可以与技术数据管理解决方案(tdms)文件格式一致。在一些示例中,数据格式可以是可访问的,并且可以通过客户使用密钥(例如,应用程序编程接口(api)密钥)来读取。数据上下文(context)和收集跨不同数据类型可以是一致的,以使得能使用并分析,而无需对收集的数据执行清理、重新格式化和/或其他工作。
105.在一些示例中,可以从衬底离开晶盒的那一刻起收集数据,直到衬底返回晶盒为止。在一些示例中,数据可存储在单一文件中。在一些示例中,文件格式可以是自洽的(self
‑
consistent)。在一些示例中,数据可基于数据的类型及上下文(context)在不同频率下收集。在一些示例中,可使用带有加密的tdms,对数据进行格式化。在一些示例中,数据适配器可用于支持遗留数据以及向后兼容性、合并新数据类型以及支持主机消息传送和串流数据。
106.图3示出了用于半导体处理系统的晶片厂数据收集系统300。晶片厂数据收集系统300包括n个衬底处理工具320
‑
1、320
‑
2、...及320
‑
n(其中n为整数)(统称为衬底处理工具320)。每一衬底处理工具320包括一或更多个处理室控制器340
‑
1、340
‑
2、...以及340
‑
n(统
称为处理室控制器340),以控制处理室的操作,如上所述。处理室所收集的数据示例包括衬底或晶片数据日志、自动预防性维护、高速数据、光发射光谱(oes)、追踪数据、oes快照、基座温度图及其他数据、校准文件、设备常数、传感器数据和/或其他数据。
107.每一衬底处理工具320可包括传送控制器344
‑
1、344
‑
2、
…
和344
‑
n(统称为传送控制器344),以控制动态对准并且存储校准文件、平台追踪数据日志、设备常数、转移模块行动和/或其他数据。动态对准是指衬底相对于其他室部件(例如基座、边缘环或其他对象的中心)的位置。
108.每一衬底处理工具320可以分别包括工具系统控制器348
‑
1、348
‑
2、
…
和348
‑
n(统称为工具系统控制器348)。工具系统控制器348记录批量历史、详细事件日志、基于批的警报、基于时间的警报、工具控制器健康、部件追纵、部件历史、材料调度以及其他数据。
109.每一衬底处理工具320进一步包括数据诊断服务计算机350
‑
1、350
‑
2、
…
和350
‑
n(统称为数据诊断服务计算机350)以及数据存储装置362
‑
1、362
‑
2、.....和362
‑
n(统称为数据存储装置362)。在其他示例中,数据诊断服务电脑350可以由两个或更多工具共享,或者每一工具可以包括多于一个的数据诊断服务计算机350。衬底处理工具320通过例如工具数据总线或网络364
‑
1和串流数据总线或网络364
‑
2之类的一或更多根总线连接到主机服务器364。
110.在一些示例中,主机服务器364包括安全模块366和数据选择器模块367。安全模块366提供安全性,例如加密或密码保护。安全模块366使用加密或密码,以授予或拒绝访问衬底处理工具320所存储的数据和/或访问数据选择器模块367。主机服务器364进一步包括数据选择器模块367,以使得用户计算机380能从一或更多个衬底处理工具中选择一或更多种数据类别,并且使用一或更多数据上下文字段(context fields)来过滤数据。在其他示例中,安全模块366和/或数据选择器模块367可使用分开的服务器来实施。
111.主机服务器364通过例如广域网(wan)或局域网络(lan)之类的网络368连接至机器学习计算机374和/或一或更多用户计算机380。主机服务器364所返回的数据集可以被机器学习计算机374访问,以进一步分析。在一些示例中,机器学习计算机374包括安全模块375,以控制对数据的访问。机器学习计算机374使用由用户选择的数据收集系统300所产生的一或更多个数据文件来执行机器学习。由于来自不同衬底处理工具的文件格式相同,因此数据可合并为单一文件并进行分析。这使得同一处理能在多台机器中被分析。
112.衬底处理工具320的数量t不受限制。另外,衬底处理工具320无需位于相同设施处。在一些示例中,可授权设备制造商访问多个半导体制造商所存储的数据。在一些示例中,一些或所有数据产生装置(除了串流或hsd装置之外)的采样率可对准共同采样周期,并基于采样周期将数据添加至共同文件。
113.图4示出了根据本公开内容的用于产生并且训练机器学习辅助模型的系统400。例如,该系统400可以包括机器学习计算机(例如,图3所示的元件374)。该系统400包括数据收集器402、模拟器404、数据分析器406以及模型产生器408。数据收集器402从一或更多个工具收集数据,以用于产生并且训练神经网络模型。模拟器404基于从工具获得的硬件配置、晶片流类型、运行方案、配方时间以及无晶片自动清洁(wac)时间来产生额外训练数据。
114.数据分析器406利用用于分析大数据的技术来分析数据收集器402所收集的数据和模拟器404所产生的数据。数据分析器406获取调度参数值与晶片处理方案之间的基本关
系。模型产生器408通过将机器学习技术应用至数据分析器406所分析的数据来产生模型。模型产生器408定义、训练并验证一或更多个模型,如下文详细叙述的。
115.在系统400中,所有元件402
‑
408可通过单一计算机(例如,图3所示的组件374)来实现。元件402
‑
408中的每一者可通过分开的计算机来实现。元件402
‑
408中的一或多者可通过分开的计算机来实现。换言之,元件402
‑
408可使用一或更多计算装置来实现。
116.每一计算装置可以包括一或更多个硬件处理器(例如,cpu)。每一计算装置可包括存储器,其存储对应于以下参考图5a
‑
8所示并描述的方法的指令。计算装置的硬件处理器可执行存储于计算装置的存储器中的指令。
117.元件402
‑
408中的一或多者可通过一或更多个网络通信地互连。例如,网络可包括lan、wan、因特网、基于云端的网络系统或任何其他分布式通信系统(例如,基于客户端
‑
服务器架构的网络系统)。
118.例如,数据收集器402可被实现为图3所示的晶片厂数据收集系统300。数据收集器402从一或更多个工具(例如,图1所示的工具100)收集数据。该一或更多个工具可以位于相同客户位置。该一或更多个工具可以位于同一客户的不同位置。该一或更多个工具可以位于不同客户的位置。从工具收集到的数据不包括客户的私有和机密数据,但包括可用于产生并训练模型的所有其他操作数据。
119.仅作为示例,工具(从该工具收集数据)可以是蚀刻工具,且可具有以下配置。该工具可以具有多达4个气锁。晶片流配置可以是具有冷却站的1级(仅蚀刻)和/或2级(蚀刻和剥离)。配方类型可以包括晶片处理、无晶片自动清洁、预处理以及后处理等。运行方案可以包括单流和/或并行运行的多流。该工具可以包括多达六个处理室,包括一或更多个蚀刻室、一或更多个剥离室、清洁室等。
120.在系统400中,模型产生器408将机器学习(ml)方法应用至从工具及模拟器404获得并由数据分析器406分析的历史数据,以产生产量预测模型。使用该模型,工具的调度器可使用模型为给定工具配置所提供的最佳调度参数来对晶片的处理进行调度。由于基本变量之间的复杂关系,简单的线性回归无法很好地发挥作用。相反,使用机器学习方法提供了灵活度,以处理复杂非线性数据。机器学习方法的示例包括人工神经网络(ann)、支持向量回归(svr)等。
121.模型产生器408可使用其他方法代替机器学习方法或除使用机器学习方法之外还使用其他方法。其他方法的示例包括元启发式(metaheuristic)和数学方法(例如petri网)。元启发式方法是人工智能(ai)的一个分支,且为自动试错法,以找出得以满足预定性能要求的近乎最佳调度模式。接着,调度参数值可以从选定的调度模式中提取出。用于寻找近乎最佳调度模式的算法示例包括基因演算法和基因程序设计。
122.使用选定的机器学习方法,模型产生器408训练模型,以预测最佳调度参数值。使用例如从工具的预防性维护操作(pm)、配方时间以及无晶片自动清洁(wac)时间收集到的数据来训练该模型。该模型用于获取调度参数值与各种晶片处理方案之间的基本关系,以对应地作出预测,从而消除了建立最佳值选择的准则的需要。该模型可跨参数空间提供一致的预测准确性。
123.该模型产生器408可以产生并训练用于特定晶片处理方案的专用模型。换言之,该模型可针对特定工具进行训练。替代地,模型产生器408可以产生并训练可以覆盖多种方案
的单一模型。换言之,模型可训练成作用于多个工具。例如,针对特定工具训练的专用模型可以利用从其他工具随着时间推移从其他方案收集到的数据而进一步训练以作用于多个工具。
124.为了确定一模型是否可以覆盖所有可能的方案或是否需要专用模型,模型产生器408可以基于从多个工具配置及运行方案收集到的数据,应用选定的机器学习方法来产生模型,以检查预测准确性是否可满足成功标准。成功标准可以包括模型是否可补偿工具之间的变化以及同一工具内随时间推移可能发生的性能漂移。成功标准可进一步包括模型是否可通过考虑跳过的预防性维护,使调度参数值优化。成功标准还可以包括晶片空闲时间是否小于所有晶片的总处理时间的小的百分比(例如2%),以及每一配方的制造效率(实际周期时间/理论周期时间)是否会是高的(例如,大于97%)。
125.在使用时,模型可基于操作员选择的晶片流,从工具的系统软件(例如,从工具100的系统控制器138)接收输入参数。例如,模型可接收pm数、配方时间及wac时间作为输入。接着,该模型可计算并预测最佳调度参数值,并将其发送回系统软件。经训练的模型获取内置于系统软件中的调度器的基本行为,其可接着用于预测根据选定晶片流处理一组晶片时将使用的最佳调度参数值。使用经训练的模型也使得工具的系统软件能够在即将开始新的晶片流时自动选择调度参数值。工具操作员不再需要进行广泛的模拟研究以选择最佳的调度参数值。
126.该模型可以许多方式实现。例如,该模型可整合至工具的系统软件中。替代地,该模型可独立于工具的系统软件远程地实施,且模型所产生的预测结果可供应至工具的系统软件。例如,为易于模型维护,模型可以在工具的系统软件外部运行。该模型可以根据操作员选择的晶片流,从系统软件接收输入参数。接着,该模型可以计算并预测最佳调度参数值,并且将其发送回系统软件。例如,该模型可以运用于云端中作为软件即服务。
127.当模型整合至工具的系统软件中时,该模型可以根据基于每一工具的工具获取数据,针对在工具上的给定的运行方案产生最佳调度参数。因此,在该实施方案中,模型的预测是基于实际工具数据。该模型也适应于工具之间的差异。该模型可被更新,以调整工具性能漂移。然而,在该实施方案中,对工具本身执行了密集的计算。此外,该工具获取数据可能不足以使模型提供最佳解决方案。可通过将模型与来自工具的成组的数据一起使用并且评估数据组是否足以预测最佳调度参数来确定数据的充足性。
128.当模型与工具分开实施时,模型产生器408可辨识并存储每一工具的最佳配置和运行方案组,并存储该组以进行自动选择。模拟器404可针对工具配置、晶片流类型、配方/wac时间及运行方案的多种组合产生训练数据。模型产生器408可基于训练数据组来辨识产生最佳预测模型的最佳机器学习方法,以产生最佳系统产量。接着,该模型可以用于产生每一工具配置及方案的最佳调度参数组。该模型结果组可编码至用户接口中,以便工具操作员根据工具操作员所选的工具的工具配置及运行方案进行自动调度参数选择。
129.在该实现方案中,对工具执行的计算受到限制。然而,模型产生器408执行广泛的计算,以覆盖多种工具的多种配置和方案。此外,模型的预测是基于模拟数据,而不是多种工具的获取数据。因此,模型性能取决于模拟数据的质量。该模型也可能无法支持所有可能的工具配置和运行方案。此外,该模型可能无法适应于工具之间的差异,且可能无法针对工具性能漂移进行调整。
130.图5a示出了用于产生机器学习辅助模型并且基于使用该模型所产生的调度参数来操作工具的方法500。该方法500可以由图4所示的系统400来执行。例如,系统400的元件402
‑
408中的一或多者可执行方法500的下述步骤中的一或多者。
131.在502,从一或更多个工具接收用于产生并训练模型的数据。在504,接收一或更多个工具的配置和配方数据。在506,使用模拟器(例如,上述参考图4示出并描述的元件406),基于配置和配方数据来产生用于产生并训练模型的额外数据。参考图5b,进一步详细解释模拟器的操作。
132.在508,使用机器学习方法,通过分析从工具和模拟器接收的数据来产生并训练模型。参考图5c,进一步详细解释分析数据的过程。参考图6和7,进一步详细解释模型产生和训练过程。
133.在510,对模型进行测试和验证。参考图8,进一步详细解释模型验证过程。
134.在512,该方法500确定是否满足模型的测试标准。如果不满足测试标准,该方法500就返回502。在514,如果满足测试标准,则运用模型以供使用。该模型整合至工具的系统软件中,或与工具的系统软件分开实现,如上所述。
135.在516,模型从工具的系统软件接收输入,其与将在晶片组上执行的处理有关。在518,基于接收的输入,模型提供最佳调度参数值至用于处理晶片组的工具的系统软件。在520,基于接收到的调度参数值,工具的系统软件调度操作,以处理晶片组。
136.图5b示出了模拟器404的操作,其为模拟器404所执行的方法550。如图5a中504所述,接收该一或更多个工具的配置和配方数据。在图5b中,在552,模拟器404使用工具的硬件配置和配方数据等来模拟工具的处理环境。在554,模拟器404在工具的模拟环境中模拟晶片的处理。在556,模拟器404基于在工具的模拟环境中对晶片的模拟处理来产生额外数据,以产生并训练模型。
137.图5c示出了数据分析器406的操作,其以数据分析器406所执行的方法580形式呈现。如图5a中508所述,通过分析从工具和模拟器接收的数据来产生并训练模型。在图5c中,在582,数据分析器406分析从工具以及从模拟器404收集到的数据。在584,数据分析器406利用用于分析数据的技术来分析数据。
138.在586,数据分析器406基于收集到的数据的分析,检测关于工具的pm、wac时间、等待时间、配方时间及产量的模式。在588,数据分析器406检测上述工具之间的变化以及相同工具的变化。在590,数据分析器406将检测到的模式以及变化提供至模型产生器408,以用于使用机器学习的模型训练中。
139.图6和7更详细地示出了模型产生和训练过程。在图6中,其示出了用于产生模型的方法600。在602,定义模型。在604,训练模型。在606,验证模型。
140.在图7中,其示出了用于产生模型的方法700。在702,模型是通过选择用于深度神经网络的网络拓扑来定义。深度神经网络的示例如图9所示。例如,选择网络拓扑包括选择输入数量、神经元数量及深度神经网络的层数。
141.从704至710,训练模型。在704,模型在训练数据(例如,从工具收集到的数据以及由模拟器所产生的数据)上运行。在706,对照训练数据来检查模型所预测的输出。在708,调整模型参数和/或网络技术,以在模型的预测与实际数据之间产生更好的匹配。在710,确定模型是否满足预定标准。
142.例如,预定标准包括确定模型是否可补偿工具之间的变化以及相同工具的性能漂移,以及模型是否可针对得不到的pm进行优化。此外,预定标准可包括确定模型输出是否确保小的晶片空闲时间(例如,小于2%)及高的制造效率(例如,大于97%)。如果未满足预定标准中的一者,方法700则返回704。在712,在满足预定标准下,该模型通过以来自工具的新数据来测试模型以进行验证。
143.图8进一步详细示出了用于验证模型的方法800。该方法称为k折验证(k
‑
fold validation)方法。在802,用于验证的数据被分成k个分区,其中k为大于1的整数。在804,例示相同的模型。在806,在一分区上训练每一模型,并在其余分区上进行评估。对每一评估分配验证分数。在808,模型的验证分数是模型的k个验证分数的平均值。运用验证分数最高的模型以供使用。
144.其他验证方法可以用于验证模型。例如,可使用n折交叉验证(n
‑
fold cross
‑
validation)方法。在该方法中,全部数据集被分为一个最终测试集和n个其他子集,其中n为大于1的整数。每一模型在除了一个以外的子集上进行训练,以获得n个不同的验证错误率估计。运用验证错误率最低的模型以供使用。
145.图9和10示出了用于使用机器学习技术来产生本文所述模型的深度神经网络的示例。机器学习是用于设计有助于预测的复杂模型及算法的方法。使用机器学习所产生的模型可以产生可靠、可重复的决策及结果,并通过从数据的历史关系以及趋势中学习来发现隐藏的见解。
146.使用基于深度神经网络的模型并使用机器学习来训练模型的目的是为了直接预测因变量(dependent variables),而无需将变量之间的关系转换为数学形式。神经网络模型包含大量并行操作且分层排列的神经元。第一层为输入层,并接收原始输入数据。每一连续层修改来自前一层的输出,并将其发送至下一层。最后一层为输出层,并且产生系统的输出。
147.在输入层中,每一输入节点与一数值相关,该数值可以是任何实数。在每一层中,从输入节点出发的每一连接具有与其有关的权重,该权重也可以是任何实数(请参见图10)。在图9中,其示出了完全连接的神经网络,其中给定层中的每一神经元与下一层中的每一神经元相连。
148.在输入层中,神经元的数量等于数据集中的特征(列)的数量。输出层可具有多个连续输出。输入与输出层之间的层为隐藏层。隐藏层的数量可以是一或更多(一个隐藏层对大多数应用可能就足够了)。没有隐藏层的神经网络可表示线性可分函数(linear separable function)或决策。具有一个隐藏层的神经网络可执行从一有限空间到另一有限空间的连续映射。具有两个隐藏层的神经网络可以使任何光滑映射接近于任何精确度。
149.可以将神经元的数量优化。在训练开始时,网络配置很可能会有过多的节点。在训练期间,可从网络中删除不会明显影响网络性能的节点。例如,可删除(修剪)训练后权重接近零的节点。神经元的数量可能会导致不足拟合(无法充分获取数据集中的信号)或过度拟合(不足以训练所有神经元的信息;网络在训练数据集上执行良好,但在测试数据集上执行不佳)。
150.多种方法可以用于测量模型的性能。例如,均方根误差(rmse)测量观测值与模型预测之间的平均差距。决定系数(r2)测量观测值与预测结果之间的相关性(而非准确性)。
如果数据有大的差异,则该方法不可靠。其他性能测量包括不可约噪声(irreducible noise)、模型偏差(model bias)及模型方差(model variance)。高偏差表示该模型无法获取预测算子(predictors)与结果之间的真实关系。模型方差可表示模型是否不稳定(数据中的微小扰动会显著改变模型拟合)。
151.图11示出了高偏差与高方差的示例。高方差可表示过度拟合。可使用多种方法防止过度拟合。例如,可使用正规化(regularization),其中大的权重可使用其平方值(l2罚分)或绝对值(l1罚分)的罚分(penalty)或约束(constraint)进行罚分。另外,可使用更多数据。此外,可使用修剪(删除近乎零权重因子的神经元)和/或装袋(bagging)(在训练数据的不同子集上训练模型),以防止过度拟合。
152.图12示出了使用离散事件模拟器来训练强化学习模型的系统1200。例如,上述系统400所产生的模型可利用如下所述使用系统1200的强化学习来进一步训练。系统1200包括离散事件模拟器1202和强化学习模型1204。离散事件模拟器1202与工具的系统软件(例如,图1所示的工具100的控制器138,其执行该工具的系统软件)和强化学习模型1204(例如,图4所示的系统400所产生的模型)通信。
153.在系统1200中,所有元件138、1202和1204可以由单一计算机实现。元件138、1202和1204中的每一者可以由分开的计算机实现。元件138、1202和1204中的一或多者可以由分开的计算机实现。换言之,元件138、1202和1204可以使用一或更多个计算装置来实施。
154.每一计算装置可以包括一或更多硬件处理器(例如,cpu)。每一计算装置可包括存储器,其存储对应于以下参考图13示出并描述的方法的指令。计算装置的硬件处理器执行存储于计算装置的存储器中的指令。
155.元件138、1202和1204中的一或多者可通过一或更多网络通信地互连。例如,网络可包括lan、wan、因特网、基于云端的网络系统或任何其他分布式通信系统(例如,基于客户端
‑
服务器架构的网络系统)。
156.此外,元件1202与1204可以与图4所示的系统400(例如,与模型产生器408)整合。换言之,系统1200可以与系统400整合。
157.如上所述,在一些工具中,系统软件中的调度器可以使用一组调度规则及评分系统来作出调度决策。然而,随着工具的系统配置、运行方案和调度限制的复杂性增加,调度决策方案的复杂性也随之增加,其因而需要更多开发工作,以实现并维持最佳的系统产量。
158.调度器的调度规则和评分系统可以用神经网络模型1204代替。该模型1204可以使用离散事件模拟器1200和强化学习来训练,以自探索并记忆工具的给定状态的最佳调度决策。这使得能实现并维持工具的最佳产量性能。
159.如下参考图13进一步详细解释,自探索过程使用离散事件模拟器1202,以自动努力找出以最佳产量性能来操作系统的最佳可能方式(例如,找出通过工具移动晶片的最佳路径)。通过在工具上运行自训练过程,可针对特定工具配置、晶片处理方案和该工具特有的限制使该神经网络模型1204最佳化。
160.离散事件模拟器1202是快速模拟器。例如,离散事件模拟器1202可在少于一分钟时间内模拟花费约一小时的晶片处理序列。离散事件模拟器1202可模拟1级与2级晶片处理序列以及在pm中运行wac。离散事件模拟器1202包括基于内置http服务器的应用程序编程接口(api),以利于离散事件模拟器1202与模型1204之间的信息交换。离散事件模拟器1202
经由api以json格式输出调度周期信息。模型1204处理json文件,以选择下一个操作,其通过api返回离散事件模拟器1202。
161.另外,模型1204包括深度神经网络,其使用强化学习方法进行训练,如下参考图13进一步详细解释。强化学习涉及代理、一组状态s及每一状态的一组行动a。通过从该组a执行行动“a”,代理可以在状态间转换。在特定状态下执行行动会为代理提供奖励(数字分数)。代理的目标是将总(未来)奖励最大化。代理通过将可以从未来状态获得的最大奖励添加至实现其当前状态的奖励中来实现目标,其通过潜在的未来奖励有效地影响其当前行动。该潜在奖励是从当前状态开始的所有未来步骤的奖励的期望值的加权总和。
162.例如,模型1204所使用的强化学习方法可以包括q学习。q学习是用于机器学习的强化学习方法。q学习的目标是学习可通知代理在何种情况下采取何种行动的策略。q学习可以处理随机转换以及奖励问题,而无需适应(adaptation)。q学习为任何有限马可夫决策过程(fmdp)找到最佳策略。q学习从当前状态开始,在所有连续步骤中使总奖励的期望值最大化。
163.图13示出了使用离散事件模拟器1202来训练强化学习模型1204的方法1300。方法1300可以由图12所示的系统1200来执行。例如,系统1200的元件138、1202和1204中的一或多者可执行方法1300的下述步骤中的一或多者。
164.在1302,离散事件模拟器1202从工具(例如,图1所示的工具100)接收数据。例如,离散事件模拟器1202从在工具100的系统控制器138上运行的系统软件,接收表示工具的当前状态的数据。例如,工具的状态信息可以包括晶片的处理状态中的工具资源(例如,pm、气锁等)的状态。
165.在1304,离散事件模拟器1202产生所有可能的下一调度级操作组,其可以由该工具执行以转换至下一状态。在1306,离散事件模拟器1202将该下一调度级操作组输出至模型1204。在1308,模型1204选择最佳的下一操作进行调度,从而将提供最佳系统性能。在1310,模型1204针对该工具状态记忆该最佳下一操作以进行调度。在1312,离散事件模拟器1202执行该最佳下一操作以模拟下一状态。
166.在1314,离散事件模拟器1202确定是否达到最终状态。离散事件模拟器1202重复步骤1304
‑
1312,直到达到最终状态。在1316,在达到最终状态之后,模型1204的强化训练完成。在1318,当实际晶片处理期间工具中出现该特定状态时,模型1204使用针对每一状态的该被记忆的最佳下一操作。如此一来,使用模型1204,当从一状态转换至另一状态时,该工具始终选择通过工具移动晶片的最佳路径,以获得最佳产量效能。
167.因此,系统1200与系统400一起提供智能机器学习辅助调度器。该智能调度器使用自学习过程来训练神经网络模型,以对给定的系统状态作出最佳调度决策。这些决策有助于实现并且维持该工具在特定于半导体制造商的运行方案和调度限制下处于最佳的产量条件。例如,对于每一配方,智能调度器可以确保晶片空闲时间可以小于总处理时间的2%,制造效率(实际周期时间/理论周期时间)可以大于97%。
168.另外,为了改善用于多个并行材料沉积(例如,多层电镀)处理的工具中所使用的调度器调整的准确性,本发明提出了使用机器学习进行训练的基于嵌套神经网络的模型。具体地,如下文详细解释的,基于嵌套神经网络的模型最初是使用模拟数据进行设计以及离线训练,接着再使用实际工具数据进行在线训练,以预测晶片的路线安排途径以及调度。
该模型可以实现最高的工具/机群利用率、最短等待时间以及最快产量。
169.目前,由于用于并行配方的调度器规则的动态性质,该调度通常有以下问题。调整(pacing)是预测调度器行为(例如晶片路线安排)并决定何时将下一组晶片(通常是一对晶片)发送至工具中以进行处理(例如镀覆)的能力。有时,调度器行为无法被准确地预测。因此,晶片可能太迟或太早分配至工具中。太晚分配晶片降低工具的产量,而太早分配晶片则因增加晶片等待时间(导致晶片干掉)而降低晶片产率(yield)。因此,调度器需准确地预测何时将晶片送至工具中,以实现最大的产量和产率。
170.具体地,工具通常使用两个机械手用于晶片转移:前端(fe)机械手将一对晶片转移至工具中,后端(be)机械手将一对晶片从工具中的一处理模块转移至工具中的另一处理模块。可以在工具的一或更多处理模块中对晶片执行相同或不同处理。此两机械手的调度需结合处理模块的可用性来进行协调。一旦晶片进入工具,即需在正确的时间以正确的顺序有可用的处理模块。否则,所述晶片必须等待,直到下一处理模块(所述晶片被安排到该处理模块)变成可用为止,这可能会导致晶片变干,因而降低产率。
171.复杂调度方案的额外挑战是,不同处理的处理时间可能变化很广(例如,从一处理的几分钟到另一处理的近一小时)。例如,简单的配方可包括处理具有单层的晶片。在此情况下,进入工具的晶片将首先转移至预处理模块,接着转移至镀覆模块,然后再转移至后处理模块,随后晶片离开工具。对于两层处理配方,进入工具的晶片将首先转移至预处理模块,接着转移至第一处理模块,再转移至第二处理模块,然后转移至后处理模块,随后晶片离开工具等等。应理解,有更多处理层的配方会有更长的处理时间。
172.然而,对于一些配方而言,工具中会有一些灵活性,其能有利地用于改善机械手调度及晶片路线安排。例如,对于多层处理配方,如果用于n层的处理材料是相同的,且如果有n个可沉积相同处理层的处理模块,则晶片可以在n个处理模块中的任何处理模块之间转移。该路线安排灵活性提供了多于一个的使晶片在n个处理模块之间转移的路线安排途径的机会。然而,知道n个处理模块中的哪个处理模块在何时将是可用的,对协调并调度晶片路线安排是必要的。此外,知道转移机械手的可用性对协调并调度晶片路线安排也是必要的。
173.因此,并行配方存在多种fe/be机械手转移时间(工具之间及工具内模块之间)。对于大多数情况,当前调整方法通常是使用静态fe/be机械手预留时间,而无路线安排途径预测。此外,当前调度方法在晶片等待时间与产量之间面临以下困境:降低fe/be机械手预留时间可提高产量,但可能导致晶片在处理模块中等待更长的时间,而增加fe/be机械手预留时间可将晶片等待时间降至最小,但可能导致每小时晶片数(wph)产量下降(例如,在重布层或rdl配方中)。此外,目前,对于这些工具上启用的不同参数组以及选项而言,程序运行时间预估并非总是准确的。
174.为了解决这些问题,本发明提出了动态调整方法(调度器层神经网络),以基于以下输入来预测晶片路线安排途径和产量:1)工具配置;2)配方结构(例如,并行处理模块、单层/多层等);3)准确的程序运行时间预估(由模块层神经网络基于参数组值和启动/停止选项的输入提供);4)路线安排途径上每一处理模块的状态(例如,在线/离线、前往处理模块的晶片数、剩余处理时间、服务程序之前剩余的时间等);5)可以为一群工具添加以在工具之间进行批分配优化的第三层神经网络。
175.所提出的动态调度器调整方法使用基于嵌套神经网络的模型,其利用机器学习来训练,以解决晶片处理以及晶片/批分配与路线安排(在模块、工具及机群级别)期间的动态晶片调度问题。最初,模拟被用于产生数据,以训练并且测试神经网络。因此,模拟需要准确,其需准确的程序运行时间预估。神经网络层被用于准确预测程序运行时间。在该层中,每一处理模块使用一神经网络,以预测程序运行时间。此外,每一机械手使用一神经网络,以预测每一机械手的转移时间。
176.该方法采用使用模拟的离线学习以及使用实时工具数据的在线学习两者。离线学习是基于模拟器或工具上所收集的数据,以将生成期间的计算复杂性降至最低。在晶片/批分配之前,将离线训练期间为神经网络所确定的权重应用于调度器调整算法。接着,在线学习被用于基于实时数据来动态调整神经网络。
177.因此,在所提出的方法中,用于调度器调整的模型是使用嵌套神经网络或其他机器学习算法来建立的。该模型最初是利用模拟进行离线建立、训练和测试。随后,该模型通过渐进地使用来自工具的数据流而进一步在实际工具上就地不断地进行精炼及训练,以对模型作进一步调节,其反映特定于工具及特定于配方的机械手转移时间并补偿任何处理漂移。就地训练也针对任何配方改变和/或工具硬件改变来调节模型。
178.使用嵌套神经网络的动态调度器调整方法改善并行配方(有多层材料沉积与等待时间限制)的工具/机群产量和利用率,并且防止晶片干燥的问题。该方法可以推荐配方/晶片分配组合,并且具有最大的工具利用率。该方法还可以预测涉及前端机械手与后端机械手以及晶片对准器的路线安排途径、处理模块的入站途径、处理模块之间的途径以及从处理到出站模块的途径。另外,该方法可针对给定应用推荐最佳的工具硬件配置。
179.动态调度器是阶段式设计、开发和实现的。第一阶段包括如下离线训练单一神经网络。模拟器被用于利用实际工具中的实际转移时间来模拟实际工具中可能可行的多种调度方案和晶片路线安排途径。该模拟器基于不同工具的硬件配置以及基于可用于处理晶片的工具中的各种处理来执行这些模拟。在循环模式下,基于模拟器中的测试方案,模拟晶片周期,以收集大量数据集。神经网络是使用机器学习进行离线训练。计算出的权重(由模拟器产生以将晶片调度和路线安排优化)以及神经网络输入接着被供应至调度器调度算法中,并且在相同的等待时间内观察到产量改善。
180.在第二阶段中,如下针对一群工具中的一工具来离线训练嵌套神经网络。在模型的初始层中,训练模块级神经网络(即,用于处理模块的神经网络),以预测不同处理的程序运行时间。在同一层中,对工具中每一机械手的一神经网络进行训练,以预测不同处理的转移时间。在模型的后续层中,将来自初始层的神经网络的输出(即,程序运行时间以及转移时间的预测)输入至包括调度器级神经网络的下一层。
181.将调度器级神经网络的输入扩展至其他工具配置、配方类型的组合、处理时间、将在晶片上处理的多层、调度器模式等。与模块级神经网络耦合(即嵌套),具有扩展输入的调度器级神经网络为最佳产品/配方/晶片组合提供建议,以实现最高工具/机群利用率,从而降低工具的持有成本。即,基于嵌套神经网络的动态调度器(其利用不同工具硬件配置和不同配方类型进行训练)现在可以对一或多个给定配方建议最佳的工具硬件配置。可仅利用基于模拟器的训练来提供这种建议。
182.第三阶段包括在线实时且无监督学习。使用机器学习的在线连续神经网络训练是
基于一工具或一群工具的实际生产数据。在线训练被用于动态调整如上述利用模拟器进行离线训练的神经网络输入的权重。由于处理配方和/或硬件可能会改变,因此需连续(即不间断)训练。当发生这种改变时,模型需要适应这些改变,其可通过连续训练来实现。因此,动态调度器从有监督进展至无监督的机器学习,并发展出从错误中学习并在下一次作出更好的经训练预估的能力。
183.由于训练的连续性质,工具所产生的数据被自动标记,以使得能渐进训练。即,在当前处理中处理一组晶片之后,来自当前处理的数据被自动标记,使得这些数据可以补充或者替代先前处理中的对应数据以进行渐进学习。动态调度器的这些以及其他方面将在下文进一步详细描述。
184.如参考图14
‑
15b所使用的,等待时间是在处理模块中完成晶片处理之后晶片必须等待的时间量,直到可以在下一处理模块中开始晶片处理为止。等待时间发生在下一处理模块尚未准备好处理晶片时(例如,由于下一处理模块尚未完成并仍在处理其他晶片)。程序运行时间或处理时间是处理模块完成晶片处理所花费的时间量。机械手的转移时间是机械手将晶片从a点移至b点(例如,从一处理模块到另一处理模块、或从气锁到处理模块、以及从工具的装载站到气锁)所花费的时间量。
185.图14示出了使用离线模拟器1404以及来自工具1406(例如,图16所示的工具1600)的在线实时数据来训练具有嵌套神经网络的模型1402以调度并且调整工具1406中晶片处理的系统1400。模型1402包括多个模块级神经网络以及调度器级神经网络。该多个模块级神经网络包括用于工具1406中每一处理模块(例如,图16所示的处理模块1602)的一神经网络以及用于工具1406中每一机械手(例如,用于图16所示的机械手1610和1614)的一神经网络。这些神经网络被显示为1410
‑
1、...和1410
‑
n,其中n为大于1的整数,其可统称为神经网络1410。神经网络1410输出处理模块(例如,图16所示的处理模块1602)的程序运行时间的预测及机械手(例如,图16所示的机械手1610及1614)转移时间的预测。
186.调度器级神经网络示为1412,并且接收神经网络1410的输出作为输入。调度器级神经网络1412对工具内处理模块之间的晶片的路线安排进行调度,并且输出关于何时将下一对晶片转移至工具以进行处理的预测。神经网络1410和调度器级神经网络1412在其最初于模拟器1404上进行训练期间,且随后在工具1406上实际使用并继续训练期间,输出其相应的预测(例如,当由图16所示的系统控制器1616实施或与其整合时)。
187.仅作为示例,模拟器1404可以使用计算装置来实现,所述计算装置例如包括一或更多硬件处理器(例如,cpu)以及存储一或更多个计算机程序(其在计算机上模拟工具(如工具1406)的操作及处理环境)的一或更多个存储器装置的计算机。计算机程序另外包括用于在模拟器1404上产生、训练并且验证模型1402的神经网络1410以及调度器级神经网络1412的指令,如下文参考图15a及15b所解释的。该一或更多个硬件处理器执行该一或更多个计算机程序。
188.模拟器1404和工具1406可以通过一或更多个网络通信地互连。例如,网络可以包括lan、wan、因特网、基于云端的网络系统或任何其他分布式通信系统(例如,基于客户端
‑
服务器架构的网络系统)。
189.例如,模拟器1404可以利用图18所示的晶片厂数据收集系统1800,从工具1406收集/接收数据。尽管在图14中仅示出了一个工具,但可以从多于一个的工具收集/接收数据。
该一或更多个工具可以位于相同客户位置。该一或更多个工具可以位于同一客户的不同位置。该一或更多个工具可位于不同客户的位置。从工具收集到的数据不包括客户的私有和机密数据,但包括可以用于产生并训练模型的所有其他操作数据。
190.仅作为示例,工具1406(数据从工具1406收集)可以执行多个并行的材料沉积(例如镀覆)处理,并且可以具有以下配置。该工具可以包括多达两个平台以及两个机械手,每一平台包括多个处理模块。例如,多个处理模块可以包括一个预处理模块、一个后处理模块以及四个用于执行镀覆处理的处理模块。该工具可以进一步包括调度器,以控制该工具中的晶片处理。这些处理可包括单层镀覆或多层镀覆。
191.模拟器1404模拟工具配置并且模拟工具中晶片的处理。模拟器1404包括利用机器学习的一或更多系统,以使用由模拟器1404通过模拟晶片处理而产生的数据来产生、训练并且验证模型1402的神经网络1410以及1412。使用经训练的模型1402,工具的调度器可以对晶片的处理进行调度,并且提供最佳产量和等待时间。经训练的模型1402也可以推荐将用于给定应用的工具的最佳硬件配置。
192.图15a和15b示出了使用离线模拟器以及在线实时工具数据来训练具有嵌套神经网络的模型以调度并且调整工具中的晶片处理的方法1500。例如,图14所示的系统1400的模拟器1404和工具1406的系统控制器(例如,图16所示的元件1616)中的一或多者可执行方法1500的以下步骤中的一或多者。
193.在1502,方法1500获得有关工具的硬件配置以及将在工具中的晶片上执行的处理(例如,多层镀覆)的配方的数据。在1504,使用模拟器,基于所获得的数据,方法1500模拟用于处理晶片的多种路线安排和调度方案。在1506,使用模拟器,方法1500使用多种路线安排和调度方案来模拟晶片处理。
194.在1508,方法1500从使用模拟器执行的模拟晶片处理中收集数据。在1510,使用所收集的数据,方法1500设计并且训练多个神经网络。该多个网络包括用于工具中每一处理模块的一个神经网络、用于工具中每一机械手的一个神经网络、以及用于工具所使用的调度器(以安排晶片在工具中的路线,并对何时在工具中处理下一组晶片进行调度)的一个神经网络。例如,用于产生并且训练神经网络的方法可以类似于参考图6
‑
11所述的方法。
195.在1512,该方法1500使用各个神经网络,预测每一处理模块的程序运行时间,并且预测机械手的转移时间。在1514,该方法1500使用从工具获得的数据来验证用于处理模块和机械手的神经网络。
196.在1516,该方法1500确定是否成功验证用于处理模块和机械手的神经网络。例如,用于验证神经网络的方法可类似于参考图6
‑
11所述的方法。例如,验证标准可基于神经网络的收敛(convergence)特性能够如何准确地预测程序运行时间及机械手转移时间。若未成功验证用于处理模块及机械手的神经网络,该方法1500则返回1508以进一步训练。
197.在1518,如果成功地验证用于处理模块和机械手的神经网络,则利用该模拟器,该方法1500将由用于使产量和等待时间优化的神经网络所产生的预测时间和权重输入至调度器级神经网络中。在1520,使用调度器级神经网络,该方法1500预测晶片路线安排和调度数据,其包括何时在工具中对下一组晶片的处理进行调度。
198.在1524,用于验证调度器级神经网络的方法可类似于参考图6
‑
11所述的方法。例如,用于验证的标准可基于调度器级神经网络能够如何准确地预测晶片路线安排和调度。
如果未成功验证调度器级神经网络,则该方法1500返回1518以使用模拟器进一步训练调度器级神经网络。
199.在1526,如果成功验证调度器级神经网络,则包括用于处理模块、机械手和调度器的所有神经网络的模型整合至工具的控制器中(例如,图16中所示的元件1616)。该模型现在可以预测程序运行时间、机械手转移时间以及工具上的晶片路线安排和调度。
200.在1528,该模型继续利用来自工具的实际生产数据来进行渐进式在线训练(即,在工具上原位训练)。自动标记的数据(来自当前晶片组的处理)除了来自先前晶片组的处理的对应数据之外也被使用或代替该对应数据被使用以在工具上渐进地并且连续地训练模型。
201.图16示出了包括多个处理模块1602的工具1600的示例。例如,工具1600可包括下平台和上平台。每一平台可以包括四个处理模块1602,使得工具1600可以包括总共八个处理模块1602。替代地,每一平台可包括所示的八个处理模块1602(仅示出一个平台),使得工具1600可以包括总共十六个处理模块1602。例如,处理模块1602可以包括电镀槽(例如,见图17)。另外,每一平台也可以包括多个预处理和后处理模块1604。除了电镀之外,工具1600可执行旋转清洗、旋转干燥、湿式蚀刻、预湿以及预化学处理、无电沉积、还原、退火、光致抗蚀剂剥离、表面预活化等。
202.多个衬底1606通过前开式晶片传送盒(foup)1608被馈送至工具1600中。前端机械手1610将衬底1606从foup 1608传送至主轴1612,接着传送至预处理模块1604中的一者。在预处理之后,后端机械手1614将衬底1606从预处理模块1604传送至一或更多处理模块1602以进行电镀。之后,后端机械手1614将衬底1606传送至后处理模块1604中的一者。
203.工具1600进一步包括系统控制器1616,其控制前端与后端机械手1610、1614以及在处理模块1602、1604中执行的处理。该控制器1616使用如上所述的经训练的模型1402以及动态调度器调整方法来调度并控制衬底1606的处理。
204.图17示出了处理模块1602的示例。例如,处理模块1602包括电镀槽1700。电镀槽1700包括在分隔的阳极室(sac)1704中的阳极1702。sac1704通过膜与电镀槽1700中的其余部分分隔开。sac1704包括第一液体,其化学性质不同于电镀槽1700中的其余部分中的第二液体。
205.电镀槽1700还包括高电阻虚拟阳极(hrva)1706(安装组件未示出)。在电镀期间,当晶片从电镀槽1700的顶部下降至电镀槽1700中时,hrva1706将第二液体的流动引向晶片的一部分(未显示)。主槽(贮存器)1708通过泵1710以及过滤器1712,将第二液体供应至电镀槽1700中。塔1714使用泵1716,用第一液体填充sac 1704。处理模块1602可以包括任何其他类型的电镀槽。
206.图18示出了晶片厂数据收集系统1800的示例。例如,系统1800包括主计算机1802、数据收集器1804以及监测计算机1806,其使用一或更多个工具(例如工具1600)连接至半导体制造厂中的厂局域网络(lan)1808。主计算机1802与一或更多工具(例如,工具1600)通信。主计算机1802被操作员用来向工具1600发送命令、提供配方等。
207.数据收集器1804从工具1600接收各种类型的数据,而不会干扰主计算机1802与工具1600的通信。监测计算机1806用于查看并且监测工具性能。监测计算机1806以图形方式示出工具设定并且读取各种工具参数的值。监测计算机1806被用于对工具1600的问题进行
故障排除。主计算机1802与数据收集器1804以及监测计算机1806通信。
208.该系统1800进一步包括经由设备lan1812连接至工具1600的服务器1810。服务器1810通过厂lan1808与主计算机1802通信。服务器1810从工具1600收集数据,并且供应数据至主计算机1802。一或更多用户接口(ui)计算机1814位于工具1600的与工具1600装载器侧相对的一侧。装载器侧为100级清洁,而操作员操作工具1600的ui计算机侧为1000级清洁。ui计算机1814连接至设备lan1812。监测计算机1816通过设备lan1812连接至工具1600。监测计算机1816监测工具1600,并通过厂lan1808与监测计算机1806通信。
209.工具1600的系统控制器1818(例如,系统控制器1616)控制工具1600。多个模块控制器1820控制各个处理模块1602、1604。多个输入/输出(i/o)控制器1822控制处理模块1602、1604的各个操作。系统控制器1818也与i/o控制器1822中的一或多者通信(例如,以控制机械手1610、1614;以及以控制除工具的处理模块1602、1604以外的特征)。各种开关1824被用于访问适当的i/o控制器1818。
210.以上参考图14
‑
17所述的功能和操作可以由系统控制器1818、监测计算机1816或两者执行。附加地或替代地,参考图18所述的其他计算装置也可执行以上参考图14
‑
17所述的至少一些功能及操作。
211.前面的描述本质上仅仅是说明性的,并且绝不旨在限制本公开、其应用或用途。本公开的广泛教导可以以各种形式实现。因此,虽然本公开包括特定示例,但是本公开的真实范围不应当被如此限制,因为在研究附图、说明书和所附权利要求时,其他修改将变得显而易见。
212.应当理解,在不改变本公开的原理的情况下,方法中的一个或多个步骤可以以不同的顺序(或同时地)执行。此外,虽然每个实施方案在上面被描述为具有某些特征,但是相对于本公开的任何实施方案描述的那些特征中的任何一个或多个,可以在任何其它实施方案的特征中实现和/或与任何其它实施方案的特征组合,即使该组合没有明确描述。换句话说,所描述的实施方案不是相互排斥的,并且一个或多个实施方案彼此的置换保持在本公开的范围内。
213.使用各种术语来描述元件之间(例如,模块之间、电路元件之间、半导体层之间等)的空间和功能关系,各种术语包括“连接”、“接合”、“耦合”、“相邻”、“紧挨”、“在...顶部”、“在...上面”、“在...下面”和“设置”。除非将第一和第二元件之间的关系明确地描述为“直接”,否则在上述公开中描述这种关系时,该关系可以是直接关系,其中在第一和第二元件之间不存在其它中间元件,但是也可以是间接关系,其中在第一和第二元件之间(在空间上或功能上)存在一个或多个中间元件。如本文所使用的,短语“a、b和c中的至少一个”应当被解释为意味着使用非排他性逻辑或(or)的逻辑(a或b或c),并且不应被解释为表示“a中的至少一个、b中的至少一个和c中的至少一个”。
214.在一些实现方式中,控制器是系统的一部分,该系统可以是上述示例的一部分。这样的系统可以包括半导体处理设备,半导体处理设备包括一个或多个处理工具、一个或多个室、用于处理的一个或多个平台、和/或特定处理部件(晶片基座、气体流系统等)。这些系统可以与用于在半导体晶片或衬底的处理之前、期间和之后控制它们的操作的电子器件集成。电子器件可以被称为“控制器”,其可以控制一个或多个系统的各种部件或子部件。
215.例如,根据处理要求和/或系统类型,控制器可以被编程以控制本文公开的任何处
理,包括处理气体的输送、温度设置(例如加热和/或冷却)、压力设置、真空设置、功率设置、射频(rf)产生器设置、rf匹配电路设置、频率设置、流率设置、流体输送设置、位置和操作设置、晶片转移进出工具和其他转移工具和/或与具体系统连接或通过接口连接的装载锁。
216.概括地说,控制器可以定义为电子器件,电子器件具有接收指令、发出指令、控制操作、启用清洁操作、启用端点测量等的各种集成电路、逻辑、存储器和/或软件。集成电路可以包括存储程序指令的固件形式的芯片、数字信号处理器(dsp)、定义为专用集成电路(asic)的芯片、和/或一个或多个微处理器、或执行程序指令(例如,软件)的微控制器。
217.程序指令可以是以各种单独设置(或程序文件)的形式发送到控制器的指令,单独设置(或程序文件)定义用于在半导体晶片或系统上或针对半导体晶片或系统执行特定处理的操作参数。在一些实施方案中,操作参数可以是由工艺工程师定义的配方的一部分,以在一或多个(种)层、材料、金属、氧化物、硅、二氧化硅、表面、电路和/或晶片的管芯的制造期间完成一个或多个处理步骤。
218.在一些实现方式中,控制器可以是与系统集成、耦合到系统、以其它方式联网到系统或其组合的计算机的一部分或耦合到该计算机。例如,控制器可以在“云”中或是晶片厂(fab)主机系统的全部或一部分,其可以允许对晶片处理的远程访问。计算机可以实现对系统的远程访问以监视制造操作的当前进展、检查过去制造操作的历史、检查多个制造操作的趋势或性能标准,改变当前处理的参数、设置处理步骤以跟随当前的处理、或者开始新的处理。
219.在一些示例中,远程计算机(例如服务器)可以通过网络(其可以包括本地网络或因特网)向系统提供处理配方。远程计算机可以包括使得能够输入或编程参数和/或设置的用户界面,然后将该参数和/或设置从远程计算机发送到系统。在一些示例中,控制器接收数据形式的指令,其指定在一个或多个操作期间要执行的每个处理步骤的参数。应当理解,参数可以特定于要执行的处理的类型和工具的类型,控制器被配置为与该工具接口或控制该工具。
220.因此,如上所述,控制器可以是例如通过包括联网在一起并朝着共同目的(例如本文所述的处理和控制)工作的一个或多个分立的控制器而呈分布式。用于这种目的的分布式控制器的示例是在与远程(例如在平台级或作为远程计算机的一部分)的一个或多个集成电路通信的室上的一个或多个集成电路,其组合以控制在室上的处理。
221.示例系统可以包括但不限于等离子体蚀刻室或模块、沉积室或模块、旋转漂洗室或模块、金属电镀室或模块、清洁室或模块、倒角边缘蚀刻室或模块、物理气相沉积(pvd)室或模块、化学气相沉积(cvd)室或模块、原子层沉积(ald)室或模块、原子层蚀刻(ale)室或模块、离子注入室或模块、轨道室或模块、以及可以与半导体晶片的制造和/或制备相关联或用于半导体晶片的制造和/或制备的任何其它半导体处理系统。
222.如上所述,根据将由工具执行的一个或多个处理步骤,控制器可以与一个或多个其他工具电路或模块、其它工具部件、群集工具、其他工具接口、相邻工具、邻近工具、位于整个工厂中的工具、主计算机、另一控制器、或在将晶片容器往返半导体制造工厂中的工具位置和/或装载口运输的材料运输中使用的工具通信。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1